
用神经网络逼近正弦函数
我实现了一个简单的神经网络框架,它只支持多层感知器和简单的反向传播。它适用于线性分类和通常的异或问题,但对于正弦函数近似,其结果并不令人满意。
我基本上试着用一个隐藏层来近似正弦函数的一个周期,这个隐藏层由6-10个神经元组成。网络采用双曲正切作为隐层的激活函数,输出采用线性函数。结果仍然是对正弦波的粗略估计,需要很长时间才能计算出来。
我查看了encog作为参考,但即便如此,我仍然无法使它与简单的反向传播(通过切换到弹性传播,它开始变得更好,但仍然比超级光滑的R脚本提供的在这个类似的问题上更糟)。所以我真的想做一些不可能的事吗?不可能用简单的反向传播近似正弦(没有动量,没有动态学习速率)吗?R中神经网络库实际使用的方法是什么?
编辑:我知道,即使使用简单的反向传播(如果您对初始权重非常幸运),也绝对有可能找到一个好的、足够的近似(如果您非常幸运的话),但是我更感兴趣的是,这是否是一种可行的方法。我链接到的R脚本似乎与我的实现或者甚至是encog的弹性传播相比,收敛速度非常快,而且非常健壮(在40个年代中,只有很少的学习样本)。我只是想知道我是否可以做些什么来改进我的反向传播算法以获得同样的性能,还是我需要研究一些更高级的学习方法?
回答 3
Stack Overflow用户
发布于 2017-07-19 17:16:14
使用像TensorFlow这样的神经网络的现代框架可以很容易地实现这一点。
例如,在我的计算机上用每层100个神经元组成的两层神经网络在几秒钟内进行训练,给出了一个很好的近似:
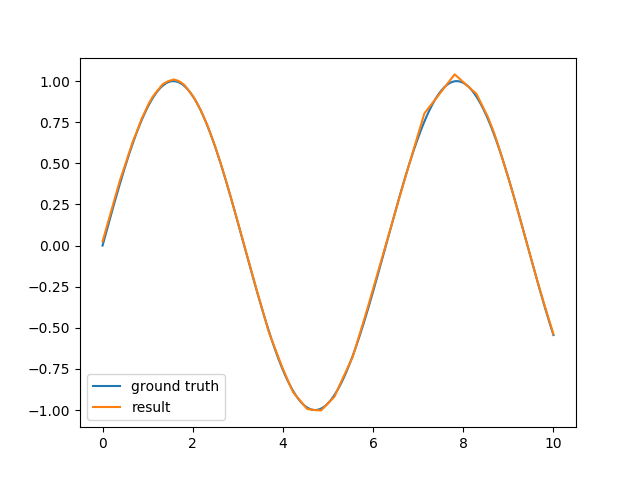
代码也非常简单:
import tensorflow as tf
import numpy as np
with tf.name_scope('placeholders'):
x = tf.placeholder('float', [None, 1])
y = tf.placeholder('float', [None, 1])
with tf.name_scope('neural_network'):
x1 = tf.contrib.layers.fully_connected(x, 100)
x2 = tf.contrib.layers.fully_connected(x1, 100)
result = tf.contrib.layers.fully_connected(x2, 1,
activation_fn=None)
loss = tf.nn.l2_loss(result - y)
with tf.name_scope('optimizer'):
train_op = tf.train.AdamOptimizer().minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# Train the network
for i in range(10000):
xpts = np.random.rand(100) * 10
ypts = np.sin(xpts)
_, loss_result = sess.run([train_op, loss],
feed_dict={x: xpts[:, None],
y: ypts[:, None]})
print('iteration {}, loss={}'.format(i, loss_result))Stack Overflow用户
发布于 2012-12-16 12:28:42
你绝对不是在为不可能的事而努力。神经网络是通用逼近器 --这意味着对于任何函数F和误差E,都存在一些神经网络(只需要一个隐层),可以以小于E的误差近似F。
当然,发现那些网络是完全不同的事情。我能告诉你的就是试错..。以下是基本步骤:
- 将数据分成两部分:训练集(~2/3)和测试集(~1/3)。
- 在培训集中的所有项目上对网络进行培训。
- 在测试集中的所有项目上测试(但不要训练)网络,并记录平均错误。
- 重复步骤2和步骤3,直到您达到最小测试错误(当您的网络开始对培训数据变得非常出色而损害到其他一切时,这会发生在“过度拟合”中),或者直到您的总体错误不再显着地减少(这意味着网络的性能将尽可能好)。
- 如果此时的错误低得可以接受,那么您就完成了。如果没有,你的网络不够复杂,无法处理你训练它的功能;增加更多的隐藏神经元,然后回到开始.
有时,更改激活函数也会产生影响(只是不要使用线性,因为它否定了添加更多层的能力)。但是,再一次,看看什么是最好的,这将是反复的尝试。
希望这会有所帮助(对不起,我不能再多用了)!
PS: --我也知道这是可能的,因为我已经看到了网络近似正弦的人。我想说她没有使用乙状结肠激活功能,但我不能保证我的记忆.
Stack Overflow用户
发布于 2021-05-04 13:51:03
与sklearn.neural_network类似的实现:
from sklearn.neural_network import MLPRegressor
import numpy as np
f = lambda x: [[x_] for x_ in x]
noise_level = 0.1
X_train_ = np.arange(0, 10, 0.2)
real_sin = np.sin(X_train_)
y_train = real_sin+np.random.normal(0,noise_level,len(X_train_))
N = 100
regr = MLPRegressor(hidden_layer_sizes= tuple([N]*5)).fit(f(X_train_), y_train)
predicted_sin = regr.predict(f(X_train_))结果如下所示:
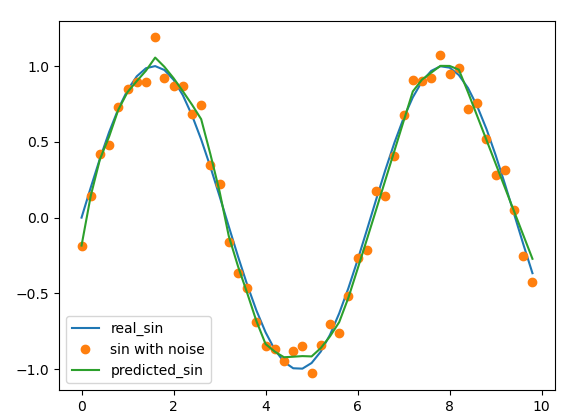
https://stackoverflow.com/questions/13897316
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号