
抓取booking.com时的故障
一开始,我想去每家酒店:
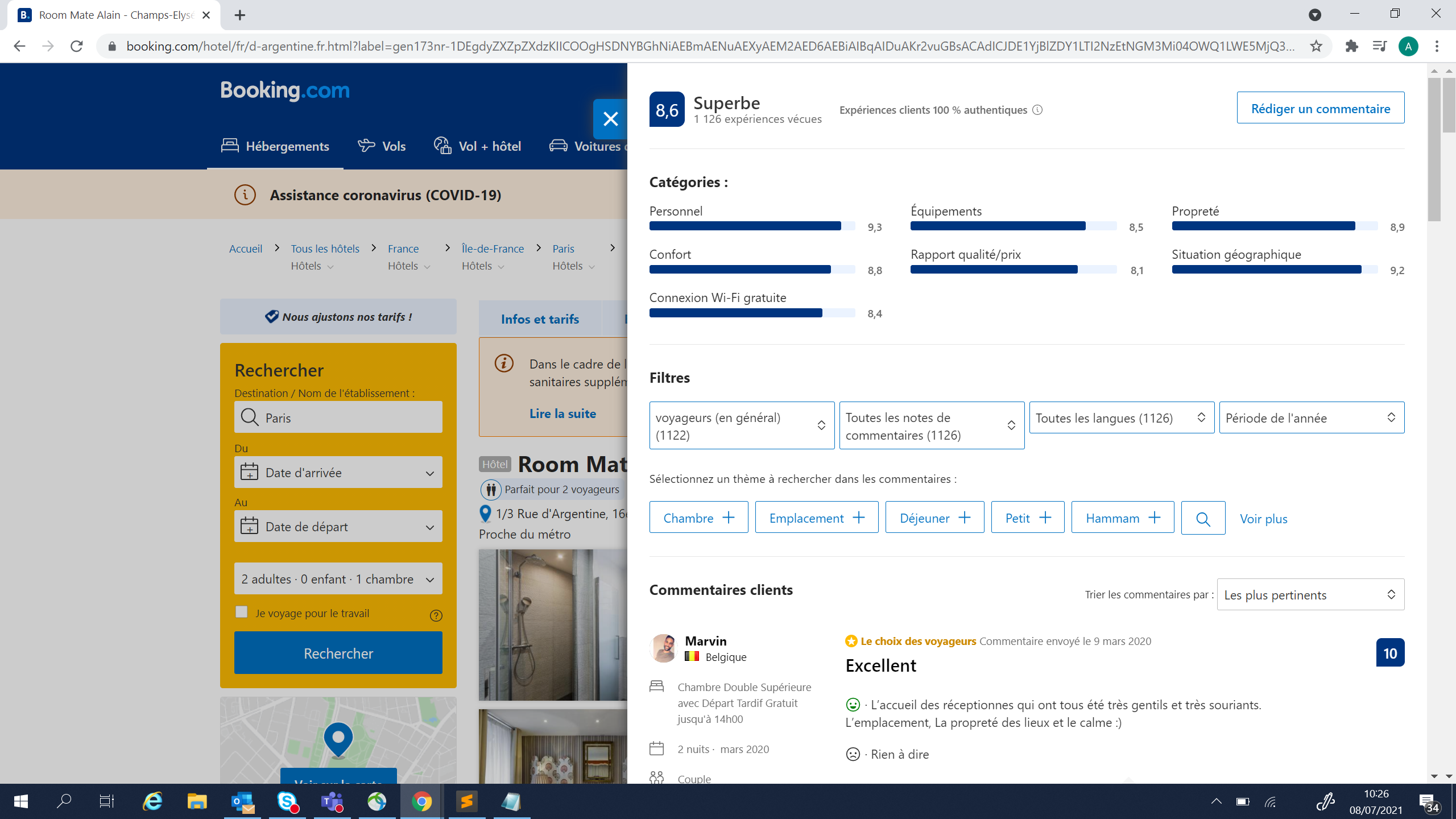
不幸的是,有某种javascript进程来打开这个子页面,而我的脚本不理解他在这里,即使有正确的URL,他也假设他总是在主页中:
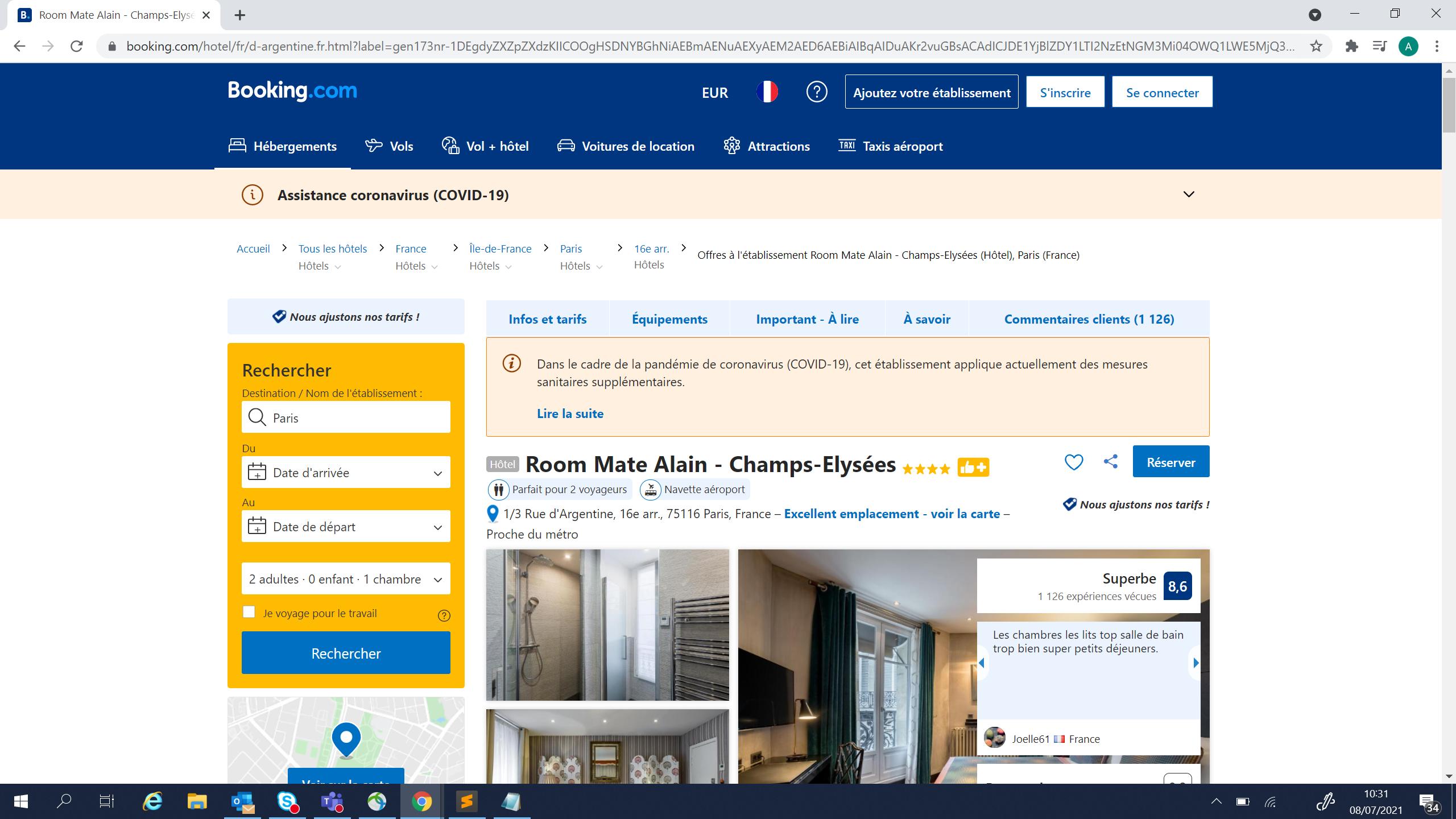
因此,我无法找到如何用这个子页面刮掉所有的评论。因此,在一个成员的帮助下,我们发现我要加载的子页面来自于这个URL:子页链接
我发现我需要更改主网址中的“酒店”一词,并将“酒店特色”改为“酒店特色”,我可以轻松地浏览->的评论。
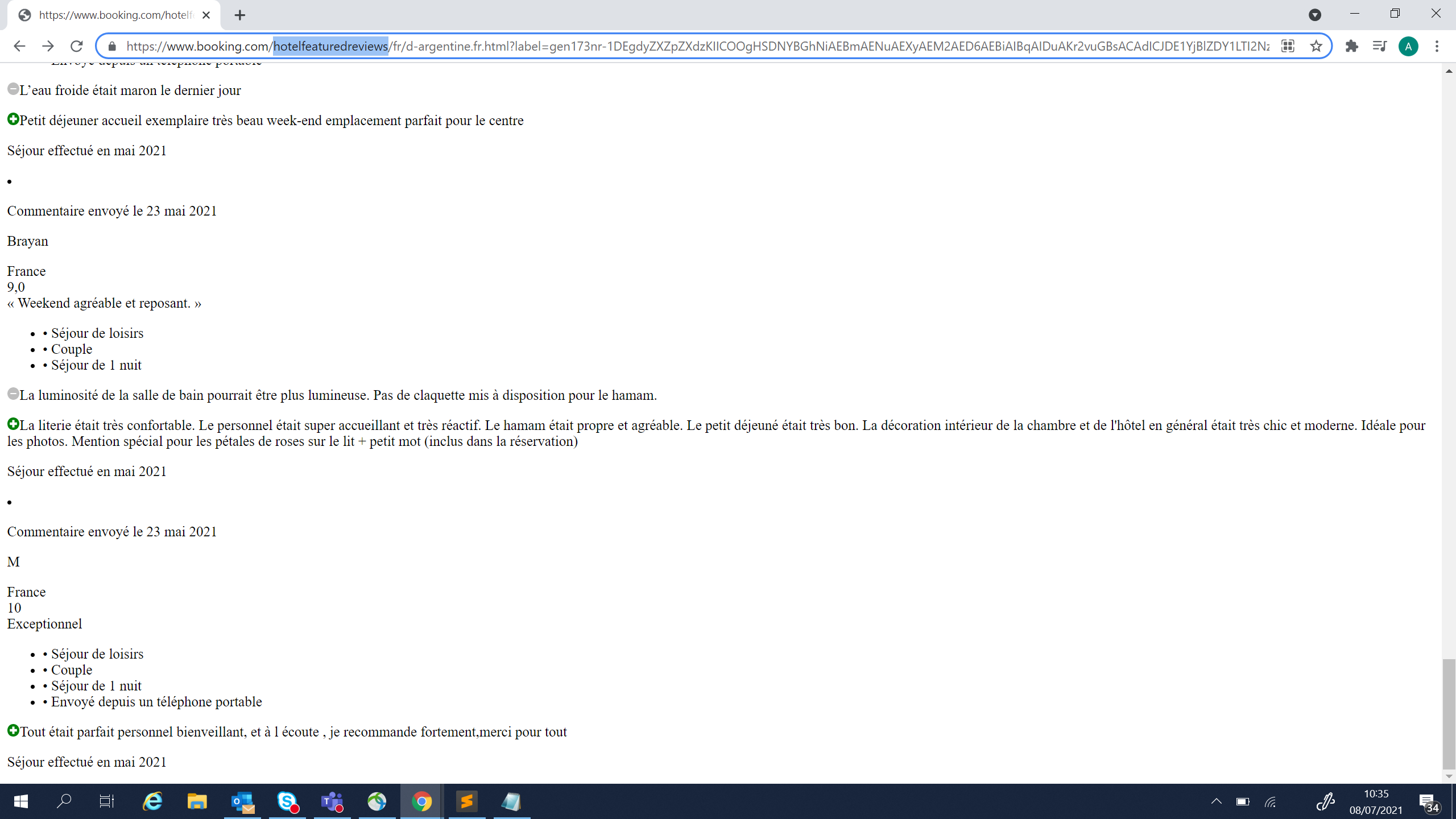
所以我写了这个剧本:
from selenium import webdriver
import time
from selenium.webdriver.support.select import Select
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
from selenium.webdriver.common.keys import Keys
PATH = "driver\chromedriver.exe"
options = webdriver.ChromeOptions()
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1200,900")
options.add_argument('enable-logging')
driver = webdriver.Chrome(options=options, executable_path=PATH)
driver.get('https://www.booking.com/index.fr.html?label=gen173nr-1DCA0oTUIMZWx5c2Vlc3VuaW9uSA1YBGhNiAEBmAENuAEXyAEM2AED6AEB-AECiAIBqAIDuAL_5ZqEBsACAdICJDcxYjgyZmI2LTFlYWQtNGZjOS04Y2U2LTkwNTQyZjI5OWY1YtgCBOACAQ&sid=303509179a2849df63e4d1e5bc1ab1e3&srpvid=e6ae6d1417bd00a1&click_from_logo=1')
driver.maximize_window()
time.sleep(2)
headers= {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'}
cookie = driver.find_element_by_xpath('//*[@id="onetrust-accept-btn-handler"]')
try:
cookie.click()
except:
pass
time.sleep(2)
job_title = driver.find_element_by_xpath('//*[@id="ss"]')
job_title.click()
job_title.send_keys('Paris') #ici on renseigne la ville, attention à la syntaxe
time.sleep(3)
search = driver.find_element_by_xpath('//*[@id="frm"]/div[1]/div[4]/div[2]/button')
search.click()
time.sleep(6)
linksfinal = []
n = 1
for x in range(n): #iterate over n pages
time.sleep(3)
my_elems = driver.find_elements_by_xpath('//a[@class="js-sr-hotel-link hotel_name_link url"]')
links = [my_elem.get_attribute("href") for my_elem in my_elems]
links = [link.replace('\n','') for link in links]
linksfinal = linksfinal + links
time.sleep(3)
next = driver.find_element_by_xpath('//*[@class="bk-icon -iconset-navarrow_right bui-pagination__icon"]')
next.click()
nameshotel = []
for url in linksfinal:
results = requests.get(url, headers = headers)
soup = BeautifulSoup(results.text, "html.parser")
name = soup.find("h2",attrs={"id":"hp_hotel_name"}).text.strip("\n").split("\n")[1]
nameshotel.append(name)
for i in range(len(linksfinal)) :
linksfinal[i] = linksfinal[i].replace('hotel','hotelfeaturedreviews')
for url, name in zip(linksfinal, nameshotel) :
commspos = []
commsneg = []
header = []
notes = []
dates = []
datestostay = []
results = requests.get(url, headers = headers)
soup = BeautifulSoup(results.text, "html.parser")
reviews = soup.find_all('li', class_ = "review_item clearfix")
for review in reviews:
try:
commpos = review.find("p", class_ = "review_pos").text.strip()
except:
commpos = 'NA'
commspos.append(commpos)
try:
commneg = review.find("p", class_ = "review_neg").text.strip()
except:
commneg = 'NA'
commsneg.append(commneg)
head = review.find('div', class_ = 'review_item_header_content').text.strip()
header.append(head)
note = review.find('span', class_ = 'review-score-badge').text.strip()
notes.append(note)
date = review.find('p', class_ = 'review_item_date').text[23:].strip()
dates.append(date)
try:
datestay = review.find('p', class_ = 'review_staydate').text[20:].strip()
datestostay.append(datestay)
except:
datestostay.append('NaN')
data = pd.DataFrame({
'commspos' : commspos,
'commsneg' : commsneg,
'headers' : header,
'notes' : notes,
'dates' : dates,
'datestostay' : datestostay,
})
data.to_csv(f"{name}.csv", sep=';', index=False, encoding = 'utf_8_sig')
#data.to_csv(f"{name} + datetime.now().strftime("_%Y_%m_%d-%I_%M_%S").csv", sep=';', index=False)
time.sleep(3)这个脚本刮掉了我想要的酒店的所有链接,存储在一个列表中,并将所有的“酒店”替换为“酒店特色视图”,并循环遍历所有这些链接,以便为每个酒店刮掉评论。
总之,没有next按钮,而且我也不能刮掉所有的评论。在页面的末尾,在开始的子页面中没有类似的东西,所以我找不到如何用这个技巧转到评论的下一页。
我有点迷茫了,你知道我怎样才能克服这个问题,刮掉我想要的所有评论,控制页面,去任何我想要的评论页面?
对不起,麻烦了,我想说清楚,所以我放了很多细节。
回答 2
Stack Overflow用户
发布于 2021-07-09 12:01:12
你可以这样做:
- 从Hotel中提取以下参数值。您可以很容易地在URL中找到它们。
- cc1 --这是酒店的国家代码。
- 页面名- URL中的酒店名称
- 标签
- 侧边
- 斯皮维德
- 在以下URL中使用这些值。这个URL会给你评论。
- rows=10 -将显示每页10个评论。您可以相应地更改它们。
- offset=0 -指向第一页;偏移量= 10点到第二页,等等。
在上面的URL中使用这些参数之后,您可以刮掉最终的URL并提取所需的任何数据。
例:
Stack Overflow用户
发布于 2021-07-08 13:21:36
回想一下您的子页链接,您会发现包含下一页的div,例如,如果您在第一页,您可以找到第2页:
</div>
<div class="bui-pagination__item ">
<a href="/reviewlist.fr.html?aid=304142;label=gen173nr-1DCAEoggI46AdIM1gEaEaIAQGYAQ24AQfIAQzYAQPoAQGIAgGoAgO4AsXYm4cGwAIB0gIkMDJjN2FmZTQtYTg4YS00NDI5LTlhMDYtNDdmM2IyZWE4Y2Q02AIE4AIB;sid=57b6bff3ca5e1cc8a54e98d7d17ed16a;cc1=es;dist=1;length_of_stay=25;pagename=apartamentos-levante-club;srpvid=a99e5664b05c00da;type=total&;offset=10;rows=10"
class="bui-pagination__link"
data-page-number="2"
>从div中获取href并添加到url:https://www.booking.com/reviewlist.fr.html中。
有了这个链接,您将获得第二个页面链接:
https://www.booking.com/reviewlist.fr.html?aid=304142;label=gen173nr-1DCAEoggI46AdIM1gEaEaIAQGYAQ24AQfIAQzYAQPoAQGIAgGoAgO4AsXYm4cGwAIB0gIkMDJjN2FmZTQtYTg4YS00NDI5LTlhMDYtNDdmM2IyZWE4Y2Q02AIE4AIB;sid=57b6bff3ca5e1cc8a54e98d7d17ed16a;cc1=es;dist=1;length_of_stay=25;pagename=apartamentos-levante-club;srpvid=a99e5664b05c00da;type=total&;offset=10;rows=10"在第二页中,再次获取div,直到最后一页。
https://stackoverflow.com/questions/68298360
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号