
函数使用df.apply或类似的Pandas修改行值。
概述
我正在研究一个数据框架,在这个数据中,df["Pivots"]在1到-1之间交替,而当一个高或低之前已经由一个曲折的指示器识别出来时。
当df["Pivots"]以前(不正确地)被分配给1的值时,我试图在dataframe上用Pandas实现以下内容,并修改相关的行,这标志着一个高的但是另一个行实际上有一个更高的High值。
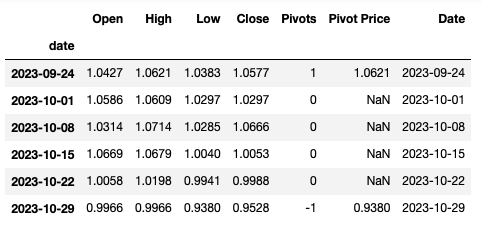
请参阅下面的屏幕截图,以直观地表示数据和所需的输出。
伪码
如果当前行在df["Pivots"]中有a -1,则为
- 。
- rows_between =
df["Pivots"]中的索引<当前行和索引>最后一个枢轴值,它将是一个1
如果当前行中的rows_between.中的df.High > df["Pivot Price"],那么actual_high在rows_between中是df[High].max()
- 从当前行的
df["Pivot Price"]中删除df["Pivots"]& value中的1,并将其添加到行中的df["Pivots"]&df["Pivot Price"],即actual_high
中。
示例
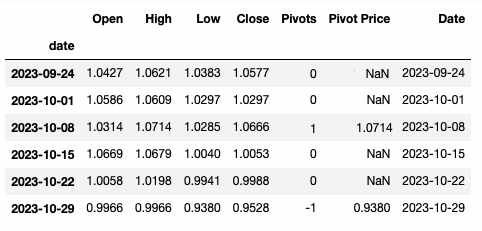
在本例中,行中的df.High 2023-10-08是actual_high,比行2023-09-24中的df["Pivot Price"]要高。
这是原始数据。
这是想要的输出
实际的dataframe将包含许多行,这只是一个最小的、可重复的示例。
码
df.to_dict()
{'Open': {Timestamp('2023-09-24 00:00:00', freq='W-SUN'): 1.0427,
Timestamp('2023-10-01 00:00:00', freq='W-SUN'): 1.0586,
Timestamp('2023-10-08 00:00:00', freq='W-SUN'): 1.0314,
Timestamp('2023-10-15 00:00:00', freq='W-SUN'): 1.0669,
Timestamp('2023-10-22 00:00:00', freq='W-SUN'): 1.0058,
Timestamp('2023-10-29 00:00:00', freq='W-SUN'): 0.9966},
'High': {Timestamp('2023-09-24 00:00:00', freq='W-SUN'): 1.0621,
Timestamp('2023-10-01 00:00:00', freq='W-SUN'): 1.0609,
Timestamp('2023-10-08 00:00:00', freq='W-SUN'): 1.0714,
Timestamp('2023-10-15 00:00:00', freq='W-SUN'): 1.0679,
Timestamp('2023-10-22 00:00:00', freq='W-SUN'): 1.0198,
Timestamp('2023-10-29 00:00:00', freq='W-SUN'): 0.9966},
'Low': {Timestamp('2023-09-24 00:00:00', freq='W-SUN'): 1.0383,
Timestamp('2023-10-01 00:00:00', freq='W-SUN'): 1.0297,
Timestamp('2023-10-08 00:00:00', freq='W-SUN'): 1.0285,
Timestamp('2023-10-15 00:00:00', freq='W-SUN'): 1.004,
Timestamp('2023-10-22 00:00:00', freq='W-SUN'): 0.9941,
Timestamp('2023-10-29 00:00:00', freq='W-SUN'): 0.938},
'Close': {Timestamp('2023-09-24 00:00:00', freq='W-SUN'): 1.0577,
Timestamp('2023-10-01 00:00:00', freq='W-SUN'): 1.0297,
Timestamp('2023-10-08 00:00:00', freq='W-SUN'): 1.0666,
Timestamp('2023-10-15 00:00:00', freq='W-SUN'): 1.0053,
Timestamp('2023-10-22 00:00:00', freq='W-SUN'): 0.9988,
Timestamp('2023-10-29 00:00:00', freq='W-SUN'): 0.9528},
'Pivots': {Timestamp('2023-09-24 00:00:00', freq='W-SUN'): 1,
Timestamp('2023-10-01 00:00:00', freq='W-SUN'): 0,
Timestamp('2023-10-08 00:00:00', freq='W-SUN'): 0,
Timestamp('2023-10-15 00:00:00', freq='W-SUN'): 0,
Timestamp('2023-10-22 00:00:00', freq='W-SUN'): 0,
Timestamp('2023-10-29 00:00:00', freq='W-SUN'): -1},
'Pivot Price': {Timestamp('2023-09-24 00:00:00', freq='W-SUN'): 1.0621,
Timestamp('2023-10-01 00:00:00', freq='W-SUN'): nan,
Timestamp('2023-10-08 00:00:00', freq='W-SUN'): nan,
Timestamp('2023-10-15 00:00:00', freq='W-SUN'): nan,
Timestamp('2023-10-22 00:00:00', freq='W-SUN'): nan,
Timestamp('2023-10-29 00:00:00', freq='W-SUN'): 0.938},
'Date': {Timestamp('2023-09-24 00:00:00', freq='W-SUN'): Timestamp('2023-09-24 00:00:00'),
Timestamp('2023-10-01 00:00:00', freq='W-SUN'): Timestamp('2023-10-01 00:00:00'),
Timestamp('2023-10-08 00:00:00', freq='W-SUN'): Timestamp('2023-10-08 00:00:00'),
Timestamp('2023-10-15 00:00:00', freq='W-SUN'): Timestamp('2023-10-15 00:00:00'),
Timestamp('2023-10-22 00:00:00', freq='W-SUN'): Timestamp('2023-10-22 00:00:00'),
Timestamp('2023-10-29 00:00:00', freq='W-SUN'): Timestamp('2023-10-29 00:00:00')}}作为参考,this是生成这些枢轴的代码。
回答 1
Stack Overflow用户
发布于 2021-03-27 11:14:45
我想不出使用.apply()的简短解决方案,但是有了一些辅助函数,您可以使用以下代码解决这个问题:
import numpy as np
def get_highs_idx(df):
return df[df['Pivots'] == 1].index.tolist()
def get_lows_idx(df):
return df[df['Pivots'] == -1].index.tolist()
def get_previous_high_idx(df, low_idx):
highs_idx = get_highs_idx(df)
for high_idx in reversed(highs_idx):
if high_idx < low_idx:
return high_idx
return None
def reset_pivot(df, old_high_idx, new_high_idx):
df.loc[old_high_idx, 'Pivots'] = 0
df.loc[old_high_idx, 'Pivot Price'] = np.nan
df.loc[new_high_idx, 'Pivots'] = 1
df.loc[new_high_idx, 'Pivot Price'] = df.loc[new_high_idx, 'High']
def correct_highs(df):
lows_idx = get_lows_idx(df)
for low_idx in lows_idx:
high_idx = get_previous_high_idx(df, low_idx)
if high_idx is not None:
new_high_idx = df.loc[high_idx:low_idx, 'High'].idxmax()
if high_idx != new_high_idx:
reset_pivot(df, high_idx, new_high_idx)
correct_highs(df) 代码可能会减少一些,但我认为这种方式更容易读懂。
编辑
在你的评论之后,我在下面添加代码,以修正低点。
def get_previous_low_idx(df, high_idx):
lows_idx= get_lows_idx(df)
for low_idx in reversed(lows_idx):
if low_idx < high_idx:
return low_idx
return None
def reset_low_pivot(df, old_low_idx, new_low_idx):
df.loc[old_low_idx, 'Pivots'] = 0
df.loc[old_low_idx, 'Pivot Price'] = np.nan
df.loc[new_low_idx, 'Pivots'] = -1
df.loc[new_low_idx, 'Pivot Price'] = df.loc[new_low_idx, 'Low']
def correct_lows(df):
highs_idx = get_highs_idx(df)
for high_idx in highs_idx:
low_idx = get_previous_low_idx(df, high_idx)
if low_idx is not None:
new_low_idx = df.loc[low_idx:high_idx, 'Low'].idxmin()
if low_idx != new_low_idx:
reset_low_pivot(df, low_idx, new_low_idx)
correct_lows(df) 我不想影响最初的答案,但为了一致性起见,您可能希望将reset_pivot重命名为reset_high_pivot。
此外,还可以增加一个高级功能:
def correct_pivots(df):
correct_highs(df)
correct_lows(df)https://stackoverflow.com/questions/66797797
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号