
按序列读取文件Python
按序列读取文件Python
提问于 2020-09-01 09:36:31
我在S3桶中有一些文件夹,其中有文件。由于S3存储的数据类似unix系统,因此文件夹号的排序为1,10,11,12,2,3而不是1,2,3,10,11,12。
我想按顺序读文件夹1,2,3,10,11,12。然后读里面的文件。
我已经附加了一个代码片段和一个代码,我正在尝试,但它不是我想要的工作方式。正如您所看到的,文件夹名有一个数字(-0.png-分析,-1.png-分析,-10.png-分析,-11.png-分析,-2.png-分析),但是排序是不正确的。有什么方法可以按0,1,2,3,10,11顺序读出吗?
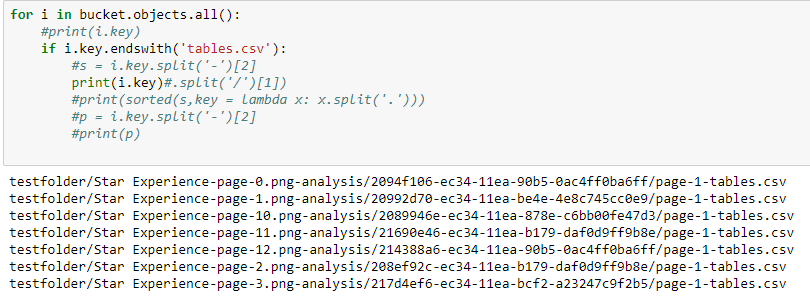
for i in bucket.objects.all():
#print(i.key)
if i.key.endswith('tables.csv'):
#s = i.key.split('-')[2]
print(i.key.split('/')[1])
#print(sorted(s,key = lambda x: x.split('.')))
#p = i.key.split('-')[2]
#print(p)
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-09-02 11:50:30
正如我所说的,使用所有对象的序列号来存储所有对象,将其作为一个dict中的键,并在这个dict上进行迭代。
下面是它的样子
import boto3
import collections
s3 = boto3.client('s3')
my_dict = {}
for obj in bucket.objects.all():
if obj.key.endswith('tables.csv'):
my_dict[int(obj.key.split('/')[1].split('-')[2].split('.')[0])] = obj.key
print(my_dict)
od = collections.OrderedDict(sorted(my_dict.items()))
for k,v in od.items():
csv_obj = s3.get_object(Bucket='bucket', Key=v)
print(csv_obj['Body'].read().decode('utf-8'))注意事项:我假设您没有任何两个具有相同序列的文件,因为这将只获得带有该序列号的最新文件,并且您将无法检索以前的文件。
OrderedDict复制自https://stackoverflow.com/a/9001529/9387017
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63685106
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号