
基于torch.rfft -fft的卷积产生与空间卷积不同的输出。
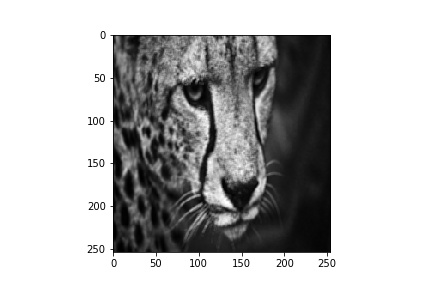
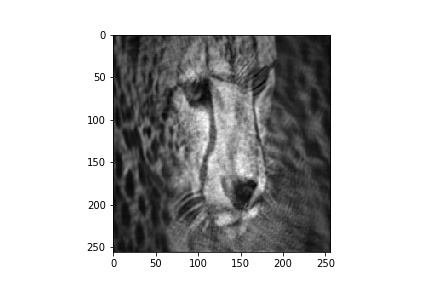
在Pytorch中实现了基于FFT的卷积,并通过conv2d()函数将结果与空间卷积结果进行了比较。所使用的卷积滤波器是一个平均滤波器。conv2d()函数由于平均滤波而产生平滑的输出,但是基于fft的卷积返回一个更模糊的输出。我把代码和输出附在这里-
空间卷积-
from PIL import Image, ImageOps
import torch
from matplotlib import pyplot as plt
from torchvision.transforms import ToTensor
import torch.nn.functional as F
import numpy as np
im = Image.open("/kaggle/input/tiger.jpg")
im = im.resize((256,256))
gray_im = im.convert('L')
gray_im = ToTensor()(gray_im)
gray_im = gray_im.squeeze()
fil = torch.tensor([[1/9,1/9,1/9],[1/9,1/9,1/9],[1/9,1/9,1/9]])
conv_gray_im = gray_im.unsqueeze(0).unsqueeze(0)
conv_fil = fil.unsqueeze(0).unsqueeze(0)
conv_op = F.conv2d(conv_gray_im,conv_fil)
conv_op = conv_op.squeeze()
plt.figure()
plt.imshow(conv_op, cmap='gray')基于FFT的卷积
def fftshift(image):
sh = image.shape
x = np.arange(0, sh[2], 1)
y = np.arange(0, sh[3], 1)
xm, ym = np.meshgrid(x,y)
shifter = (-1)**(xm + ym)
shifter = torch.from_numpy(shifter)
return image*shifter
shift_im = fftshift(conv_gray_im)
padded_fil = F.pad(conv_fil, (0, gray_im.shape[0]-fil.shape[0], 0, gray_im.shape[1]-fil.shape[1]))
shift_fil = fftshift(padded_fil)
fft_shift_im = torch.rfft(shift_im, 2, onesided=False)
fft_shift_fil = torch.rfft(shift_fil, 2, onesided=False)
shift_prod = fft_shift_im*fft_shift_fil
shift_fft_conv = fftshift(torch.irfft(shift_prod, 2, onesided=False))
fft_op = shift_fft_conv.squeeze()
plt.figure('shifted fft')
plt.imshow(fft_op, cmap='gray')原始图像-
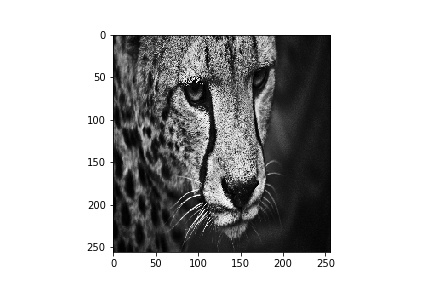
空间卷积输出-
基于fft的卷积输出
有人能解释一下这个问题吗?
回答 1
Stack Overflow用户
发布于 2020-06-08 04:51:02
你的代码的主要问题是火炬不做复数,它的FFT输出是一个三维数组,三维有两个值,一个是真实的分量,一个是虚的。因此,乘法不做复乘法。
目前火炬中没有定义复杂乘法(参见本期),我们必须定义自己的乘法。
如果您想比较这两个卷积操作,那么一个小问题也很重要:
FFT在第一个元素(图像的左上角像素)中获取其输入的原点。为了避免移位输出,您需要生成一个填充内核,其中内核的起源是左上角像素。其实这很棘手..。
您当前的代码:
fil = torch.tensor([[1/9,1/9,1/9],[1/9,1/9,1/9],[1/9,1/9,1/9]])
conv_fil = fil.unsqueeze(0).unsqueeze(0)
padded_fil = F.pad(conv_fil, (0, gray_im.shape[0]-fil.shape[0], 0, gray_im.shape[1]-fil.shape[1]))生成一个填充内核,其中原点为像素(1,1),而不是(0,0)。它需要在每个方向上移动一个像素。NumPy有一个对此有用的函数roll,我不知道火炬等效(我对火炬一点也不熟悉)。这应该是可行的:
fil = torch.tensor([[1/9,1/9,1/9],[1/9,1/9,1/9],[1/9,1/9,1/9]])
padded_fil = fil.unsqueeze(0).unsqueeze(0).numpy()
padded_fil = np.pad(padded_fil, ((0, gray_im.shape[0]-fil.shape[0]), (0, gray_im.shape[1]-fil.shape[1])))
padded_fil = np.roll(padded_fil, -1, axis=(0, 1))
padded_fil = torch.from_numpy(padded_fil)最后,应用于空域图像的fftshift函数导致频域图像(应用于图像的快速傅立叶变换的结果)被移动,使原点位于图像的中间,而不是左上角。这种移位在观察FFT的输出时是有用的,但在计算卷积时却是毫无意义的。
把这些东西放在一起,现在的卷积是:
def complex_multiplication(t1, t2):
real1, imag1 = t1[:,:,0], t1[:,:,1]
real2, imag2 = t2[:,:,0], t2[:,:,1]
return torch.stack([real1 * real2 - imag1 * imag2, real1 * imag2 + imag1 * real2], dim = -1)
fft_im = torch.rfft(gray_im, 2, onesided=False)
fft_fil = torch.rfft(padded_fil, 2, onesided=False)
fft_conv = torch.irfft(complex_multiplication(fft_im, fft_fil), 2, onesided=False)请注意,您可以执行单边FFT来节省一些计算时间:
fft_im = torch.rfft(gray_im, 2, onesided=True)
fft_fil = torch.rfft(padded_fil, 2, onesided=True)
fft_conv = torch.irfft(complex_multiplication(fft_im, fft_fil), 2, onesided=True, signal_sizes=gray_im.shape)在这里,频域大约是整个FFT的一半大小,但它只是多余的部分被遗漏。卷积的结果不变。
https://stackoverflow.com/questions/62246089
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号