
如何使用Pandas在某些行中使用update连接两个数据文件?
如何使用Pandas在某些行中使用update连接两个数据文件?
提问于 2020-05-22 09:50:20
我是熊猫新手,我想知道如何加入两个文件并更新现有的行,同时考虑到一个特定的专栏。这些文件有数千行。例如:
- Df_1:
A B C D 1 2 5 4 2 2 6 8 9 2 2 1
现在,我的表2有完全相同的列,我希望加入这两个表,替换这个表和表1中的一些行,但是在C列中有更改/更新,并添加第二个表(df_2)中存在的新行,例如:
- Df_2:
A B C D 2 2 7 8 9 2 3 3 4 6 7 2 3 4
因此,我想要的结果是两个表的联合,并在几行中更新,在一个特定的列中进行更新,如下所示:
- Df_result:
甲乙、丙、丁、二、五、四、二、七、八、二、三、六、七、二、三、三、六、六、七、二、三、三、六、六、七、二、三、三、六、七、二、三
如何使用合并或连接函数来完成此操作?还是有别的方法可以得到我想要的结果?
谢谢!
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-05-22 11:38:09
我的意思是,您需要至少有一列作为参考,才能知道需要更改哪些内容才能进行更新。
假设在你的情况下,这个例子是"A“和"B”。
import pandas as pd
ref = ['A','B']
df_result = pd.concat([df_1, df_2], ignore_index = True)
df_result = df_result.drop_duplicates(subset=ref, keep='last')这里是一个真实的例子。
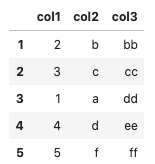
d = {'col1': [1, 2, 3], 'col2': ["a", "b", "c"], 'col3': ["aa", "bb", "cc"]}
df1 = pd.DataFrame(data=d)
d = {'col1': [1, 4, 5], 'col2': ["a", "d", "f"], 'col3': ["dd","ee", "ff"]}
df2 = pd.DataFrame(data=d)
df_result = pd.concat([df1, df2], ignore_index=True)
df_result = df_result.drop_duplicates(subset=['col1','col2'], keep='last')
df_result
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61952262
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号