
卷积神经网络理论
我很抱歉问了这个愚蠢的问题,但经过一番思考,我仍然不明白:
若要查看一幅28x28 = 784像素的图像,则可以让隐藏层的一个神经元了解输入层的大约5x5 = 25像素:
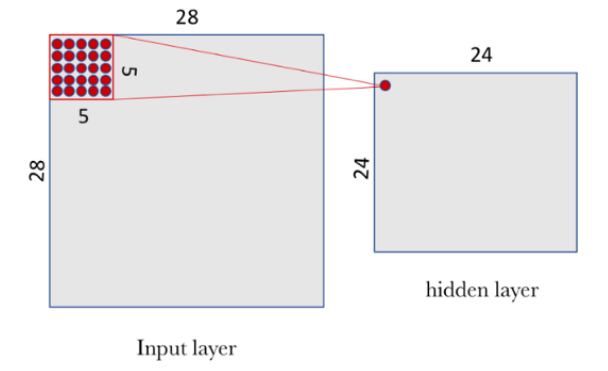
然而,正如他所解释的那样:
在分析我们提出的具体情况后,我们注意到,如果输入为28×28像素,窗口为5×5,则在第一隐层中定义了24×24神经元的空间,因为在到达输入图像的右(或底部)边界之前,只能将窗口23神经元移动到右侧,而23神经元只能移动到底部。我们想向读者指出,我们所做的假设是,当新行开始时,窗口向前移动1像素,水平和垂直移动。因此,在每一步中,新窗口都与前面的窗口重叠,但在我们已经前进的像素行中除外。
我真的不明白为什么我们需要在第一个隐藏层中有一个24x24神经元的空间?因为我取了5x5个窗口( 784个中有25个像素),我想我们需要785/25 =32个神经元。我的意思是,隐藏层的一个神经元难道不知道25个像素的特性吗?显然不是,但我真的很困惑。
回答 1
Stack Overflow用户
发布于 2020-05-06 08:21:30
假设5x5段不重叠,但事实并非如此。在本例中,第一个输出来自输入的第1-5行,第1-5列。下一列使用行1-5,列2-6,行1-5,列24-28,然后行2-6,列1-5等,直到第24-28行,第24-28栏。这被称为1的“大步”。
https://stackoverflow.com/questions/61619515
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号