
从69开始提取10位移动号码的Google sheets公式
从69开始提取10位移动号码的Google sheets公式
提问于 2019-10-29 09:04:44
我想从候选人的简历中提取手机。
我想提取的手机格式是69xxxxxxxx。
我在简历中看到的手机格式如下:
69 xxx xxxxx
0030 69xxxxxxxx
+3069xxxxxxxx
69/xxxx/xxxx下面的公式很好用,但它提取了检测到的前10位数字,而不是以69开头的数字。
=IFERROR(REGEXEXTRACT(TO_TEXT(SPLIT(REGEXREPLACE(I252;"\(|\)|\-| "; ""); CHAR(10))); "\d{10}"))回答 3
Stack Overflow用户
回答已采纳
发布于 2019-10-29 09:45:04
你可以用
=IFERROR(REGEXEXTRACT(TO_TEXT(SPLIT(REGEXREPLACE(I252;"[-/() ]+"; ""); CHAR(10))); "(?:\+|00)?(?:30)?(69\d{8})"))请参阅下面的regex演示和Google屏幕截图:

regex匹配
(?:\+|00)?-可选的+或00(?:30)?-一个可选的30(-捕获组的开始(只返回此值):69-69值\d{8}-八位数
)-小组的最后一名。
您可以考虑在正则表达式的末尾添加\b,以避免匹配大于8位的块中的8位数字。
注意,现在的分隔符清除正则表达式是[-/() ]+,它匹配一个或多个-、/、(、)和空格。
Stack Overflow用户
发布于 2019-10-29 09:11:06
解决问题的方法是使用regex查找(虽然我不知道Google是否支持这一点)。
正则表达式查找与模式匹配,但不包括在结果中。通过您的示例,这方面的语法如下:
(?<=69)\d{10}
下面的图片取自https://regex101.com/ (这是一个在使用regexp时非常有用的工具)。

Regex前瞻、查找和原子组有更多的例子来说明外观和外观是如何工作的。
Stack Overflow用户
发布于 2019-10-29 09:55:54
你所需要的就是:
=ARRAYFORMULA(IFNA(REGEXREPLACE(REGEXEXTRACT(A1:A&""; "69.*"); "\s|/|\D+"; )))
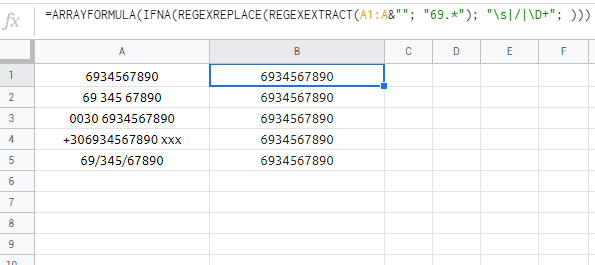
或更好:
=ARRAYFORMULA(IFNA(REGEXEXTRACT(REGEXREPLACE(A1:A&""; "\D+"; ); "69.{8}")))
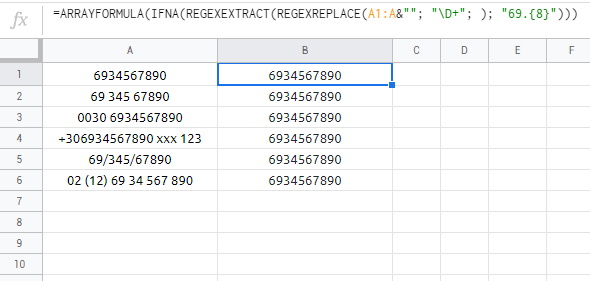
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58604187
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号