
标签-py返回‘..。在df中的一个特定列上。其他一切似乎都正常,
标签-py返回‘..。在df中的一个特定列上。其他一切似乎都正常,
提问于 2020-03-04 18:35:58
预期行为:
阅读PDF,将所有表格数据提取到熊猫df中。
实际行为:
读取PDF格式,提取大部分表数据并将其保存到带有debugging.txt的fp.write(df)中。一列(名称)通常只返回“.”当我看到debugging.txt,或观看终端打印它。
就像9/10次返回.-有时只是第一页,但其余的都没问题。有时候他们都没事..。看上去很奇怪。
(我可能是个白痴,它可能会缩短它,因为它是迄今为止最长的2-3倍。但我的Google Fu让我失望了)
示例输入(涉及隐私的名称):
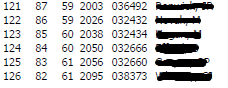
样本输出:
21 121 87 59 2003 ... NaN NaN NaN
22 122 86 59 2026 ... NaN NaN NaN
23 123 85 60 2038 ... NaN NaN NaN
24 124 84 60 2050 ... NaN NaN NaN
25 125 83 61 2056 ... NaN NaN NaN
26 126 82 61 2095 ... NaN NaN NaN代码:
pagecount = 0
for filename in os.listdir(SPLITDIR):
print("Working on: {}".format(filename))
if not filename.endswith(".pdf"):
print("I dont think {} is a PDF".format(filename))
continue
pagedf = read_pdf(SPLITPATH.format(pagecount) pages='all')
#print(pagedf)
debugextract.write(str(pagedf))
pagedf = pd.DataFrame(pagedf)
print(pagedf)
pagecount += 1回答 1
Stack Overflow用户
回答已采纳
发布于 2020-03-08 03:01:04
这不是来自塔布拉,而是ipython或木星的显示设置。
另见https://github.com/chezou/tabula-py/issues/216#issuecomment-581837621
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60532642
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号