
如何解析列表以便将其表化?
如何解析列表以便将其表化?
提问于 2020-03-17 06:26:25
我有以下列表,当出现'A‘、'B’和'D‘的值时,就像一个新的数据块的开始,因为'Q’和'T‘的值与'A’、'B‘和'D’的先前值相关联。
L1 = [
['A','01'],['B','22'],['D','Srt'],
['Q','43'],['T','00'],
['Q','11'],['T','43'],
['A','01'],['B','52'],['D','Polt'],
['Q','84'],['T','39'],
['A','01'],['B','34'],['D','Jkq'],
['Q','81'],['T','13'],
['Q','17'],['T','68'],
['Q','77'],['T','15']
]在下面的图片中,我显示了我正在寻找的输出表。我用相同的颜色表示属于A、B和D值的Q和T的值。
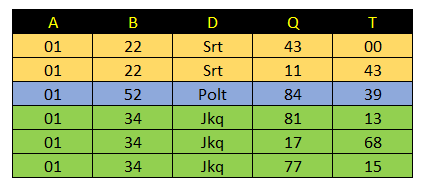
对于黄色的第二行,我填写A、B和D (01、22、Srt)的值。
对于绿色的第二行和第三行,我填充A、B和D (01、34、Jkq)的值。
对于蓝色行,由于Q和T只有一对值,所以A、B和D只有一行。
为了给Pandas DataFrame提供表格并得到所需的表,我尝试了下面的代码,并得到了这个输出。
dict = {}
for elem in L1:
if elem[0] not in dict:
dict[elem[0]] = []
dict[elem[0]].append(elem[1:])
>>>
{
'A': [['01'], ['01'], ['01']],
'B': [['22'], ['52'], ['34']],
'D': [['Srt'], ['Polt'], ['Jkq']],
'Q': [['43'], ['11'], ['84'], ['81'], ['17'], ['77']],
'T': [['00'], ['43'], ['39'], ['13'], ['68'], ['15']]}但是,输出应该具有以下结构:
Out={
'A': ['01','01','01','01','01','01'],
'B': ['22','22','52','34','34','34'],
'D': ['Srt','Srt','Polt','Jkq','Jkq','Jkq'],
'Q': ['43','11','84','81','17','77'],
'T': ['00','43','39','13','68','15'],
}为了做pandas.DataFrame(Out)
我该怎么做?谢谢。
更新
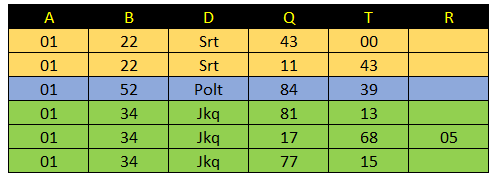
如果输入列表如下所示:
L1 = [
['A','01'],['B','22'],['D','Srt'],
['Q','43'],['T','00'],
['Q','11'],['T','43'],
['A','01'],['B','52'],['D','Polt'],
['Q','84'],['T','39'],
['A','01'],['B','34'],['D','Jkq'],
['Q','81'],['T','13'],
['Q','17'],['T','68'],['R','05'],
['Q','77'],['T','15']
]输出如下:
Out={
'A': ['01','01','01','01','01','01'],
'B': ['22','22','52','34','34','34'],
'D': ['Srt','Srt','Polt','Jkq','Jkq','Jkq'],
'Q': ['43','11','84','81','17','77'],
'T': ['00','43','39','13','68','15'],
'R': ['','','','','05','']
}
更新2
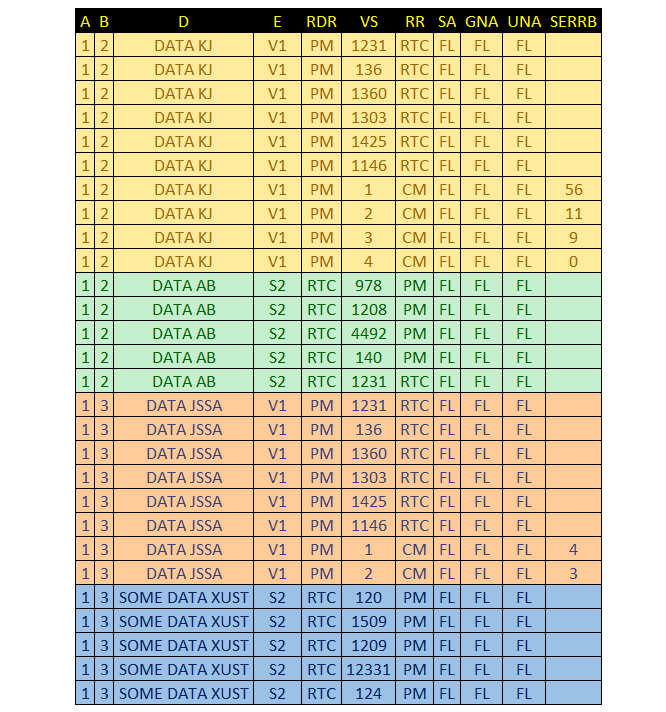
下面是一个示例输入文件,这是我用来解析它和生成列表的代码。
import re
f=open("file.txt","r").read().splitlines()
L1=[]
for line in f:
if re.match(r'[ \t]', line):
v.append(line.replace(' ', '').split('='))
L1 在这个文件中,开始一个新的“块”并且需要填充的值总是A、B、D和E。在E之后,可以是6或7个不需要填充的值(RDR、VS、RR、SA、GNA、UNA和/或SERRB),如果这些值中有些值不总是出现,则保留空白。本例中的输出表如下所示:
回答 1
Stack Overflow用户
发布于 2020-03-17 06:40:28
不如:
import pandas as pd
L1 = [['A','01'],['B','22'],['D','Srt'],
['Q','43'],['T','00'],
['Q','11'],['T','43'],
['A','01'],['B','52'],['D','Polt'],
['Q','84'],['T','39'],
['A','01'],['B','34'],['D','Jkq'],
['Q','81'],['T','13'],
['Q','17'],['T','68'],
['Q','77'],['T','15']]
d = {}
li = []
for a,b in L1:
d[a] = b # update dictionary as elements are processed
if a == 'T': # but append a copy to the list when T is processed.
li.append(d.copy())
df = pd.DataFrame(li)
print(df)输出:
A B D Q T
0 01 22 Srt 43 00
1 01 22 Srt 11 43
2 01 52 Polt 84 39
3 01 34 Jkq 81 13
4 01 34 Jkq 17 68
5 01 34 Jkq 77 15页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60717199
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号