
总结具有相似但不相同的x值的变量
我有一个有三个重复的数据集。我想画出每个X变量的平均Y变量。然而,我的x-值并不相同.
下面是我的意思的一个小例子:
Time Value repeat_name
0 5 repeat1
0 5 repeat2
0 5 repeat3
3.1 7 repeat1
3.25 8 repeat2
3 9 repeat3
6.2 5 repeat1
6.5 5 repeat2
6 5 repeat3
9.3 5 repeat1
9.75 5 repeat2
9 5 repeat3现在我希望有什么方法可以把时间存起来,然后把所有与二进制值匹配的值都放进去。
所以我有以下的垃圾箱:
Time
0-4 (values (5,5,5,7,8,9))
4-8 (values (5,5,5))
8-12 (values (5,5,5))然后我就可以取这些垃圾箱的平均值,用of图来绘制直方图。然而,我不知道我将如何实现我的目标。
我也不知道是否有更好的办法来解决这个问题。
提前谢谢你。
回答 1
Stack Overflow用户
发布于 2020-04-15 17:34:01
如果您想要根据另一个变量的分组绘制变量的平均值,则直方图不是适当的图表,因为直方图反映的是在bin范围内的观察计数。
正如Tjebo上面所指出的,ggplot有一些可以计算数据摘要统计信息的stat函数。
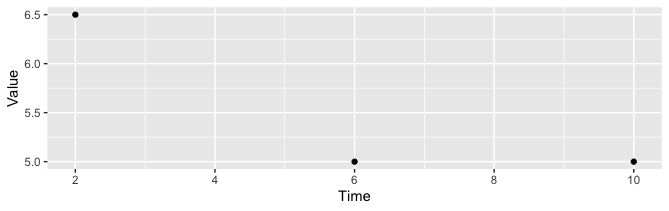
stat_summary_bin()函数可以计算跨绑定范围的汇总统计信息。要从上面计算Time回收箱的平均值,可以使用以下代码:
ggplot(df, aes(x=Time, y = Value)) +
stat_summary_bin(geom = "point",
fun.y = mean,
fun.ymin = NULL,
fun.ymax= NULL,
breaks=seq(0, 12,by = 4))其中,mean是在数据上计算的摘要函数,而bin范围是使用seq(0, 12, by = 4)设置的,以匹配上面的bin范围。还可以使用binwidth参数或使用bins参数提供默认的桶宽。
或者,可以使用dplyr::case_when()语句计算组方法,以生成分组变量,根据新创建的分组变量对数据帧进行分组,最后汇总值。
df %>%
mutate(
group_var = case_when(
Time >=0 & Time < 4 ~ 1,
Time >= 4 & Time < 8 ~ 2,
Time >= 8 & Time < 12 ~ 3
)
) %>%
group_by(group_var) %>%
summarize(grouped_mean = mean(Value)https://stackoverflow.com/questions/61233939
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号