
基于Azure的Hadoop集群(HDInsight)如何转化为经典的前提下Hadoop集群?
Apache被设计为运行在一堆商品机器(节点)上。这并不是设计用来在基于云的复杂场景中运行的。但是,由于云允许通过VM模拟单个节点,基于云的Hadoop集群应运而生。但这给我带来了理解上的困难。当我研究Hadoop集群的任何标准解释时,总是基于prem架构,因为所有Hadoop体系结构都是用逻辑和简单的on-prem视图来解释的。但这给理解基于云的集群是如何工作的带来了困难--特别是HDFS、数据局部性等概念。在解释的on版本中,每个节点都有自己的“本地”存储(这也意味着存储硬件是为特定节点修复的,它不会被洗牌),而且也不会假设节点被删除。此外,我们将该存储作为节点本身的一部分,因此我们从不考虑杀死节点并保留存储以供以后使用。
现在,在基于云的Hadoop(HDInsight)模型中,我们可以为集群附加任何Azure存储帐户作为主存储。那么,如果我们有一个包含4个工作节点和2个头节点的集群,那么这个单独的Azure存储帐户充当了6台虚拟机的HDFS空间?而且,实际的业务数据甚至没有存储在上面--它存储在附加的存储帐户上。所以我无法理解这是如何被转换到集群的?Hadoop集群的核心设计围绕着数据局部性的概念,即数据驻留在最接近处理的位置。我知道,当我们创建HDInsight集群时,我们在与所附加的存储帐户相同的区域中创建它。但是,它更像是多个处理单元(VM),它们都共享公共存储,而不是单个节点使用自己的本地存储。也许,只要它能够足够快地访问数据(就像它驻留在数据中心一样),这就不重要了。但不确定是否是这样。基于云的模型向我展示了以下图片:
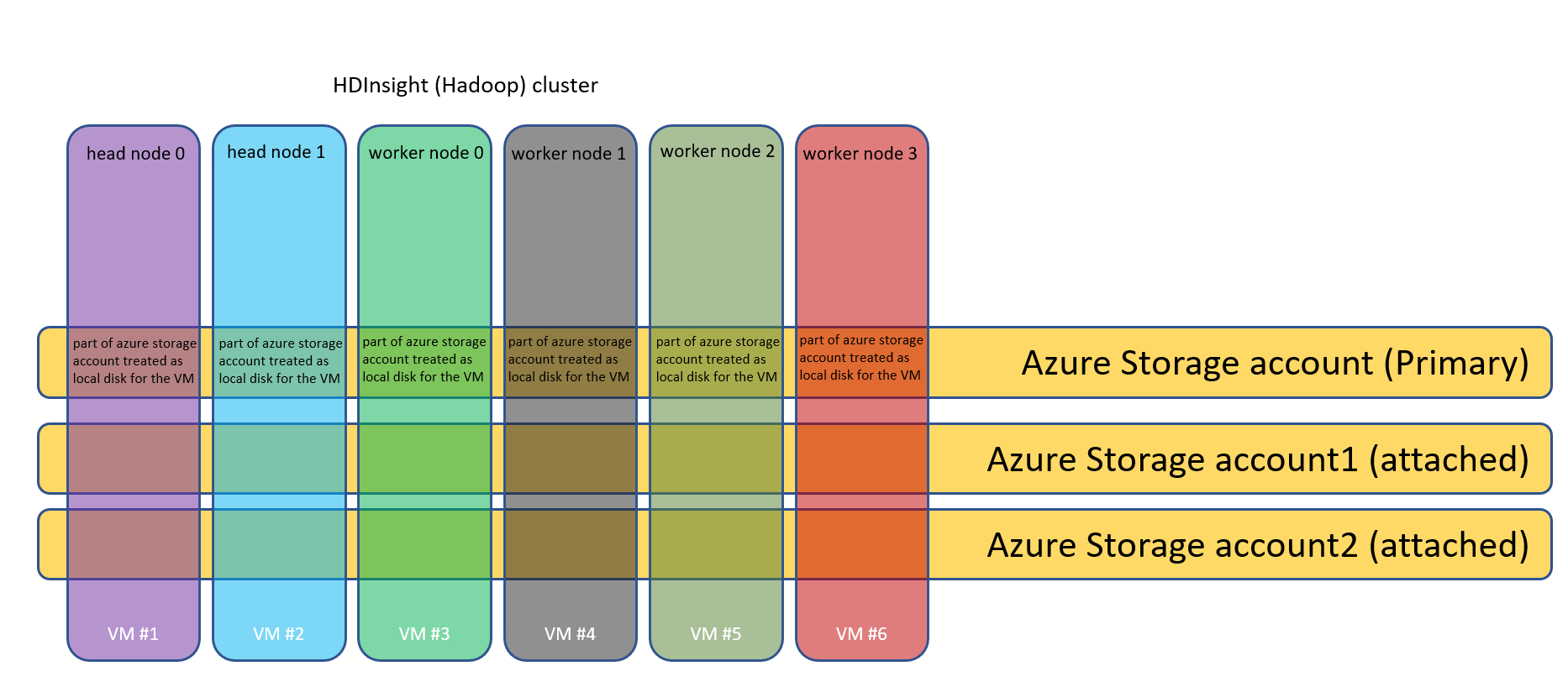
有人能确切地解释Apache设计是如何转化为基于Azure的模型的吗?混淆产生于这样一个事实:存储帐户是固定的,我们可以随时杀死/自旋集群,以指向相同的存储帐户。
回答 1
Stack Overflow用户
发布于 2020-10-01 14:30:23
当HDInsight执行其任务时,它是将数据从存储节点流到计算节点。但是Hadoop正在执行的许多映射、排序、洗牌和精简任务都是在驻留在计算节点本身的本地磁盘上完成的。
映射、约简和排序任务通常将在网络负载最小的计算节点上执行,而混洗任务将使用某些网络将数据从映射器节点移动到较少的减少节点。
将数据存储回存储的最后一步通常是一个小得多的数据集(例如,查询数据集或报表)。最后,在初始和最后的流阶段,网络被更多地利用,而大多数其他任务都是在节点内执行(即最小的网络利用率)。
要更详细地理解,您可以查看"为什么在Azure上使用Blob存储和HDInsight“和"HDInsight体系结构”。
https://stackoverflow.com/questions/64133270
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号