
熊猫:计算事件周围时间序列数据的平均行为
熊猫:计算事件周围时间序列数据的平均行为
提问于 2020-12-18 12:30:15
我有两个带有日期时间信息的数据,df_stream是一个事件流,df_events是特定的时间事件。例如:

蓝色是流,红线是事件。窗口是30min,事件的两边都是30s,时间粒度是30s。
如何生成给定时间窗口和时间粒度的所有事件的流的平均行为的数据/图?
流dataframe看起来如下:
streamEventId
DateTime
2020-08-20 10:39:24 44791313
2020-08-20 10:40:30 44791721
2020-08-20 10:40:54 44694121
2020-08-20 10:41:16 44902962
2020-08-20 10:42:04 44622569事件dataframe如下所示:
DateTime
0 2020-11-17 09:49:00
1 2020-11-17 10:49:00
2 2020-11-17 11:11:00
3 2020-11-17 11:16:00
4 2020-11-17 12:11:00我成功地获得了每个事件的图表,并打印了各自的窗口,但我很难将逻辑结合起来。此外,我使用的iterrows,我不是一个球迷。
我目前的做法是:
for i in df_events[["DateTime"]].iterrows():
date_time = i[1].values[0]
before = date_time - pd.Timedelta(window)
after = date_time + pd.Timedelta(window)
df_stream_temp = df_stream.loc[before:after].copy()
plt.figure(figsize=(20, 2))
df_stream_mva = (
df_stream.streamEventId.groupby(pd.Grouper(freq="30s"))
.count()
.loc[before:after]
)
y_height = df_stream_mva.max()
ax = df_stream_mva.plot()
plt.vlines(df_events.DateTime.to_list(), 0, y_height, color="lightcoral")
ax.set_ylim([0, y_height]) 它给出了一系列很好的图表:
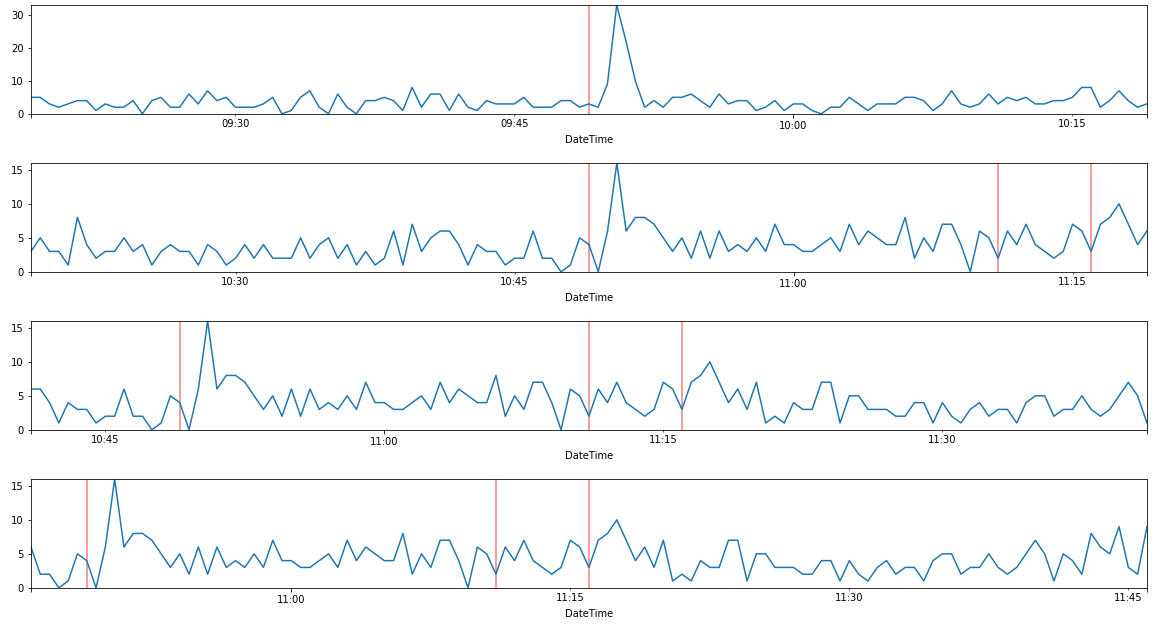
等等..。
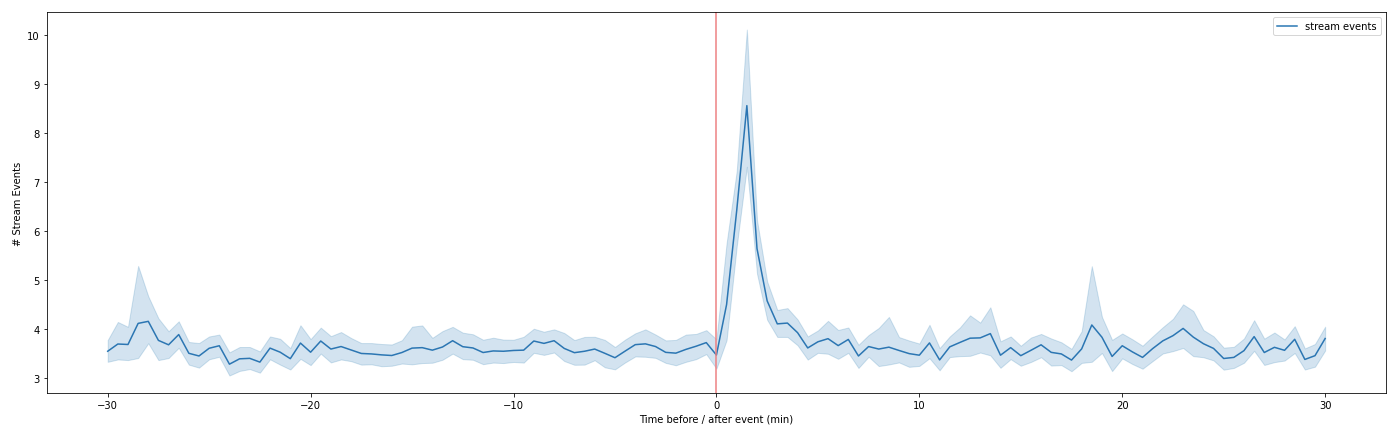
,我想计算一下,然后用置信区间来绘制上面的平均值。
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-12-21 13:59:34
坐下来想办法解决。
使用与上面的iterrows示例类似的逻辑,我遍历了df_events,创建了before和after时间窗口限制,并使用这些限制来过滤按给定时间频率分组的df_stream。然后使用时间增量索引重新计算索引,以获得“距离事件”索引。然后将其附加到一个列表中,然后使用pd.concat将其组合为1。
window = "30 min"
freq = "30s"
collect_list = []
for i in df_events[["DateTime"]].iterrows():
date_time = i[1].values[0]
before = date_time - pd.Timedelta(window)
after = date_time + pd.Timedelta(window)
df_stream_window = (
df_stream.streamEventId.groupby(pd.Grouper(freq=freq))
.count()
.loc[before:after]
.reset_index()
.rename(columns={"streamEventId": "stream events"})
)
df_stream_window = df_stream_window.set_index(
pd.to_timedelta((df_stream_window.DateTime - pd.to_datetime(date_time)))
/ np.timedelta64("1", "m")
)
collect_list.append(df_stream_window)
df_collect = pd.concat(collect_list, axis=1)这产生了以下数据:
DateTime stream events DateTime \
DateTime
-30.0 2020-11-17 09:19:00 5 2020-11-17 10:19:00
-29.5 2020-11-17 09:19:30 5 2020-11-17 10:19:30
-29.0 2020-11-17 09:20:00 3 2020-11-17 10:20:00
-28.5 2020-11-17 09:20:30 2 2020-11-17 10:20:30
-28.0 2020-11-17 09:21:00 3 2020-11-17 10:21:00
stream events DateTime stream events \
DateTime
-30.0 3 2020-11-17 10:41:00 6
-29.5 5 2020-11-17 10:41:30 6
-29.0 3 2020-11-17 10:42:00 4
-28.5 3 2020-11-17 10:42:30 1
-28.0 1 2020-11-17 10:43:00 4
....然后,这可以用于在海运中使用estimator="mean"绘图:
ax = sns.lineplot(data=df_collect, estimator="mean")
plt.axvline(0, color="lightcoral")
ax.set_xlabel("Time before / after event (min)")
ax.set_ylabel("# Stream Events")
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65357115
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号