
为什么Selenium在某些站点上找不到元素?
为什么Selenium在某些站点上找不到元素?
提问于 2020-12-24 05:30:27
我正在使用python版本的Selenium来捕捉中国网站上的评论。
网站是https://v.douyu.com/show/kDe0W2q5bB2MA4Bz
我想找到这个跨度元素。在中文中,这被称为"弹幕列表“。
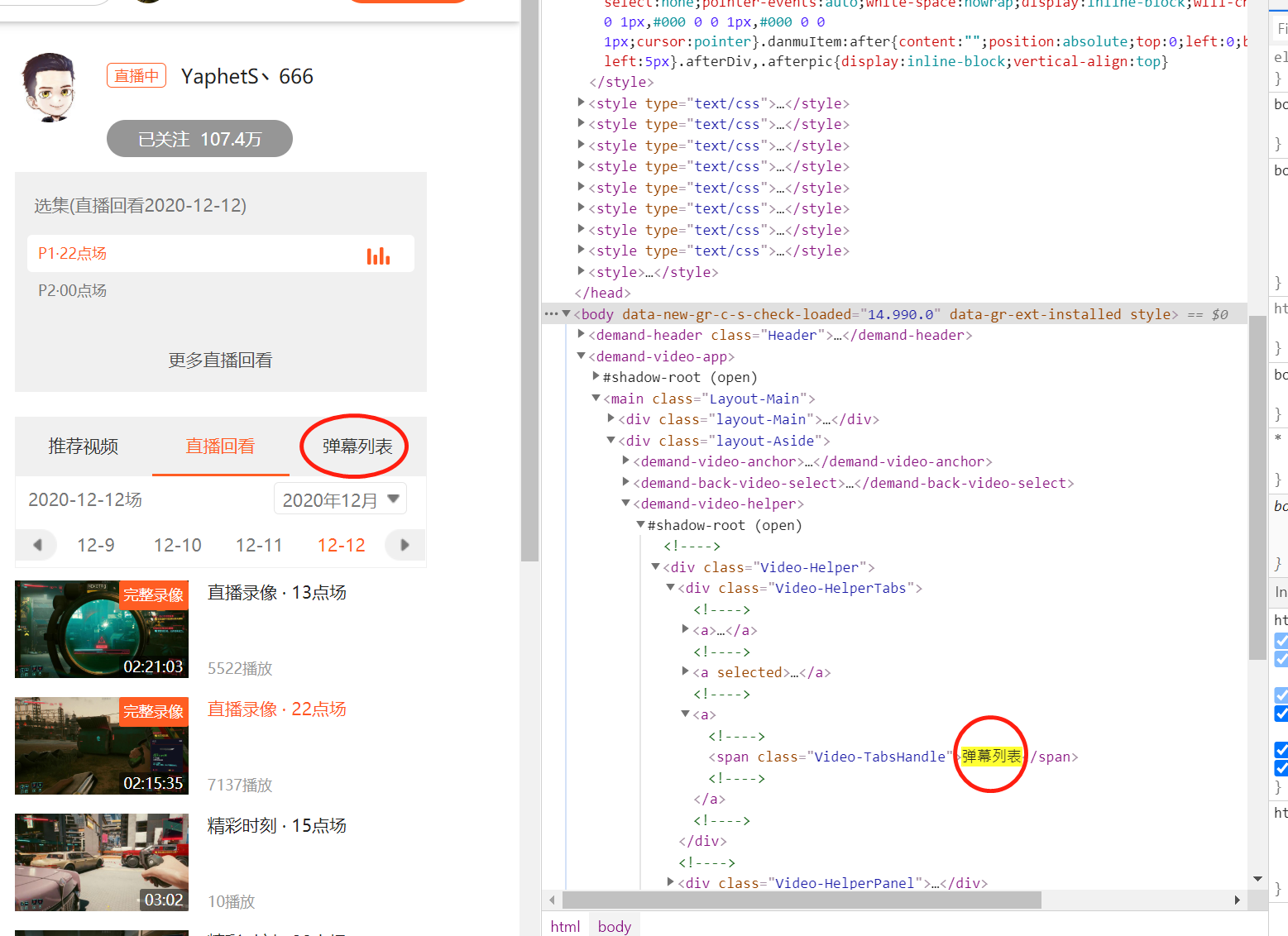
我尝试了这样一条绝对的道路:
driver.find_elements_by_xpath('/body/demand-video-app/main/div[2]/demand-video-helper//div/div[1]/a[3]/span')但是它返回NoSuchElementException。我只是觉得这个网站可能有保护机制。然而,我对Selenium不太了解,我想寻求帮助。提前谢谢。
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-12-24 05:49:59
我想您使用Selenium是因为requests不能捕获值。
如果这不是你想做的,就不要读我的答案。
因为你是requests.get(url='https://v.douyu.com/show/kDe0W2q5bB2MA4Bz')
您需要在ApiUrl上找到F12 Network的数据源。
事实上,他的信息来源是
https://v.douyu.com/wgapi/vod/center/getBarrageListByPage + parameter
↓
https://v.douyu.com/wgapi/vod/center/getBarrageListByPage?vid=kDe0W2q5bB2MA4Bz&forward=0&offset=-1虽然我不能帮你解决硒问题。
但我将使用以下方法获取数据。
import requests
url = 'https://v.douyu.com/wgapi/vod/center/getBarrageListByPage?vid=kDe0W2q5bB2MA4Bz&forward=0&offset=-1'
headers = {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'}
res = requests.get(url=url, headers=headers).json()
print(res)
for i in res['data']['list']:
print(i)获取所有数据
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
url = 'https://v.douyu.com/wgapi/vod/center/getBarrageListByPage?vid=kDe0W2q5bB2MA4Bz&forward=0&offset=-1'
while True:
res = requests.get(url=url, headers=headers).json()
next_json = res['data']['pre']
if next_json == -1:
break
for i in res['data']['list']:
print(i)
url = f'https://v.douyu.com/wgapi/vod/center/getBarrageListByPage?vid=kDe0W2q5bB2MA4Bz&forward=0&offset={next_json}'页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65434360
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号