
AWS : PostgreSQL复制滞后的承诺值是多少?
我有一个包含四个副本的主RDS实例。
- 主数据库: Postgres,4 vCPU,16 2a内存,us-west-2a
- Replica1: Postgres,4 vCPU,16 No内存,us-west-2a,200 g SSD (无流量,仅供测试)
- Replica2: Postgres,4 vCPU,16 2b内存,us-west-2b,200 g SSD (无流量,仅供测试)
- Replica3: Postgres,2 vCPU,8GB内存,us-west-2b,200 g SSD (小流量)
- Replica4: Postgres,2 vCPU,8GB内存,us-west-2b,200 g SSD (小流量)
主复制和读取副本之间的延迟超过16秒,没有任何严重的IOPS,有时超过30秒。
我花了很大的精力去挖掘迟滞的根源。
以下是没有任何通信量的副本的CloudWatch报告。
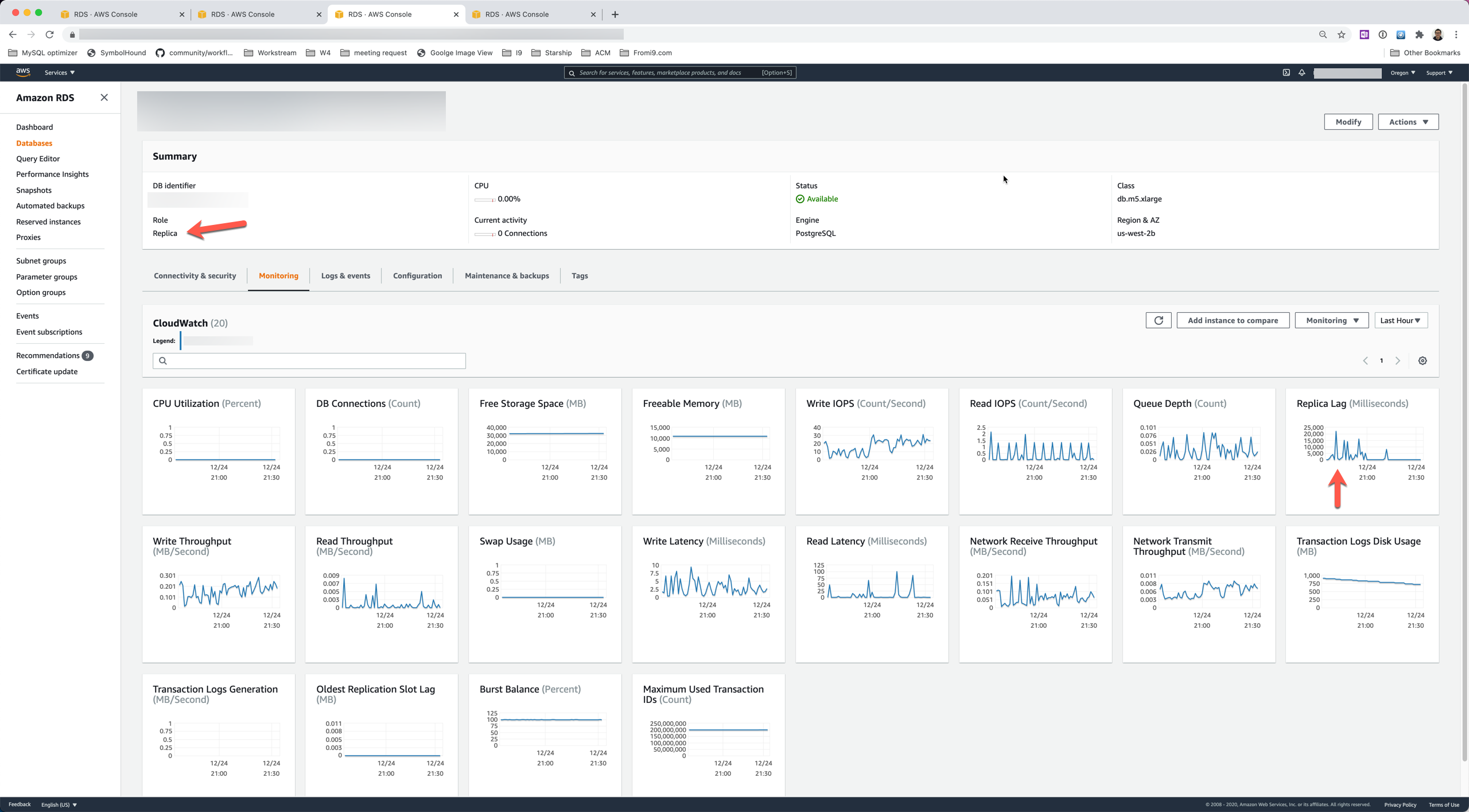
假设一:这是由IO信用引起的吗?
这是关于IO信用的报告,在过去的六个小时里,它总是100%的,我不认为它是由IO问题引起的。
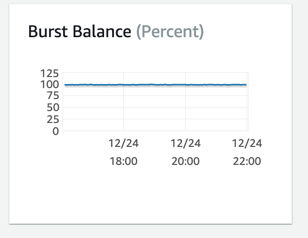
即使我不认为这是由IO引起的,我还是决定用配置的3000 IOPS将数据库的磁盘从GP2升级到IO1。
但是它不起作用,滞后仍然存在。
假设二:它是由参数热备用引起的吗?
副本里没有交通!它与postgresql参数max_standby_streaming_delay和hot standby无关。
假设三:是由网络IO引起的吗?
流量总是小于1M/s。
假设四:这是由我的应用程序中触发的长期运行的查询引起的吗?
我创建了两个全新的m5.大型PostgreSQL实例来验证这个假设,并使用pgbench进行基准测试。
- 初级:M5.大,提供了3,000个IOPS。
- 副本: M5.xlarge,有1000个提供的IOPS。
我吃了一惊!延迟从0到24秒不等。
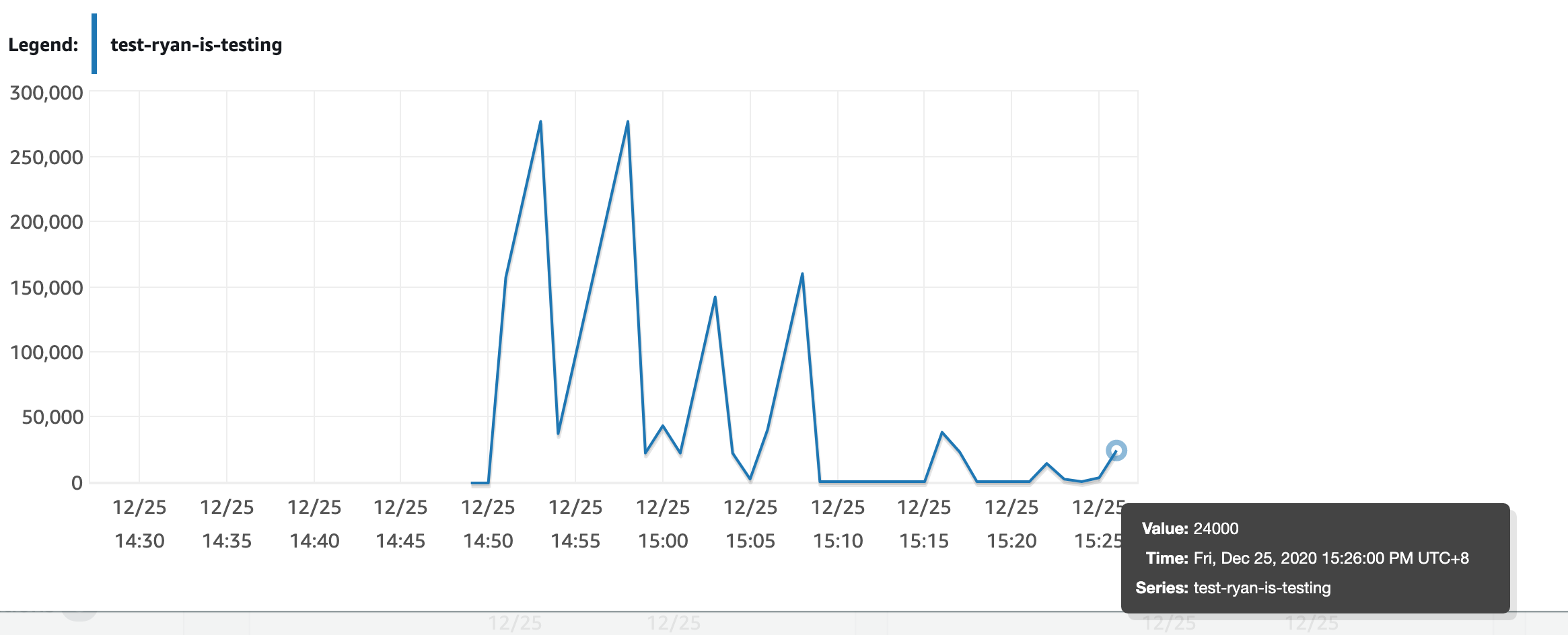
您可能会问,为什么不将此问题发布到aws?
我问过aws论坛上的这个问题,但没人回答我。
我觉得自己被欺骗了,我想从你的经历中了解复制滞后的真正价值。
问题
Aurora为延迟提供了估计值(100毫秒以下)。这是我的基准报告,滞后在25毫秒以下。
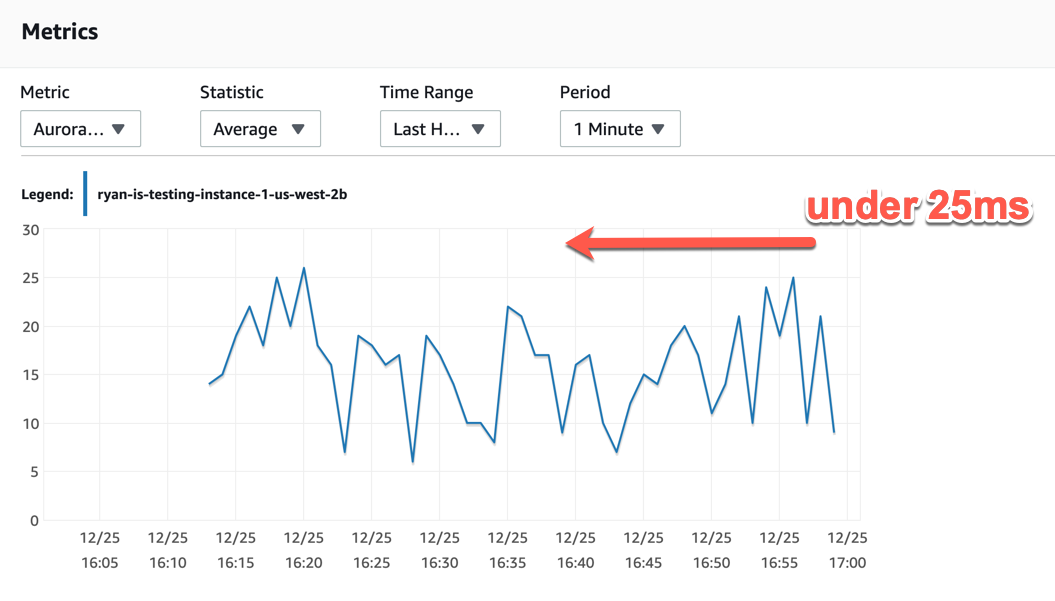
当涉及AWS时:
- 有人能告诉我野生环境下aws复制滞后的正常值是多少吗?
- 对于AWS,复制延迟的允诺估计值是多少?
回答 1
Stack Overflow用户
发布于 2021-01-29 15:53:04
根据RDS文档中的用PostgreSQL读取副本限制:
如果源DB实例上没有发生用户事务,则PostgreSQL读取副本报告的复制延迟可达5分钟。
当脚本每隔几毫秒写入数据库时,按照推荐的在这个答案中,您能检查复制滞后吗?
https://stackoverflow.com/questions/65446208
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号