
如何使用tensorflow keras模型识别大于9的数字和浮点数?
如何使用tensorflow keras模型识别大于9的数字和浮点数?
提问于 2021-05-17 01:04:42
有没有使用tensorflow keras和CNN模型来训练和识别大于9或十进制数的数字?我的意思是,值域介于0到20之间,或者是从0到10 (如0,1; 0,2;......;9,9 )之间的数字。
我已经用MNIST数据集从0到9读过训练过的模型,但是我想用大于9的十进制和值域来理解。希望能看到你对此的看法。
例如,数字10
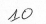
或者数字11,12,.,17,.
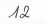
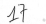
UPDATE I尝试用训练模型对上面给定的图像进行一些新的编号,但是预测值仍然是虚值的。以下是一些代码:
def trainDigitsModel(alwaysTrain=False, writeFile=True):
modelExists = os.path.exists('traineddata/traineddata.model/saved_model.pb')
if modelExists is False or alwaysTrain is True:
# load data
mnist = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# Reshaping to format which CNN expects (batch, height, width, channels)
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], X_train.shape[2], 1).astype('float32')
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], X_test.shape[2], 1).astype('float32')
# Load your own images to training and test data
X_train, y_train = load_images_to_data('path/to/trainmore', X_train, y_train)
X_test, y_test = load_images_to_data('path/to/trainmore', X_test, y_test)
# normalize inputs from 0-255 to 0-1
X_train/=255
X_test/=255
# one hot encode, value is 18 because i want to train more label from 10 - 17 -> totally has 18 from 0 - 17
number_of_classes = 18
y_train = np_utils.to_categorical(y_train, number_of_classes)
y_test = np_utils.to_categorical(y_test, number_of_classes)
# create model
model = Sequential()
model.add(Conv2D(32, (5, 5), input_shape=(X_train.shape[1], X_train.shape[2], 1), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(number_of_classes, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=5)
if writeFile is True:
model.save('traineddata/traineddata.model')
else:
# Load the model
model = tf.keras.models.load_model('traineddata/traineddata.model')
img = cv.imread('trainmore/12.png',0)
# img = cv.GaussianBlur(img, (1,1), 0)
img = cv.resize(img, (28,28))
img = np.array(img)
img = np.invert(img)
plt.imshow(img)
plt.show()
img = img.reshape(1,28,28,1)
prediction = model.predict(img)
result = np.argmax(prediction)
print(prediction)
print(result)
return model
def load_images_to_data(image_label, image_directory, features_data, label_data):
list_of_files = os.listdir(image_directory)
for file in list_of_files:
arr_file = file.split('.')
image_label = arr_file[0]
image_file_name = os.path.join(image_directory, file)
if ".png" in image_file_name:
img = cv.imread(image_file_name, 0)
img = cv.resize(img, (28,28))
im2arr = np.array(img)
im2arr = np.invert(im2arr)
# plt.imshow(im2arr)
# plt.show()
im2arr = im2arr.reshape(1,28,28,1)
features_data = np.append(features_data, im2arr, axis=0)
label_data = np.append(label_data, [image_label], axis=0)
return features_data, label_data回答 1
Stack Overflow用户
发布于 2021-05-19 13:35:13
我个人要做的是用一个数字识别器训练一个数字检测器,就像你所知道的YOLO一样。首先,您需要训练检测器来检测图像中的所有数字,并在此基础上添加经过MNIST训练的模型,以便对每个检测到的数字进行分类。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67562865
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号