
在python中将文本转换为表
我刚接触到python和大熊猫,并试图将pdf文档转换成熊猫数据。
我能够将pdf提取到文本中,但不确定如何将文本文件中的以下所需值提取到字典中。
到目前为止,我已经使用下面的代码提取pdf到文本如下:
import pandas as pd
import pdfplumber
data = './data/coc.pdf'
with pdfplumber.open(data) as pdf:
page = pdf.pages[0]
text = page.extract_text()
print(text)下面是文本文件
" \n \nCertificate of Currency \nXYZ Limited \nABN 121011100 54720 AFSL 232111 \n \nAs at Date \n2 November 2015 \nPolicy Information \nPolicy Type \nProfessional \n \n \nInsured \nUniversity of ABC and others as defined by the policy \ndocument. \n \nInsurer \nMMO Limited \n \nPolicy Number(s) \L0K107721013 \n \nPeriod of Insurance \nFrom 4.00pm 1/11/2015 to 4.00pm 1/11/2016 \n \nInterest Insured \nLoss incurred as a result of a civil liability claim made against the insured \nbased solely on the insured’s provision of their professional services \n \nLimit of Liability \n$20,000,000 any one claim and $60,000,000 in the aggregate for all claims "现在,我喜欢将文本文件转换为字典。如何使用if条件更新下面的代码以创建具有键的字典:基于\n或\n\n的值对
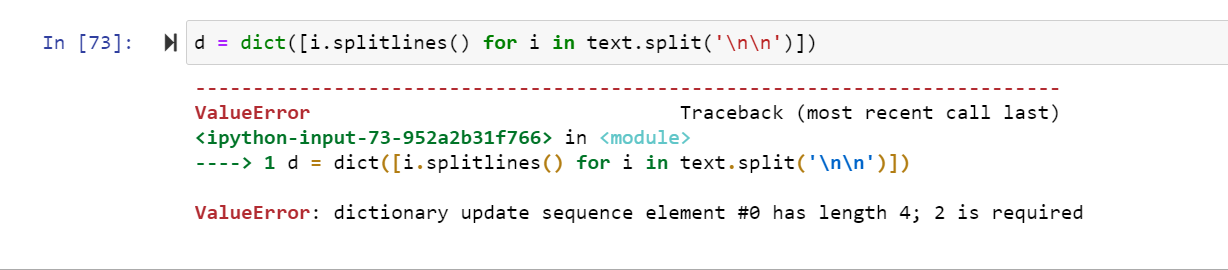
d = dict([i.splitlines() for i in text.split('\n\n')])我得到以下错误:
错误:字典更新序列元素:
请找到附加的所需输出表:
期望产出:

回答 2
Stack Overflow用户
发布于 2021-07-17 10:40:24
更新应答
我做了一些改变,以使它实际上更容易做,并使它obivous如何真正找到价值。
from pprint import pprint
from datetime import datetime
def clean_text(text) -> list:
"""Removes empty lines as well as leading and trailing spaces.
Also removes EOL characters.
Args:
text (str/list): Input text
Returns:
(list): A list of strings
"""
if type(text) == str:
splittext = text.splitlines()
if len(splittext) == 1:
print("Text is a single line string")
return text
elif type(text) == list:
splittext = text
result = []
for line in splittext:
cleaned = line.strip()
if cleaned != "":
result.append(cleaned)
return result
filename = 'text_sample1.txt'
with open(filename) as infile:
text = infile.read()
uncleaned_sections = text.split('\n \n')
sections = []
for section in uncleaned_sections:
sections.append(clean_text(section.splitlines()))
for secindex, section in enumerate(sections):
for lineindex, line in enumerate(section):
print(f'sections[{secindex}][{lineindex}]: {line}')
# with the above, we have sections of data, instead of a block of data
# this means we can change the way we deal with it
# we should have 7 sections, provided that all input files are structured
# in the same way
assert(len(sections) == 7)
pd_dt = datetime.strptime(sections[1][1], '%d %B %Y')
policy_date = f'{pd_dt.day:02}/{pd_dt.month:02}/{pd_dt.year}'
abn = sections[0][2].split('ABN ')[1].split('AFSL')[0].strip()
policy_number = sections[3][3]
period_start = sections[4][1].split("From ")[1].split(" to ")[0].split(' ')[1]
period_end = sections[4][1].split(" to ")[1].split(' ')[1]
insured = ' '.join(sections[2][1:])
insurer = sections[3][1]
interest_insured = ' '.join(sections[5][1:])
as_dict = {
'Date': policy_date,
'ABN': abn,
'Policy Number': policy_number,
'Period Start': period_start,
'Period End': period_end,
'Insured': insured,
'Insurer': insurer,
'Interest Insured': interest_insured
}
pprint(as_dict)输出
sections[0][0]: Certificate of Currency
sections[0][1]: XYZ Limited
sections[0][2]: ABN 121 011100 54720 AFSL 81141141
sections[1][0]: As at Date
sections[1][1]: 2 November 2015
sections[1][2]: Policy Information
sections[1][3]: Policy Type
sections[1][4]: Professional
sections[2][0]: Insured
sections[2][1]: University of ABC and others as defined by the policy
sections[2][2]: document.
sections[3][0]: Insurer
sections[3][1]: MMO Limited
sections[3][2]: Policy Number(s)
sections[3][3]: L0K107721013
sections[4][0]: Period of Insurance
sections[4][1]: From 4.00pm 1/11/2015 to 4.00pm 1/11/2016
sections[5][0]: Interest Insured
sections[5][1]: Loss incurred as a result of a civil liability claim made against the insured
sections[5][2]: based solely on the insured’s provision of their professional services
sections[6][0]: Limit of Liability
sections[6][1]: $20,000,000 any one claim and $60,000,000 in the aggregate for all claims
sections[6][2]: during the period of insurance. (Subject to the reinstatement provisions of
sections[6][3]: the policy).
sections[6][4]: ABN 121 011100 54720
{'ABN': '121 011100 54720',
'Date': '02/11/2015',
'Insured': 'University of ABC and others as defined by the policy document.',
'Insurer': 'MMO Limited',
'Interest Insured': 'Loss incurred as a result of a civil liability claim '
'made against the insured based solely on the insured’s '
'provision of their professional services',
'Period End': '1/11/2016',
'Period Start': '1/11/2015',
'Policy Number': 'L0K107721013'}注:先前的答案
这个答案适用于问题的前一次迭代:-/
您需要处理文本中的行,并找到正确的行来提取所需的数据。
我提供了如何找到问题中列出的值的示例。我建议您检查w3schools中使用的基本字符串方法.
下面的代码应该足以让你开始..。
码
def clean_text(text: str) -> list:
"""Removes empty lines as well as leading and trailing spaces.
Also removes EOL characters.
Args:
text (str): Input text
Returns:
(list): A list of strings
"""
splittext = text.splitlines()
if len(splittext) == 1:
print("Text is a single line string")
return text
result = []
for line in splittext:
cleaned = line.strip()
if cleaned != "":
result.append(cleaned)
return result
text = " \n \nCertificate of Currency \nXYZ Limited \nABN 121011100 54720 AFSL 232111 \n \nAs at Date \n2 November 2015 \nPolicy Information \nPolicy Type \nProfessional \n \n \nInsured \nUniversity of ABC and others as defined by the policy \ndocument. \n \nInsurer \nMMO Limited \n \nPolicy Number(s) \L0K107721013 \n \nPeriod of Insurance \nFrom 4.00pm 1/11/2015 to 4.00pm 1/11/2016 \n \nInterest Insured \nLoss incurred as a result of a civil liability claim made against the insured \nbased solely on the insured’s provision of their professional services \n \nLimit of Liability \n$20,000,000 any one claim and $60,000,000 in the aggregate for all claims "
text = clean_text(text)
# I alsways add this when using the 'previous_line' method below
# it can reduce failures
text.append('')
previous_line = ""
for line in text:
# two \ needed due to it being a special character in strings
if "Policy Number(s)" in previous_line:
policy_number = line
elif "From " in line and "Period of Insurance" in previous_line:
# this is a secondary check for the start/end dates
# Just in case another line in the text contains 'From '
start = line.split("From ")[1].split(" to ")[0]
end = line.split(" to ")[1]
elif "ABN " and "AFSL " in line:
# using different method than the splits above
abn_split = line.split()
abn_value = f"{abn_split[1]} {abn_split[2]}"
previous_line = line
# Some try/except blocks to check if the values have been found
try:
print(f"Start: {start}\nEnd: {end}")
except NameError as e:
print("Start/End dates not found")
try:
print(f"ABN: {abn_value}")
except NameError as e:
print("ABN not found")
try:
print(f"Policy Number: {policy_number}")
except NameError as e:
print("Policy number not found")输出
Start: 4.00pm 1/11/2015
End: 4.00pm 1/11/2016
ABN: 121011100 54720
Policy Number: L0K107721013 Stack Overflow用户
发布于 2021-07-17 10:24:59
您的问题确实有些宽泛,但如果我理解正确的话,您的主要问题是将PDF中的表格拿到Pandas dataframe,并且在将PDF作为文本阅读之后,您在问题中列出了问题。但是,我认为使用tabula更容易,让它直接将PDF解析为。
安装表格:
pip install tabula-py使用表格:
import tabula
dfs = tabula.read_pdf("myfile.pdf", pages='all')
# Note that dfs is list of dataframes, the tables found in the PDF.然后就到了。您的其他问题与Pandas有关,我建议您要么在Pandas文档/论坛中搜索答案,要么问一个关于如何处理数据格式的单独问题。
请注意,PDF处理从来没有100%的精确性,因为PDF本身并不意味着要被机器解释。此解决方案可能工作,也可能不工作,取决于PDF。对我来说,它确实解决了一个类似的问题。
https://stackoverflow.com/questions/68418734
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号