
使用R中适当的图来可视化二进制变量和范畴变量之间的关系。
使用R中适当的图来可视化二进制变量和范畴变量之间的关系。
提问于 2022-11-14 23:33:46
我有一个dataframe,其中变量top10的值为0(不在前10中)和1(在前10中)。和一个分类可变的标签(独立,华纳音乐,索尼音乐,环球音乐)。
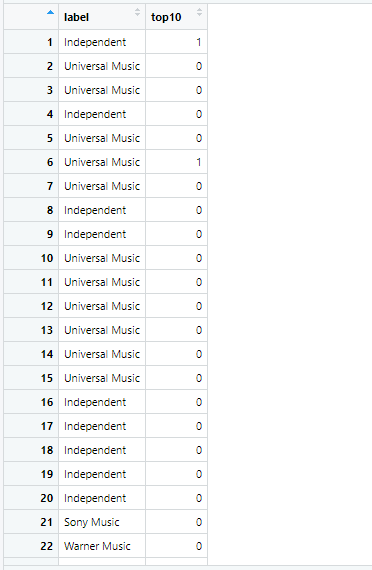
有什么合适的图解来可视化这些变量之间的关系?
我正在考虑想象每一个标签进入前10名的可能性(top10 == 1)。但我不知道怎么做..。
这就是我开始做的:

回答 1
Stack Overflow用户
发布于 2022-11-15 04:21:47
除了Jared已经提出的伟大建议之外,还有另一个选择。首先,我加载了管道和绘图的tidyverse。然后,我随机地重新创建了您的数据集,虽然这里我只使用了两类音乐来简化,但是您当然可以添加更多。
#### Load Library for Plotting/Wrangling Data ####
library(tidyverse)
#### Set Seed and Recreate Data ####
set.seed(123)
label <- rep(
c("Independent",
"Universal Music"),
11)
top10 <- rbinom(
n=22,
size=1,
prob=.5
)
tib <- tibble(
label,
top10
)
tib然后,我使用这个条形图绘制您的数据,使用二进制作为一个因子,并使用position = "dodge"代码将二进制拆分为标签因子。剩下的只是美学上的东西。
#### Plot Data ####
tib %>%
ggplot(aes(x=label,
fill=factor(top10)))+
geom_bar(position = "dodge")+
labs(x="Label",
y="Top 10",
title = "Bar Plot of Label Data",
fill="Binary Variable")+
scale_fill_manual(values = c("darkred",
"darkblue"))+
theme(legend.position = "bottom")这给了你这样的可视化:
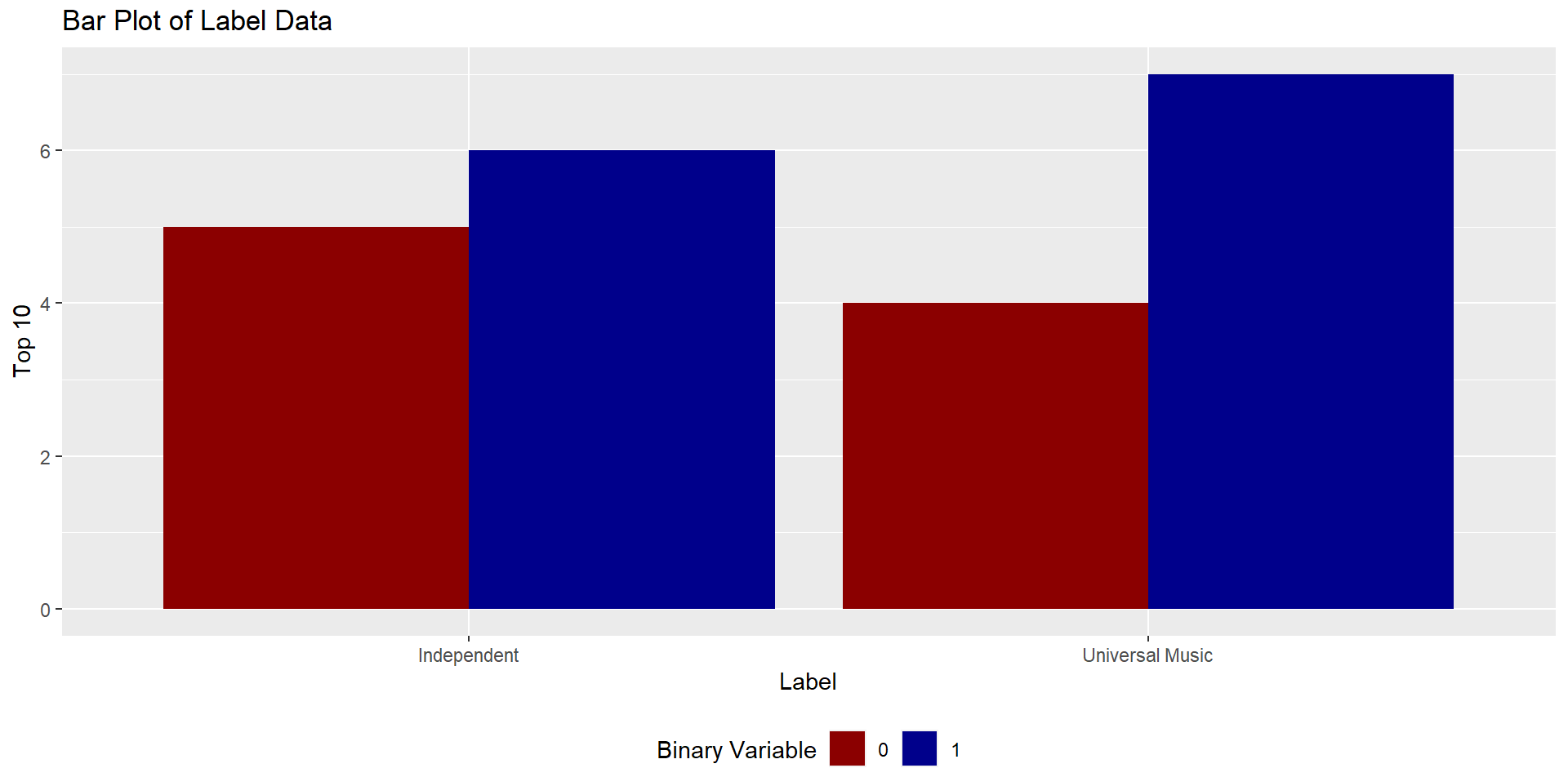
你当然可以随心所欲地把标签弄干净。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74439075
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号