
如何创建算法对Pandas中字符串列中的值进行简单计算?
如何创建算法对Pandas中字符串列中的值进行简单计算?
提问于 2022-07-06 23:43:28
我有如下所示的DataFrame,col1的数据类型是str:
col1
---------
46081402525
77020220486
1233GGdP
NaN
....我只需要选择不符合的行,这些行满足以下条件:
例如,"col1“(46081402525)中的第一个值的算法如下所示,因此该值中的最后一个字符应该是4。
example:
- 4*1 = 4
- 6*3 = 18
- *7 = 0
- 8*9 =0
- 8*9=72
H 1161*1=1H 217H 118H 1184*3=12H 219H 120H 120H 221<代码>H 1222×9=18<代码>H 223H 124/代码>代码5*1*1= 5
2*3 =2*3。注意,如果在乘积时得到一个两位数,则只添加最后一个数字(例如,而不是18相加8)。4+8+0+2+1+2+0+8+5+6 = 36
减去从10得到的结果。注意:如果在加法过程中得到一个两位数,则只减去最后一个数字(例如,而不是36减去6)。10-6= 4
因此我需要:
col1
---------
77020220486我怎么能在Python Pandas中做到这一点呢?当然,请注意,在"col1“中,有时可以用字符(不仅仅是数字)或NaN来表示值。
回答 1
Stack Overflow用户
发布于 2022-07-07 01:48:54
解决方案应如下所示。
给出潘达斯的框架
df = pd.DataFrame({'col1' : ["46081402525", "77020220486", "1233GGdP", "NaN"]})您可以使用以下方法
def deriveValue(x:str):
x = str(x)
parameterSeq = '13791379130' # added 0 in the end to match lengths
try:
y = int(x)
except:
return ''
if len(x)!=11:
return ''
else:
output = sum([int(digit)*int(para)%10 for digit,para in zip(x,parameterSeq)])
return 10 - output % 10将其应用到数据格式的df中
df['col2'] = df['col1'].apply(deriveValue)收益率
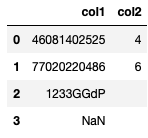
但是,请注意,权重序列的长度为10,而您提供的输入序列为11。因此,我在后面添加了一个0。你可能想要修改这个。
因为每个步骤中的数字最多只有2位,所以模块化操作%10可以证明按您指定的方式工作(如果有两个数字,则忽略第一个数字)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72890910
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号