
如何从字典列表中创建Dataframe?
如何从字典列表中创建Dataframe?
提问于 2022-06-15 06:13:12
我有这样的字典清单:
collection = [{'item': ['Policy Master 1-2022-2023-P0003 - 5 Days - Plan 3', 'Policy Master 2-2022-2023-P0009 - 5 Days - Plan 3', 'Policy Master 3-2022-2023-P0012 - 5 Days - Plan 3', 'Policy Master 1-2022-2023-P0003 - 5 Days - Plan 2', 'Policy Master 2-2022-2023-P0009 - 5 Days - Plan 2'], 'Mar': [2800.0, 600.0, 600.0, 1000.0, 200.0]}, {'item': ['Policy Master 1-2022-2023-P0003 - 5 Days - Plan 3', 'Policy Master 2-2022-2023-P0009 - 5 Days - Plan 3', 'Policy Master 3-2022-2023-P0012 - 5 Days - Plan 3', 'Policy Master 1-2022-2023-P0003 - 5 Days - Plan 2'], 'Jun': [2800.0, 600.0, 600.0, 1000.0]}]我想从显示与之相对应的月度数据中进行项目。如果上个月不存在项目,则应在前一个月显示NaN。在熊猫里怎么做呢?此外,未来还可以增加更多的月份。所以它应该动态地考虑所有的月份。
回答 2
Stack Overflow用户
发布于 2022-06-15 06:34:21
似乎您有一个可以合并到一起的可能的数据文件列表:
for i, x in enumerate(collection):
if not i:
df = pd.DataFrame(x)
else:
df = df.merge(pd.DataFrame(x), 'outer')
print(df)输出:
item Mar Jun
0 Policy Master 1-2022-2023-P0003 - 5 Days - Plan 3 2800.0 2800.0
1 Policy Master 2-2022-2023-P0009 - 5 Days - Plan 3 600.0 600.0
2 Policy Master 3-2022-2023-P0012 - 5 Days - Plan 3 600.0 600.0
3 Policy Master 1-2022-2023-P0003 - 5 Days - Plan 2 1000.0 1000.0
4 Policy Master 2-2022-2023-P0009 - 5 Days - Plan 2 200.0 NaN或者:
from functools import reduce
reduce(lambda x, y: pd.merge(pd.DataFrame(x), pd.DataFrame(y), 'outer'), collection)Stack Overflow用户
发布于 2022-06-15 07:01:11
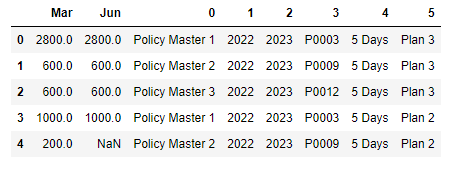
继续并完成前面的代码:
for i, x in enumerate(collection):
if not i:
df = pd.DataFrame(x)
else:
df = df.merge(pd.DataFrame(x), 'outer')
df_1 = df['item'].str.split("-", expand=True)
df = df.join(df_1)
df.drop(['item'], axis=1, inplace=True)投入:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72626621
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号