
可以在每个新的索引组重新启动项目吗?
可以在每个新的索引组重新启动项目吗?
提问于 2022-05-20 16:39:09
我有一个库存模型,其中我有输入,增加库存,输出减少库存每天。存货不能低于零。
import numpy as np
import pandas as pd
day = [1, 2, 3, 4, 5, 6, 1, 2, 3, 1, 2]
item_id = [1, 1, 1, 1, 1, 1, 2, 2, 2, 3, 3]
item_name = ['A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'C', 'C']
increase = [4, 0, 4, 0, 3, 3, 0, 3, 3, 3, 3]
decrease = [2, 2, 2, 5, 0, 0, 5, 1, 1, 1, 1]
my_df = pd.DataFrame(list(zip(day, item_id, item_name, increase, decrease)),
columns=['day', 'item_id', 'item_name', 'increase', 'decrease'])
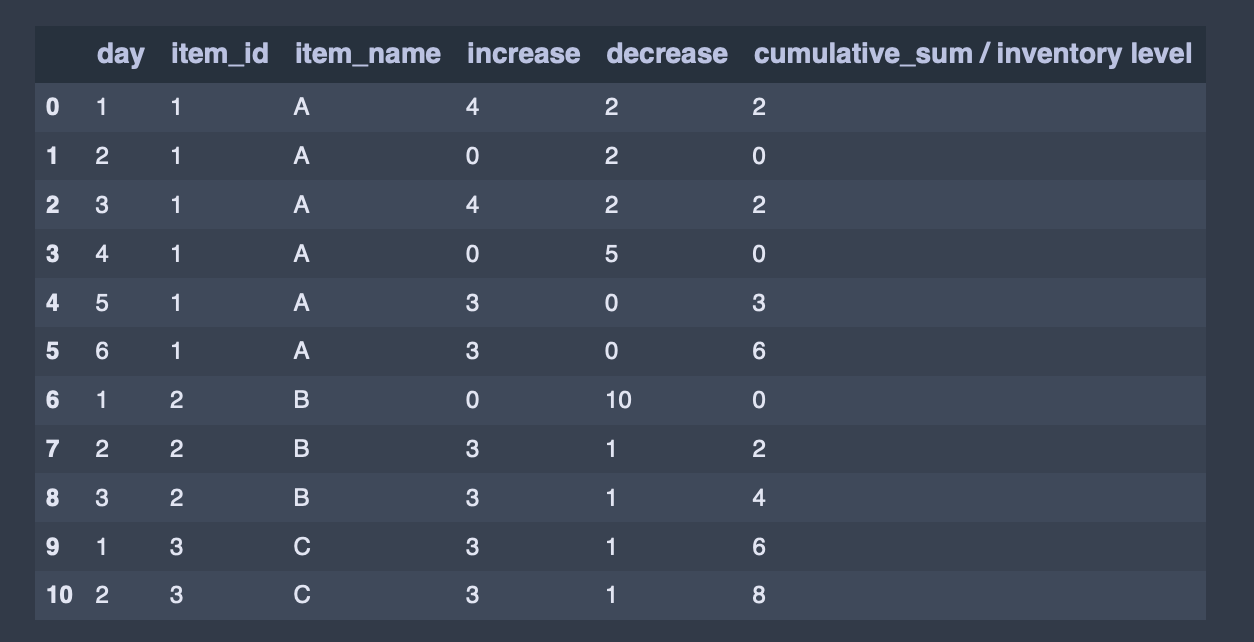
# my_df = my_df.set_index(['item_id', 'item_name'])我正在计算每一天结束时,每件物品的库存。Iterrow似乎是处理非负需求的一个很好的选择,但是我的方法不会重新启动每个新项目的零库存。
inv_accumulator=[]
closing_inv_qty=0
for index, row in my_df.iterrows():
closing_inv_qty = np.maximum(closing_inv_qty + row["increase"] - row["decrease"], 0)
inv_accumulator.append(closing_inv_qty)
my_df['cumulative_sum / inventory level'] = inv_accumulator
my_df而不是这里的输出:B应该有0的库存水平,然后2,然后4C的库存水平应该是2,然后是4。
我尝试过的groupby方法似乎不适用于迭代行。还有别的方法来计算这个吗?
回答 1
Stack Overflow用户
发布于 2022-05-20 20:43:47
同样从Python Pandas iterrows() with previous values的角度来看,以下内容似乎是正确的:
my_df['change'] = my_df['increase'] - my_df['decrease']
inventory = []
for index, row in my_df.iterrows():
if my_df.loc[index, 'day']==1:
my_df.loc[index, 'beg_inventory'] = 0
my_df.loc[index, 'end_inventory'] = np.maximum(my_df.loc[index, 'change'], 0)
# my_df.loc[index, 'end_inventory'] = np.maximum(row['change'], 0) # same
else:
my_df.loc[index, 'beg_inventory'] = my_df.loc[index - 1, 'end_inventory']
my_df.loc[index, 'end_inventory'] = np.maximum(
my_df.loc[index - 1, 'end_inventory'] + my_df.loc[index, 'change'], 0)
my_df页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72322181
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号