
两个或多个熊猫行的条件(不仅仅是分组计算)
两个或多个熊猫行的条件(不仅仅是分组计算)
提问于 2022-05-16 20:42:40
我有df和学生的名字,他/她的分数,班级名称,考试日期。我需要添加一个列,如图片所示,它将表示学生的成绩是否提高(3-4个条件分数,如“分数增加”、“分数下降”、“相等”或“初等”)。我已经根据此对df进行了排序,现在需要比较行和下一行中的一些条件,如果所有的true都应该返回一个标记。是否有一种有效的方法来做到这一点(我的实际表将由100万行组成,这就是为什么不应该消耗内存)?提前谢谢你?
df=pd.DataFrame({"score":[10,20,15,10,20,30],
"student":['John', 'Alex', "John", "John", "Alex", "John"],
"class":['english', 'math', "english",'math','math', 'english'],
"date":['01/01/2022','02/01/2022', '05/01/2022', '17/02/2022', '02/01/2022', '03/01/2022']})
df=df.sort_values(['student','class', 'date'])
回答 3
Stack Overflow用户
回答已采纳
发布于 2022-05-16 20:48:17
使用groupby和diff()获取分数的变化,然后使用numpy.select分配值
import numpy as np
changes = df.groupby(["student","class"], sort=False)["score"].diff()
df["progress"] = np.select([changes.eq(0),changes.gt(0),changes.lt(0)],
["equal score","score increased","score decreased"],
"initial")
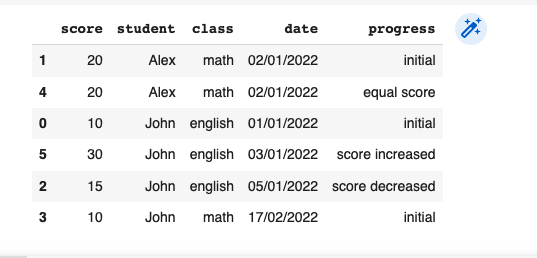
>>> df
score student class date progress
1 20 Alex math 02/01/2022 initial
4 20 Alex math 02/01/2022 equal score
0 10 John english 01/01/2022 initial
5 30 John english 03/01/2022 score increased
2 15 John english 05/01/2022 score decreased
3 10 John math 17/02/2022 initialStack Overflow用户
发布于 2022-05-16 20:48:37
您可以使用groupby.diff计算差额,然后使用获取符号,并将您想要的文本放在map上。默认情况下使用fillna (“初始”):
df['progress'] = (np.sign(df.groupby(['student', 'class'])
['score'].diff())
.map({0: 'equal', 1: 'increases', -1: 'decreases'})
.fillna('initial')
)输出:
score student class date progress
1 20 Alex math 02/01/2022 initial
4 20 Alex math 02/01/2022 equal
0 10 John english 01/01/2022 initial
5 30 John english 03/01/2022 increases
2 15 John english 05/01/2022 decreases
3 10 John math 17/02/2022 initialStack Overflow用户
发布于 2022-05-16 21:01:51
这是我用的一种渐进的方法
df['RN'] = df.sort_values(['date'], ascending=[True]).groupby(['student', 'class']).cumcount() + 1
#df.sort_values(['student', 'RN']) #To visually see progress of student before changes
df['Progress'] = df['RN'].apply(lambda x : str(x).replace('1', 'initial'))
df = df.sort_values(['student', 'RN'])
df['score_shift'] = df['score'].shift()
df['score_shift'].fillna(0, inplace = True)
df['score_shift'] = df['score_shift'].astype(int)
condlist = [df['Progress'] == 'initial', df['score_shift'] == df['score'], df['score_shift'] > df['score'], df['score_shift'] < df['score']]
choicelist = ['initial', 'equal', 'decrease', 'increase']
df['Progress'] = np.select(condlist, choicelist)
df页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72265395
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号