
熊猫多指标将项目除以类群之和
熊猫多指标将项目除以类群之和
提问于 2022-04-26 19:57:28
我有一张桌子如下所示:
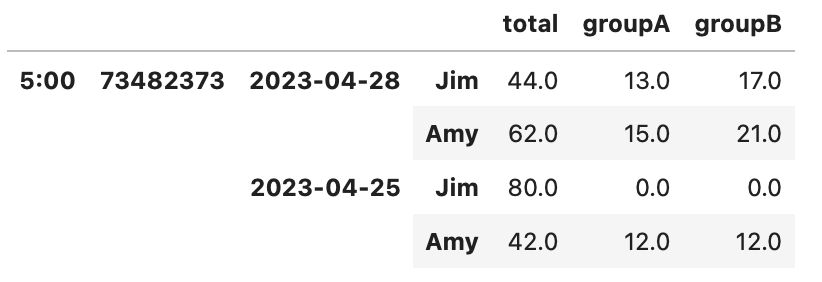
我希望更改此表,以便groupA和groupB中的值是每个日期总计的百分比。例如,Jim2023-0428的groupA值应该为13/(44+62)。输出表如下所示:
我不知道怎么做,因为这是一个多索引表。到目前为止,我已经尝试过用for循环手动集成所有日期,然后将整个列的和存储在字典中,但这似乎非常慢。
下面是顶层数据框架的dict (用于测试!):
df_a = {'total': {
("5:00",
73482373,
'2023-04-28',
'Jim'): 44.0,
("5:00",
73482373,
'2023-04-28',
'Amy'): 62.0,
("5:00",
73482373,
'2023-04-25',
'Jim'): 80.0,
("5:00",
73482373,
'2023-04-25',
'Amy'): 42.0
},
'groupA': {
("5:00",
73482373,
'2023-04-28',
'Jim'): 13.0,
("5:00",
73482373,
'2023-04-28',
'Amy'): 15.0,
("5:00",
73482373,
'2023-04-25',
'Jim'): 0.0,
("5:00",
73482373,
'2023-04-25',
'Amy'): 12.0
},
'groupB': {
("5:00",
73482373,
'2023-04-28',
'Jim'): 17.0,
("5:00",
73482373,
'2023-04-28',
'Amy'): 21.0,
("5:00",
73482373,
'2023-04-25',
'Jim'): 0.0,
("5:00",
73482373,
'2023-04-25',
'Amy'): 12.0}}回答 1
Stack Overflow用户
发布于 2022-04-26 20:08:59
你可以用groupby和transform来做
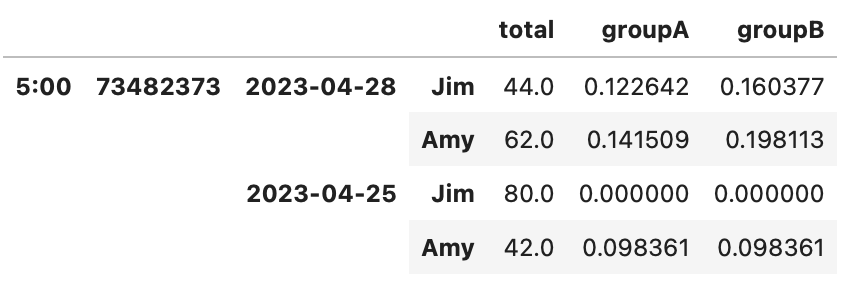
df[['groupA', 'groupB']] = df[['groupA', 'groupB']] / df.groupby(level=[0,1,2])['total'].transform('sum').to_numpy()[:, None]输出:
>>> df
total groupA groupB
5:00 73482373 2023-04-28 Jim 44.0 0.122642 0.160377
Amy 62.0 0.141509 0.198113
2023-04-25 Jim 80.0 0.000000 0.000000
Amy 42.0 0.098361 0.098361页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72019843
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号