
如何找到与同一对象相关联的对象的最大计数
我有一个Mentor类,其中我对每个导师都有一个ID,以及一个mentee ID的ArrayList,如下所示:
public class Mentor {
int mentorId;
ArrayList<Integer> mentees = new ArrayList<>();
public Mentor(int mentorId, ArrayList<Integer> mentees) {
this.mentorId = mentorId;
this.mentees = mentees ;
}
}问题是,一些被辅导者也可以成为导师。
我想以某种方式获得与顶级导师相关的所有被辅导者的计数,以及在顶级导师之下有多少导师。
所以,基本上,如果一位导师有一位导师,他也是一位导师,那么这个导师的导师也会与顶级导师联系在一起。
因此,我的想法是循环遍历被访问列表,看看是否有任何id与ID of Mentor匹配。如果为真,请将此导师的被辅导者列表再次添加到列表和循环中,但这将无法动态工作。
我的主课是这样的:
ArrayList<Mentor> mentors = new ArrayList<>();
ArrayList<Integer> mentees = new ArrayList<>();
ArrayList<Integer> mentees2 = new ArrayList<>();
mentees.add(2);
mentees.add(3);
mentees2.add(4);
mentees2.add(5);
//[1,{2,3}]
mentors.add(new Mentor(1, mentees));
//[2,{4,5}]
mentors.add(new Mentor(2, mentees2));
int mentorCount = 0;
int menteeCount = 0;
for (Mentor mentor : mentors) {
for (Integer mentee : mentees) {
mentorCount++;
if (mentee == mentor.mentorId){
mentorCount++;
//add each mentee to arraylist and start the process again, but is there an easier way to do this.
}
}
}我想知道是否有解决这个问题的方法,也许可以使用streams。
回答 4
Stack Overflow用户
发布于 2022-04-12 00:16:47
首先,让我们简单地回顾一下这个任务。
你有一组导师,每个导师都有一组导师。他们中的一些人可能碰巧也是导师等等。
班级设计
从类设计的角度来看,解决方案非常简单:您只需要一个类来描述这种关系-- Mentor。每个Mentor都应该保存一个对Mentor的集合(而不是整数ids)的引用。
在您的领域模型中,正如您所描述的,导师和被辅导者之间没有实质性的区别。导师指的是其他导师--这是一个最简单的建模方法。Mentee只是一个边缘案例,一个导师,它有一个空的指导者集合。
您不需要在应用程序中包含没有好处的类和特性。
数据结构
从数据结构的角度看,这个问题可以用一个无环的不相交的图很好地描述。
因为如果我们考虑导师之间的关系时,当导师可以间接地指向他们自己(即指导者N有一个被辅导者,而in tern指向另一个恰好也是导师N的导师),那么任务就变得模棱两可。因此,我假设没有人可以成为自己的导师。
我还将这种数据结构描述为不相交,因为这个模型中的导师(以及现实生活中的导师)可以形成孤立的组,在图论中称为连通组件。这意味着可能有几个导师拥有相同数量的被辅导者,而这恰好是最大的。
深度优先搜索
为了找到与特定导师相关的所有顶点(导师),我们提出了一种经典的遍历算法,称为深度优先搜索(DFS)。DFS的核心思想是窥视给定顶点的单个邻居,然后依次查看它的一个邻居,以此类推,直到到达不指向另一个顶点的顶点(即达到最大深度)。然后,它应该与以前访问过的顶点的每个其他邻居一起完成。
有两种实现DFS的方法。
迭代法
为此,我们需要一堆。它将存储以前遇到的顶点的所有未访问邻居。首先将探索每个分支中每个邻居列表中的最后一个顶点,因为它将放置在堆栈的顶部。然后,它将被从堆栈中移除,并且它的邻居将被放置在堆栈上。此过程在循环中重复,直到堆栈包含至少一个元素。
堆栈最具表现性的集合选择是ArrayDeque。
由于这种方法需要通过添加和删除顶点来不断修改堆栈,所以它不适合用Stream实现。
递推法
总体原理与上面描述的相同,但我们不需要以爆炸性的方式提供堆栈。JVM的调用堆栈将用于此目的。
使用这种方法,也有一些应用流的空间。因此,我选择了递归实现。而且,它的代码可能更容易理解。但是请记住,递归有一定的局限性,特别是在Java中,并且不适合处理大量数据。
递归
递归的快速回顾。
每个递归实现由两部分组成:
- Base --表示一个简单的边缘案例,其结果是预先知道的。对于此任务,基本情况是给定顶点没有邻居。这意味着这个顶点的
menteesCount需要设置为0,因为它没有对象。而基大小写的返回值是1,因为这个顶点反过来是另一个顶点的有效指导者,它持有对它的引用。 - 递归案例--解决方案的一部分,递归调用已生成的,主逻辑驻留在其中。
递归案例可以使用流实现,并包含对给定顶点的每个邻居的递归调用。这些值中的每一个都将贡献给给定顶点的menteesCount。
该方法返回的值将是menteesCount + 1,因为对于触发此方法调用的顶点,给定的顶点将既是被调用的对象,也是它的被访问者。
实现
类导师基本上是图的一个顶点。每个顶点都有唯一的id和相邻顶点的集合。
此外,为了重用通过执行DFS获得的值,我添加了一个字段menteesCount,该字段最初初始化为-1,以便区分没有相邻顶点的顶点(即menteesCount必须是0)和值未计算的顶点。每个值将只被建立一个,然后被重用(另一个方法是为此目的使用一张地图)。
方法getTopMentors()遍历顶点集合,并对尚未计算值的每个顶点调用DFS。此方法返回具有最多关联被辅导者数量的导师列表。
方法addMentor(),它接受一个顶点id,并添加它的邻居的id (如果有的话),以便以一种方便的方式与图进行交互。
Map mentorById包含图中添加的每个顶点,顾名思义,它允许根据顶点id检索它。
public class MentorGraph {
private Map<Integer, Mentor> mentorById = new HashMap<>();
public void addMentor(int mentorId, int... menteeIds) {
Mentor mentor = mentorById.computeIfAbsent(mentorId, Mentor::new);
for (int menteeId: menteeIds) {
mentor.addMentee(mentorById.computeIfAbsent(menteeId, Mentor::new));
}
}
public List<Mentor> getTopMentors() {
List<Mentor> topMentors = new ArrayList<>();
for (Mentor mentor: mentorById.values()) {
if (mentor.getCount() != -1) continue;
performDFS(mentor);
if (topMentors.isEmpty() || mentor.getCount() == topMentors.get(0).getCount()) {
topMentors.add(mentor);
} else if (mentor.getCount() > topMentors.get(0).getCount()) {
topMentors.clear();
topMentors.add(mentor);
}
}
return topMentors;
}
private int performDFS(Mentor mentor) {
if (mentor.getCount() == -1 && mentor.getMentees().isEmpty()) { // base case
mentor.setCount(0);
return 1;
}
int menteeCount = // recursive case
mentor.getMentees().stream()
.mapToInt(m -> m.getCount() == -1 ? performDFS(m) : m.getCount() + 1)
.sum();
mentor.setCount(menteeCount);
return menteeCount + 1;
}
public static class Mentor {
private int id;
private Set<Mentor> mentees = new HashSet<>();
private int menteesCount = -1;
public Mentor(int id) {
this.id = id;
}
public boolean addMentee(Mentor mentee) {
return mentees.add(mentee);
}
// getters, setter for menteesCount, equeals/hashCode
}
}用作演示的图形的示例。
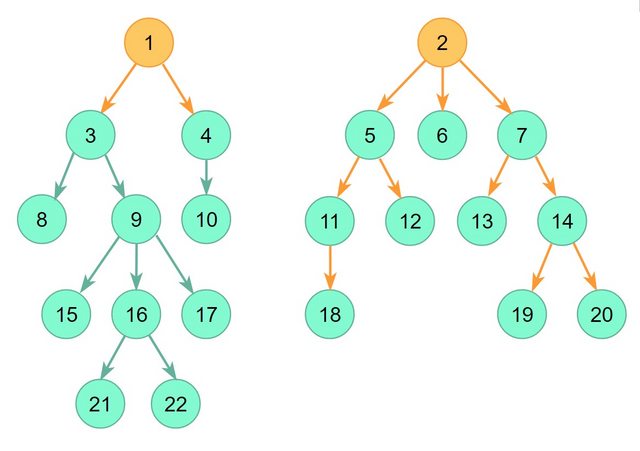
main() --代码建模了上面所示的图形
public static void main(String[] args) {
MentorGraph graph = new MentorGraph();
graph.addMentor(1, 3, 4);
graph.addMentor(2, 5, 6, 7);
graph.addMentor(3, 8, 9);
graph.addMentor(4, 10);
graph.addMentor(5, 11, 12);
graph.addMentor(6);
graph.addMentor(7, 13, 14);
graph.addMentor(8);
graph.addMentor(9, 16, 17, 18);
graph.addMentor(10);
graph.addMentor(11, 18);
graph.addMentor(12);
graph.addMentor(13);
graph.addMentor(14, 19, 20);
graph.addMentor(15);
graph.addMentor(16, 21, 22);
graph.addMentor(17);
graph.addMentor(18);
graph.addMentor(19);
graph.addMentor(20);
graph.addMentor(21);
graph.addMentor(22);
graph.getTopMentors()
.forEach(m -> System.out.printf("mentorId: %d\tmentees: %d\n", m.getId(), m.getCount()));
}输出
mentorId: 1 mentees: 10
mentorId: 2 mentees: 10Stack Overflow用户
发布于 2022-04-11 17:08:08
我建议使用良好的面向对象设计,您不应该只使用整数id,因为在这种情况下,您可以简单地对Person对象创建一个ArrayList,其中被指导者和导师继承自Person。然后,您可以检查一个人是被导师还是指导者的实例:
for (Person p : people) {
if (p instanceof Mentor)
{
// Mentor logic
}
if (p instanceof Mentee)
{
// Mentee Logic
}
}Stack Overflow用户
发布于 2022-04-12 04:21:00
使用Person和Mentor以及acornTime建议的Mentee子类,将mentees定义为Person列表,您想要的信息变得很简单:
import java.util.*;
import java.util.stream.Stream;
public class Main{
public static void main(String[] args) {
ArrayList<Person> mentees = new ArrayList<>();
mentees.add(new Mentee(11));
mentees.add(new Mentee(12));
mentees.add(new Mentor(2, new ArrayList<>()));
mentees.add(new Mentee(13));
mentees.add(new Mentee(14));
mentees.add(new Mentor(3, new ArrayList<>()));
mentees.add(new Mentor(4, new ArrayList<>()));
mentees.add(new Mentor(5, new ArrayList<>()));
Mentor mentor = new Mentor(1, mentees);
System.out.println(mentor.menteesCount());
System.out.println(mentor.mentorsInMentees().count());
}
}
interface Person {
int getId();
}
class Mentor implements Person{
private final int mentorId;
private List<Person> mentees = new ArrayList<>();
public Mentor(int id, ArrayList<Person> mentees) {
mentorId = id;
this.mentees = mentees ;
}
@Override
public int getId() {
return mentorId;
}
public List<Person> getMentees() {
return mentees;
}
public int menteesCount() {
return mentees.size();
}
public Stream<Person> mentorsInMentees(){
return mentees.stream().filter(m -> (m instanceof Mentor));
}
}
class Mentee implements Person{
private final int menteeId;
public Mentee(int id) {
menteeId = id;
}
@Override
public int getId() {
return menteeId;
}
}在线测试这里
https://stackoverflow.com/questions/71831102
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号