
尽可能有效地在矩阵中找到序列
几个需求.
在发帖之前请先回答!
1)确保您的函数不会给其他数据带来错误,模拟几个类似的矩阵。(关掉种子)
2)确保您的功能比我的更快
3)确保您的函数与我的完全相同,在不同的矩阵上模拟它(关闭种子)
例如
for(i in 1:500){
m <- matrix(sample(c(F,T),30,T),ncol = 3) ; colnames(m) <- paste0("x",1:ncol(m))
res <- c(my_fun(m),your_function(m))
print(res)
if(sum(res)==1) break
}
m4)该函数应该使用任意数量的行和列的矩阵。
==========================================================函数在逻辑矩阵的第一列中查找true,如果找到真,则转到第2列和新行,等等。如果找到序列true false,则返回(如果没有)
set.seed(15)
m <- matrix(sample(c(F,T),30,T),ncol = 3) ; colnames(m) <- paste0("x",1:ncol(m))
m
x1 x2 x3
[1,] FALSE TRUE TRUE
[2,] FALSE FALSE FALSE
[3,] TRUE TRUE TRUE
[4,] TRUE TRUE TRUE
[5,] FALSE FALSE FALSE
[6,] TRUE TRUE FALSE
[7,] FALSE TRUE FALSE
[8,] FALSE FALSE FALSE
[9,] FALSE FALSE TRUE
[10,] FALSE FALSE TRUE我的慢示例函数
find_seq <- function(m){
colum <- 1
res <- rep(FALSE,ncol(m))
for(i in 1:nrow(m)){
if(m[i,colum]==TRUE){
res[colum] <- TRUE
print(c(row=i,col=colum))
colum <- colum+1}
if(colum>ncol(m)) break
}
all(res)
}
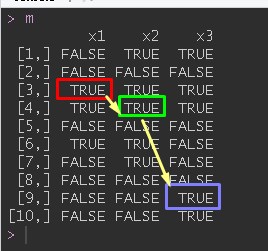
find_seq(m)
row col
3 1
row col
4 2
row col
9 3
[1] TRUE如何使它尽可能快?
UPD=========================
microbenchmark::microbenchmark(Jean_Claude_Arbaut_fun(m),
+ ThomasIsCoding_fun(m),
+ my_fun(m))
Unit: microseconds
expr min lq mean median uq max neval cld
Jean_Claude_Arbaut_fun(m) 2.850 3.421 4.36179 3.9915 4.5615 27.938 100 a
ThomasIsCoding_fun(m) 14.824 15.965 17.92030 16.5350 17.1050 101.489 100 b
my_fun(m) 23.946 24.517 25.59461 25.0880 25.6580 42.192 100 c回答 6
Stack Overflow用户
发布于 2022-04-07 12:12:38
如果我正确地理解了这个问题,那么一个通过行的循环就足够了。下面是一种使用Rcpp实现此操作的方法。这里我只返回真假答案,如果你需要索引,它也是可行的。
library(Rcpp)
cppFunction('
bool hasSequence(LogicalMatrix m) {
int nrow = m.nrow(), ncol = m.ncol();
if (nrow > 0 && ncol > 0) {
int j = 0;
for (int i = 0; i < nrow; i++) {
if (m(i, j)) {
if (++j >= ncol) {
return true;
}
}
}
}
return false;
}')
a <- matrix(c(F, F, T, T, F, T, F, F, F, F,
T, F, T, T, F, T, T, F, F, F,
T, F, T, T, F, F, F, F, T, T), ncol = 3)
a
hasSequence(a)为了获得索引,下面的函数返回一个列表,其中至少有一个元素(名为' found‘、true或false),如果found= true,则返回另一个名为’indices‘的元素:
cppFunction('
List findSequence(LogicalMatrix m) {
int nrow = m.nrow(), ncol = m.ncol();
IntegerVector indices(ncol);
if (nrow > 0 && ncol > 0) {
int j = 0;
for (int i = 0; i < nrow; i++) {
if (m(i, j)) {
indices(j) = i + 1;
if (++j >= ncol) {
return List::create(Named("found") = true,
Named("indices") = indices);
}
}
}
}
return List::create(Named("found") = false);
}')
findSequence(a)了解Rcpp的几个链接:
- 使用Rcpp的高性能功能,Hadley Wickham
- 每个人的Rcpp,Masaki E. Tsuda
- R与C/C++的接口,Matteo
- Rcpp画廊 - Rcpp包的文章和代码示例
您必须至少了解一点C语言(最好是C++,但对于基本用法来说,您可以将Rcpp视为C,并为R数据类型提供一些神奇的语法)。第一个链接解释了Rcpp类型的基本知识(向量、矩阵和列表,以及如何分配、使用和返回它们)。其他环节是很好的补充。
Stack Overflow用户
发布于 2022-04-07 08:28:56
更新
如果您正在追求速度,您可以尝试下面的基本R解决方案
TIC_fun <- function(m) {
p <- k <- 1
nr <- nrow(m)
nc <- ncol(m)
repeat {
if (p > nr) {
return(FALSE)
}
found <- FALSE
for (i in p:nr) {
if (m[i, k]) {
# print(c(row = i, col = k))
p <- i + 1
k <- k + 1
found <- TRUE
break
}
}
if (!found) {
return(FALSE)
}
if (k > nc) {
return(TRUE)
}
}
}你会看到
Unit: microseconds
expr min lq mean median uq max neval
my_fun(m) 18.600 26.3010 41.46795 41.5510 44.3010 121.302 100
TIC_fun(m) 10.201 14.1515 409.89394 22.6505 24.4005 38906.601 100先前的回答
您可以尝试下面的代码
lst <- with(as.data.frame(which(m, arr.ind = TRUE)), split(row, col))
# lst <- apply(m, 2, which)
setNames(
stack(
setNames(
Reduce(function(x, y) y[y > x][1],
lst,
init = -Inf,
accumulate = TRUE
)[-1],
names(lst)
)
),
c("row", "col")
)这给
row col
1 3 1
2 4 2
3 9 3一个更有趣的实现可能是使用递归(只是为了好玩,而不是因为效率低下而重新命令)。
f <- function(k) {
if (k == 1) {
return(data.frame(row = which(m[, k])[1], col = k))
}
s <- f(k - 1)
for (i in (tail(s, 1)$row + 1):nrow(m)) {
if (m[i, k]) {
return(rbind(s, data.frame(row = i, col = k)))
}
}
}这给了
> f(ncol(m))
row col
1 3 1
2 4 2
3 9 3Stack Overflow用户
发布于 2022-04-07 10:06:50
如果您的例子具有代表性,我们假设是nrow(m) >> ncol(m)。在这种情况下,将interation从行移动到列将更有效:
ff = function(m)
{
i1 = 1
for(j in 1:ncol(m)) {
if(i1 > nrow(m)) return(FALSE)
i1 = match(TRUE, m[i1:nrow(m), j]) + i1
#print(i1)
if(is.na(i1)) return(FALSE)
}
return(TRUE)
}https://stackoverflow.com/questions/71778612
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号