
查感知Jacobi 2D微基准测试的混淆结果
我的目标是实现一个低延迟版本的jacobi 2d模板。默认版本在下面的代码片段中描述:
for(auto i = 1; i < N - 1; ++i) {
for(auto j = 1; j < N - 1; ++j) {
*B[i][j] = 0.2 * (*A[i][j] + *A[i][j-1] + *A[i][1+j] + *A[1+i][j] + *A[i-1][j]);
}
}
for(auto i = 1; i < N - 1; ++i) {
for(auto j = 1; j < N - 1; ++j) {
*A[i][j] = 0.2 * (*B[i][j] + *B[i][j-1] + *B[i][1+j] + *B[1+i][j] + *B[i-1][j]);
}
}请注意,有两个矩阵,它们的值根据彼此的值一个接一个地更新。模板基本上计算单元格的北、南、东、西单元格值的平均值和单元格本身的值。
假设矩阵中的值是" double“,矩阵用double AN表示,N是单行/列中的项数。
与使用2d双数组创建矩阵的传统方法不同,我选择了一个2d矩阵,该矩阵由指向双重( double * AN)的指针组成。我们称之为“查感知矩阵”。我这样做的原因是,我将并行化代码,以便每个线程绑定在一起的核心都将与各个线程正在修改/读取的内存地址的一致性进行管理。为了便于论证,假设我的系统有4个核,核cha映射如下: core0-cha1,core1-cha2,core2-cha3,core3-cha0。下面是我为N=14系统构建的矩阵:
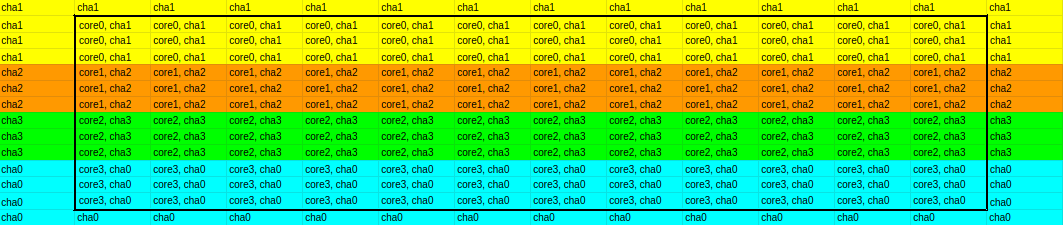
这个矩阵代表A矩阵和B矩阵。在这里,请注意,最外层的单元实际上是“鬼单元格”,没有线程要更新这些单元格的值,这就是为什么没有为这些单元格分配核心数字的原因。在图像中,"core“实际上是”绑定到核心x的线程“,所以这里的核心表示线程。此外,可以从图像中推断出,我的目标是尽可能多地在内核之间分配负载。
我意识到这样一个事实:我通过这样创建一个定制的矩阵来牺牲缓存的局部性,而且微基准测试结果显示,由于这个原因,我的版本实际上要慢得多,可能是。在mesh 中创建一个优化的一致性流量--可能并不能弥补我们从非连续内存访问中获得的速度--我可以理解。这是我的实际代码,我使用OpenMP进行并行处理。
#pragma omp parallel num_threads(18)
{
stick_this_thread_to_core(cores[omp_get_thread_num()]);
for(int t = 0; t < T; ++t) {
#pragma omp for collapse(2) schedule(static)
for(auto i = 1; i < N - 1; ++i) {
for(auto j = 1; j < N - 1; ++j) {
*B[i][j] = 0.2 * (*A[i][j] + *A[i][j-1] + *A[i][1+j] + *A[1+i][j] + *A[i-1][j]);
}
}
#pragma omp for collapse(2) schedule(static)
for(auto i = 1; i < N - 1; ++i) {
for(auto j = 1; j < N - 1; ++j) {
*A[i][j] = 0.2 * (*B[i][j] + *B[i][j-1] + *B[i][1+j] + *B[1+i][j] + *B[i-1][j]);
}
}
}
}通过从top命令进行检查并按1,我可以看到绑定是成功的,并且内核都很忙。
但是,这里有一个奇怪的部分:我不是像上面那样构造矩阵,而是创建一个完全随机的矩阵(再次以double* AN的形式),在这个矩阵中,我要放置到矩阵中的连续缓存行中的内存地址的分配CHA是不一样的(Sidenote:驻留在同一缓存行中的内存地址的一致性将始终由相同的CHA管理)。因此,我认为我不仅牺牲了缓存的局部性,而且还破坏了整个网状结构的一致性。我原以为在这个矩阵上使用jacobi 2d模板会产生最坏的结果,但这并不是总是的情况。假设步骤计数(T)为20'000,N为1000,这个“随机矩阵”比“查感知矩阵”的延迟要好,我只是无法理解这个结果。另一方面,当T是相同的,N是500时,“cha感知矩阵”比“随机矩阵”产生更好的结果。当N为50时,“随机矩阵”更好。在某些情况下,有哪些可能的因素使得这个“随机矩阵”表现得更好呢?
服务器我运行的微基准是Skylake (R) Xeon(R) Gold 6154,启用了18个核心。它只有一个插座。Turbo是在服务器上启用的,并且有16个独立的内核,这意味着OS只能使用其中两个用于调度目的。我使用g++编译,没有优化,也没有-march=native和-fopenmp标志。
我确信CHA-address映射是正确的,因为我已经实现了一种用2种截然不同的方法计算映射的方法,而且它们都提出了相同的映射。
linux工具是否有益于精确定位到底是什么情况呢?
希望我能清楚地解释这个问题,致以最良好的问候。
回答 2
Stack Overflow用户
发布于 2022-03-27 09:20:41
性能计数器确实会为您提供更多关于实际发生的事情的线索。
这个问题真的很复杂,我花了好几年的时间研究它,结果参差不齐。有一个提示(这可能是你所拥有的问题,也可能不是你所拥有的问题):您认为在附近CHA中找到的一致性信息实际上可能是由于窥探过滤器冲突而丢失的一致性信息(对于附近的CHAs,这不是问题所在)(请参阅John McCalpin在这方面的工作)。
Stack Overflow用户
发布于 2022-03-27 17:32:12
即使是单线程情况,这里的分析也不容易。 当我在做相关的实验时,将内存映射到同一个位置的L3片时,我必须非常小心地确保映射到本地L3的地址列表足够小,可以保存在本地L1D+L2缓存中。在您的实现中,位置信息存储在用于间接的额外指针中。因为这个额外的存储空间不会被“位置感知”,所以它也需要足够小,以便L1+L2-缓存,否则它将产生不必要的交叉芯片读取通信量。 在运行这类代码时禁用HW预取程序也很重要--它们将非常积极地获取连续地址,这些地址将始终映射到非本地L3缓存片。 一旦解决了这两个问题,就可以构建OpenMP版本。最好不要使用OpenMP数据并行模型,在这种模型中,OpenMP在一组固定的线程上分布任意大小的循环。相反,创建一个简单的OpenMP并行循环,其中循环索引是线程号,那么循环的每一次迭代都将是一个线程,运行为L3局部性优化的单线程代码的独立副本。这种方法的另一个优点是很容易对代码进行测试,这样您就可以独立地测量每个线程的执行时间--寻找线程启动时间、线程执行持续时间和线程执行后障碍等待时间的变化。在OpenMP并行构建之前和之后,我在“主”线程中使用RDTSCP --在Intel处理器中,TSC在单个套接字中紧密同步,这样您就可以准确地比较跨核的TSC时间。这种方法将使您能够找到总体性能被线程子集降低的情况--这是由于缓存冲突或内存争用导致性能问题的一个共同特征.
https://stackoverflow.com/questions/71580417
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号