
用于银行事务分析的Regex
如何从以下格式的文本表中解析和提取4个重要列?这些是使用Ruby的pdf-reader包从PDF中提取的银行事务行项目--正如您可以看到的那样,列之间的间距在不同列之间非常不规则。
11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30
11/4 Recurring Payment authorized on 11/01 Digitalocean.Com 12.00
11/4 Purchase authorized on 11/01 Google *Gsuite_Get 24.00
11/4 Purchase authorized on 11/02 Amazon Web Service 460.15
11/4 Purchase authorized on 11/02 Amazon Web Service 8.07 2,903.09
11/5 Recurring Payment authorized on 11/03 Atlassian 15.00 2,888.09
11/6 Recurring Payment authorized on 11/04 Pipedrive Inc NY NY 24.00 2,864.09
11/12 Foobar Retail Dis 211011 ABCDEFGH 8,031.44
11/12 Wire Trans Svc Charge - Sequence: 999999999999 Srf# 45.00
11/12 WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC 5,000.00 5,850.53
11/14 Purchase authorized on 11/13 Microconf Microconf.Com MN 100.00 5,702.53上述交易是从银行PDF中提取的,其可视化布局如下

需要通过regexp解析粗体列:
- Date - dd/mm格式-始终存在
- 检查数字-总是空的,可以忽略(字母数字单字?)
- Description --具有日期、数字、特殊字符的文本--始终存在
- Credits -货币金额(仅用于存款)
- 借方-货币金额(仅用于支付)
- 余额-货币量(偶尔出现,不重要)
在提取mm/dd时,我只能到/^(\d{1,2}\/\d{1,2})\s+/mg为止。我应该开始从右边咬住数量,但没有明确的分隔模式!
回答 3
Stack Overflow用户
发布于 2022-02-26 20:55:08
列之间的间距是不规则的,但似乎总是超过2。在这种情况下,您可以使用3捕获组和可选的第4部分,同时也使用捕获组作为借方部分。
^(\d{1,2}\/\d{1,2})\s{2,}(\S.*?)\s{2,}(\d{1,3}(?:,\d{3})*\.\d{2})(?:\s{2,}(\d{1,3}(?:,\d{3})*\.\d{2}))?在各个部分中,模式匹配:
- 字符串的
^开始 (\d{1,2}\/\d{1,2})\s{2,}捕获组1匹配1,2位数字/1,2位数字和2个或更多空格字符(\S.*?)\s{2,}捕获组2至少匹配一个非空白字符,并尽可能至少匹配字符,直到下一次出现2个或更多空格字符为止。(\d{1,3}(?:,\d{3})*\.\d{2})捕获组3匹配数字格式(?:非捕获群\s{2,}匹配2或更多空格字符(\d{1,3}(?:,\d{3})*\.\d{2})捕获组4,匹配数字格式
)?关闭非捕获组并使其成为可选的
Stack Overflow用户
发布于 2022-02-26 19:23:13
假设您的目标是csv/电子表格条目
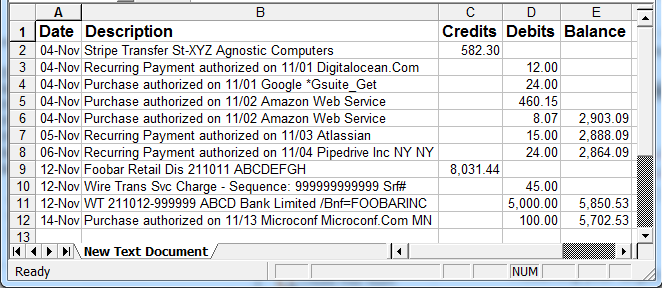
最好是分阶段处理任务,我喜欢的目标格式是电子表格的CSV。
TL;DR见最后的评论
11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30
11/4 Recurring Payment authorized on 11/01 Digitalocean.Com 12.00
11/4 Purchase authorized on 11/01 Google *Gsuite_Get 24.00
11/4 Purchase authorized on 11/02 Amazon Web Service 460.15
11/4 Purchase authorized on 11/02 Amazon Web Service 8.07 2,903.09
11/5 Recurring Payment authorized on 11/03 Atlassian 15.00 2,888.09
11/6 Recurring Payment authorized on 11/04 Pipedrive Inc NY NY 24.00 2,864.09
11/12 Foobar Retail Dis 211011 ABCDEFGH 8,031.44
11/12 Wire Trans Svc Charge - Sequence: 999999999999 Srf# 45.00
11/12 WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC 5,000.00 5,850.53
11/14 Purchase authorized on 11/13 Microconf Microconf.Com MN 100.00 5,702.53第一,我们可以瞄准更大的差距,所以选择一个合适的宽度,不要担心交错的问题,它们以后会被解决。要成为??.??,我们要么需要保护现有的逗号,所以用另一个未使用的符号(比如~ )替换那些逗号,或者使用货币最好在数字之间删除它们。
用虚拟扩展替换所有行尾,如果列太多,如果没有数字,那么就使用??.?? ??.?? (是的,在本例中,我们假设在1000下面,不能使用,#或*)
这样11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30就变成了11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30 ??.?? ??.??
11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30 ??.?? ??.??
11/4 Recurring Payment authorized on 11/01 Digitalocean.Com ??.?? 12.00 ??.?? ??.??
11/4 Purchase authorized on 11/01 Google *Gsuite_Get ??.?? 24.00 ??.?? ??.??
11/4 Purchase authorized on 11/02 Amazon Web Service ??.?? 460.15 ??.?? ??.??
11/4 Purchase authorized on 11/02 Amazon Web Service ??.?? 8.07 2903.09 ??.?? ??.??
11/5 Recurring Payment authorized on 11/03 Atlassian ??.?? 15.00 2888.09 ??.?? ??.??
11/6 Recurring Payment authorized on 11/04 Pipedrive Inc NY NY ??.?? 24.00 2864.09 ??.?? ??.??
11/12 Foobar Retail Dis 211011 ABCDEFGH 8031.44 ??.?? ??.??
11/12 Wire Trans Svc Charge - Sequence: 999999999999 Srf# ??.?? 45.00 ??.?? ??.??
11/12 WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC ??.?? 5000.00 5850.53 ??.?? ??.??
11/14 Purchase authorized on 11/13 Microconf Microconf.Com MN ??.?? 100.00 5702.53 ??.?? ??.??现在我们可以将剩余的不规则空白作为目标,将所有较大的空间替换为适当的2或3个空格(通常为2,但请注意使用双空格的任何描述)。
11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30 ??.?? ??.??
11/4 Recurring Payment authorized on 11/01 Digitalocean.Com ??.?? 12.00 ??.?? ??.??
11/4 Purchase authorized on 11/01 Google *Gsuite_Get ??.?? 24.00 ??.?? ??.??
11/4 Purchase authorized on 11/02 Amazon Web Service ??.?? 460.15 ??.?? ??.??
11/4 Purchase authorized on 11/02 Amazon Web Service ??.?? 8.07 2903.09 ??.?? ??.??
11/5 Recurring Payment authorized on 11/03 Atlassian ??.?? 15.00 2888.09 ??.?? ??.??
11/6 Recurring Payment authorized on 11/04 Pipedrive Inc NY NY ??.?? 24.00 2864.09 ??.?? ??.??
11/12 Foobar Retail Dis 211011 ABCDEFGH 8031.44 ??.?? ??.??
11/12 Wire Trans Svc Charge - Sequence: 999999999999 Srf# ??.?? 45.00 ??.?? ??.??
11/12 WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC ??.?? 5000.00 5850.53 ??.?? ??.??
11/14 Purchase authorized on 11/13 Microconf Microconf.Com MN ??.?? 100.00 5702.53 ??.?? ??.??最后添加标题,用逗号分隔符替换,然后删除?
Date,Description,Credits,Debits,Balance,,,
11/4,Stripe Transfer St-XYZ Agnostic Computers,582.30,,
11/4,Recurring Payment authorized on 11/01 Digitalocean.Com,,12.00,,
11/4,Purchase authorized on 11/01 Google *Gsuite_Get,,24.00,,
11/4,Purchase authorized on 11/02 Amazon Web Service,,460.15,,
11/4,Purchase authorized on 11/02 Amazon Web Service,,8.07,2903.09,,
11/5,Recurring Payment authorized on 11/03 Atlassian,,15.00,2888.09,,
11/6,Recurring Payment authorized on 11/04 Pipedrive Inc NY NY,,24.00,2864.09,,
11/12,Foobar Retail Dis 211011 ABCDEFGH,8031.44,,
11/12,Wire Trans Svc Charge - Sequence: 999999999999 Srf#,,45.00,,
11/12,WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC,,5000.00,5850.53,,
11/14,Purchase authorized on 11/13 Microconf Microconf.Com MN,,100.00,5702.53,,在导入到电子表格时,标题和可能的货币都需要样式。
事后我意识到你所要做的就是
- 删除逗号
- 在大的空格中插入一个虚拟列3(甚至一个~)
- 将空间缩小到2x空间,然后用逗号替换这2个空格。
- 移除虚拟条目,例如~
- 添加标头
Date,Description,Credits,Debits,Balance
剩下的会照顾好自己。
Stack Overflow用户
发布于 2022-02-26 22:09:49
TL;DR
您的主要问题是,如果您在从PDF中解析字符串数据之后处理它,那么很难确定哪个位置元素对应于哪个字段。您确实应该在PDF解析时打开一个关于如何解决这个问题的单独问题,而不是在PDF解析阶段之后尝试解析文本。尽管如此,下面是一个解决方案,它适用于您提供的有限示例,并且至少可以让您开始尝试进行字符串解析。
假设和实例
从您的示例来看,您的格式似乎有一些隐含的业务规则:
- 有些字段总是存在(例如日期和描述)。
- 每行只有一笔借方或贷方。
- 每一行最多有4/5的填充字段。
但是,即使" balance“并不重要,如果没有参考某些现有余额或解析输出中明确定义的空格数,您也无法真正判断某事是贷项还是借方,所以您需要修复输入数据或进行PDF解析,以确保始终有一个平衡(在PDF解析时可以计算),或者确保您知道PDF布局中的特定字段宽度或PDF中解析的输出。
虽然只需要为实际用例更新部分解决方案,但您可以创建一个Struct或其他对象来保存数据,然后根据每个事务所包含的字段之间的字段或空格作出额外的解析决策。下面是一个潜在的解决方案。
使用PDF解析中的字符串的示例
注意:在不影响结果的情况下,下面的代码示例被积极包装为60个字符,以减少StackOverflow代码块中的侧滚动。请随意重新编写代码,以适应您自己的风格选择。
我们将首先将您在原始文章中提供的解析文本存储在这里的文档中,以执行本代码示例的其余部分。
text_extracted_from_pdf = <<~'EXTRACTED_TEXT'
11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30
11/4 Recurring Payment authorized on 11/01 Digitalocean.Com 12.00
11/4 Purchase authorized on 11/01 Google *Gsuite_Get 24.00
11/4 Purchase authorized on 11/02 Amazon Web Service 460.15
11/4 Purchase authorized on 11/02 Amazon Web Service 8.07 2,903.09
11/5 Recurring Payment authorized on 11/03 Atlassian 15.00 2,888.09
11/6 Recurring Payment authorized on 11/04 Pipedrive Inc NY NY 24.00 2,864.09
11/12 Foobar Retail Dis 211011 ABCDEFGH 8,031.44
11/12 Wire Trans Svc Charge - Sequence: 999999999999 Srf# 45.00
11/12 WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC 5,000.00 5,850.53
11/14 Purchase authorized on 11/13 Microconf Microconf.Com MN 100.00 5,702.53
EXTRACTED_TEXT我们还将定义一些常量,用于解析PDF解析后提取的文本,并定义一个结构类来保存解析每一行文本的结果。您可能需要根据实际数据来调整这些数据。
# This describes what a currency item looks like after your
# PDF parse.
MONEY_FMT = /\b[\d,]+\.\d{2}\b/
# Make some assumptions about fixed-width fields. These
# values seem reliable given the sample string data from
# your original post.
LN_START_TO_LAST_CRED_CHR = /^.{92}\.\d{2}$?/
LN_START_TO_END_OF_DEBIT = /^.{93,}#{MONEY_FMT}$?/
Transaction = Struct.new(:date, :description, :credit,
:debit, :balance, keyword_init:
true)现在,我们从PDF解析中读取输出,尝试分析结果字符串。使用Ruby3.1.1,并积极包装代码以尽量减少StackOverflow上的侧滚动:
transactions = []
text_extracted_from_pdf.each_line do
fields = _1.split /\s{2,}/
date, description = fields.shift 2
balance = fields.pop.chomp if fields.count == 2
# This violates our rule of 4/5 populated fields.
raise "too many fields remaining: #{fields.count}" unless
fields.count == 1
# Match on characters from start of line to end of credit.
credit =
fields.pop.chomp if _1.match? LN_START_TO_LAST_CRED_CHR
# Match on characters from start of line to end of debit.
debit =
fields.pop.chomp if _1.match? LN_START_TO_END_OF_DEBIT
transactions << Transaction.new({date: date, description:
description, credit:
credit, debit: debit,
balance: balance})
end预期结果
事务数组现在应该包含事务对象的集合,您可以根据需要迭代这些对象。例如,上面的示例代码使用以下Struct对象填充事务数组:
transactions
#=>
[#<struct Transaction date="11/4", description="Stripe Transfer St-XYZ Agnostic Computers", credit="582.30", debit=nil, balance=nil>,
#<struct Transaction date="11/4", description="Recurring Payment authorized on 11/01 Digitalocean.Com", credit=nil, debit="12.00", balance=nil>,
#<struct Transaction date="11/4", description="Purchase authorized on 11/01 Google *Gsuite_Get", credit=nil, debit="24.00", balance=nil>,
#<struct Transaction date="11/4", description="Purchase authorized on 11/02 Amazon Web Service", credit=nil, debit="460.15", balance=nil>,
#<struct Transaction date="11/4", description="Purchase authorized on 11/02 Amazon Web Service", credit=nil, debit="8.07", balance="2,903.09">,
#<struct Transaction date="11/5", description="Recurring Payment authorized on 11/03 Atlassian", credit=nil, debit="15.00", balance="2,888.09">,
#<struct Transaction date="11/6", description="Recurring Payment authorized on 11/04 Pipedrive Inc NY NY", credit=nil, debit="24.00", balance="2,864.09">,
#<struct Transaction date="11/12", description="Foobar Retail Dis 211011 ABCDEFGH", credit="8,031.44", debit=nil, balance=nil>,
#<struct Transaction date="11/12", description="Wire Trans Svc Charge - Sequence: 999999999999 Srf#", credit=nil, debit="45.00", balance=nil>,
#<struct Transaction date="11/12", description="WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC", credit=nil, debit="5,000.00", balance="5,850.53">,
#<struct Transaction date="11/14", description="Purchase authorized on 11/13 Microconf Microconf.Com MN", credit=nil, debit="100.00", balance="5,702.53">]验证您的字符串分析
当人们对格式化或代码的逻辑做出假设时,很多事情都可能出错。如果您想验证您的Struct对象,可以在集合中迭代以识别错误的分析,或者可以选择在上面的解析循环中记录、警告或引发异常。
# If you have parsed both a credit and a debit on the same line,
# something's wrong.
transactions.map do
warn "bad parse for #{_1}" if _1.credit && _1.debit
end.compact!
#=> []您也可以使用Array#reject!从没有正确解析的事务中直接删除项,而不是简单地在上面的#each_line循环中跳过将它们添加到集合中。如何识别和处理一个糟糕的解析实际上取决于您自己;这只是许多方法中的一种,目的是说明您需要在代码中的某个地方验证每个PDF或string解析的结果。
https://stackoverflow.com/questions/71277325
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号