
如何使TEXTJOIN在溢出范围内工作
如何使TEXTJOIN在溢出范围内工作
提问于 2021-12-08 07:14:01
我有以下的数据C4:D10作为输入。单元格G4有公式=UNIQUE(C4:C10),单元格H4有公式=TEXTJOIN(", ",TRUE,IF($C$4:$C$10=G4,$D$4:$D$10,"")),单元H5有=TEXTJOIN(", ",TRUE,IF($C$4:$C$10=G5,$D$4:$D$10,""))。
H4和H5中的值是我所需要的:它们结合了每个类别的文本。但是,我更喜欢用TEXTJOIN和G4#编写一个数组公式。我试过=TEXTJOIN(", ",TRUE,IF($C$4:$C$10=G4#,$D$4:$D$10,"")),但效果不太好。
有人知道如何在G4#上编写这样一个公式来实现相同的值吗?
PS:如果没有其他选择,使用LAMBDA和助手函数的公式仍然会受到赞赏。
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-12-08 12:55:35
您可以通过以下公式来实现这一点:
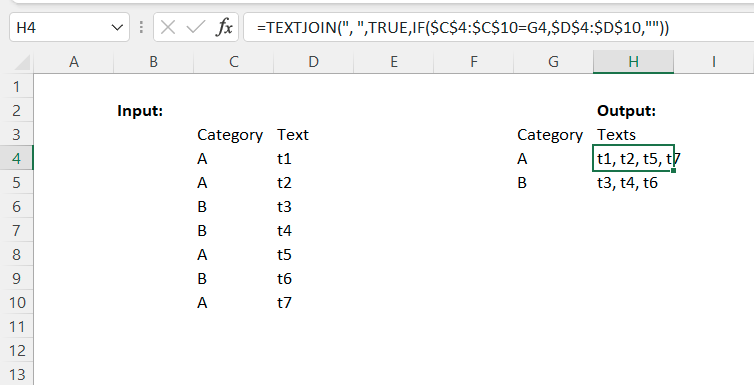
=LET(data,FILTER(C:D,C:C<>""),
dataC1,INDEX(data,,1),
dataC2,INDEX(data,,2),
UdataC1,G4#,
v,UNIQUE(TRANSPOSE(IF(dataC1=TRANSPOSE(UdataC1),dataC2,"")),1),
seqrv,SEQUENCE(ROWS(v)),
sep,", ",
x,MMULT((LEN(v)+LEN(sep))*(v<>""),SIGN(SEQUENCE(COLUMNS(v))))-LEN(sep),
y,MMULT(--(TRANSPOSE(seqrv)<seqrv),x+LEN(sep)-1)+seqrv,
IFERROR(MID(TEXTJOIN(sep,1,v),y,x),""))
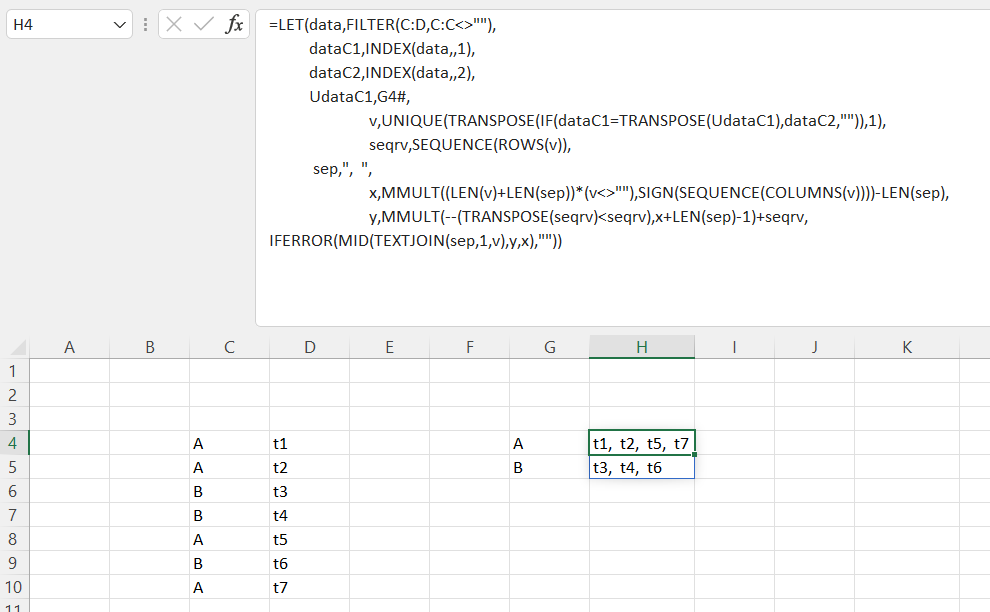
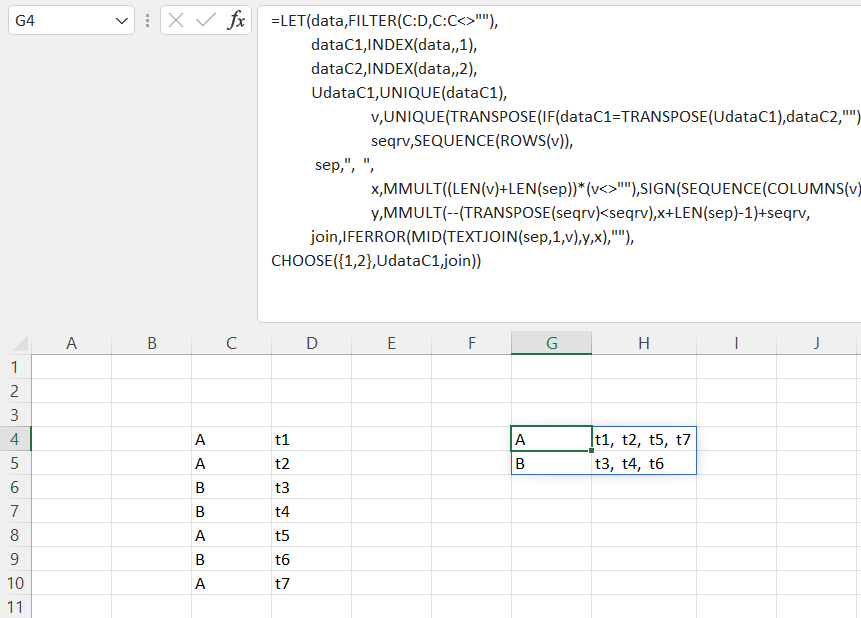
或者你可以一次又一次地用:
=LET(data,FILTER(C:D,C:C<>""),
dataC1,INDEX(data,,1),
dataC2,INDEX(data,,2),
UdataC1,UNIQUE(dataC1),
v,UNIQUE(TRANSPOSE(IF(dataC1=TRANSPOSE(UdataC1),dataC2,"")),1),
seqrv,SEQUENCE(ROWS(v)),
sep,", ",
x,MMULT((LEN(v)+LEN(sep))*(v<>""),SIGN(SEQUENCE(COLUMNS(v))))-LEN(sep),
y,MMULT(--(TRANSPOSE(seqrv)<seqrv),x+LEN(sep)-1)+seqrv,
join,IFERROR(MID(TEXTJOIN(sep,1,v),y,x),""),
CHOOSE({1,2},UdataC1,join))
在马克·菲茨帕特里克的this answer的帮助下
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70271223
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号