IM分布式架构系列(19) 小小的在线状态绿点|牵出一整套分布式状态难题
原创
IM分布式架构系列(19) 小小的在线状态绿点|牵出一整套分布式状态难题
原创
拉丁解牛说技术
发布于 2026-07-03 00:00:53
发布于 2026-07-03 00:00:53
一转眼写了19篇,写着也乏味,在这AI浪潮下,万物皆可AI化。准备写AI进阶系列相关的内容,蹭一下热点。
传承几十年的手写代码,在AI的冲击下,已经被称为:古法编程。
一、在线状态为什么是个难题
1.1 让在线状态翻车的三个场景
二、存储选型与推/拉模型
三、某钉如何设计
四、如何把在线状态做稳
一、在线状态为什么是个难题
产品经理:「隔壁老王的IM,头像下面有个绿点,咱们也加一个,easy吧?」如果对方只想到:存个布尔值,上线置 true、下线置 false,一张 Redis 表搞定,半天的活,那确实easy!
而实际上,在IM业务场景里,尤其是服务端的IM架构设计,难的是它要在「所有看得见它的人」眼里同时、实时、准确地亮起或熄灭。任何一件没处理好,用户都会觉得「这个在线状态不准」——而不准比没有更糟,因为它误导人。
IM的在线状态(Presence)核心问题在于:系统怎么知道某用户此刻在不在线、在哪几个端、对外该显示成什么。 它的位置很特殊——既是给消息投递用的内部路由依据,又是给终端用户看的产品数据。
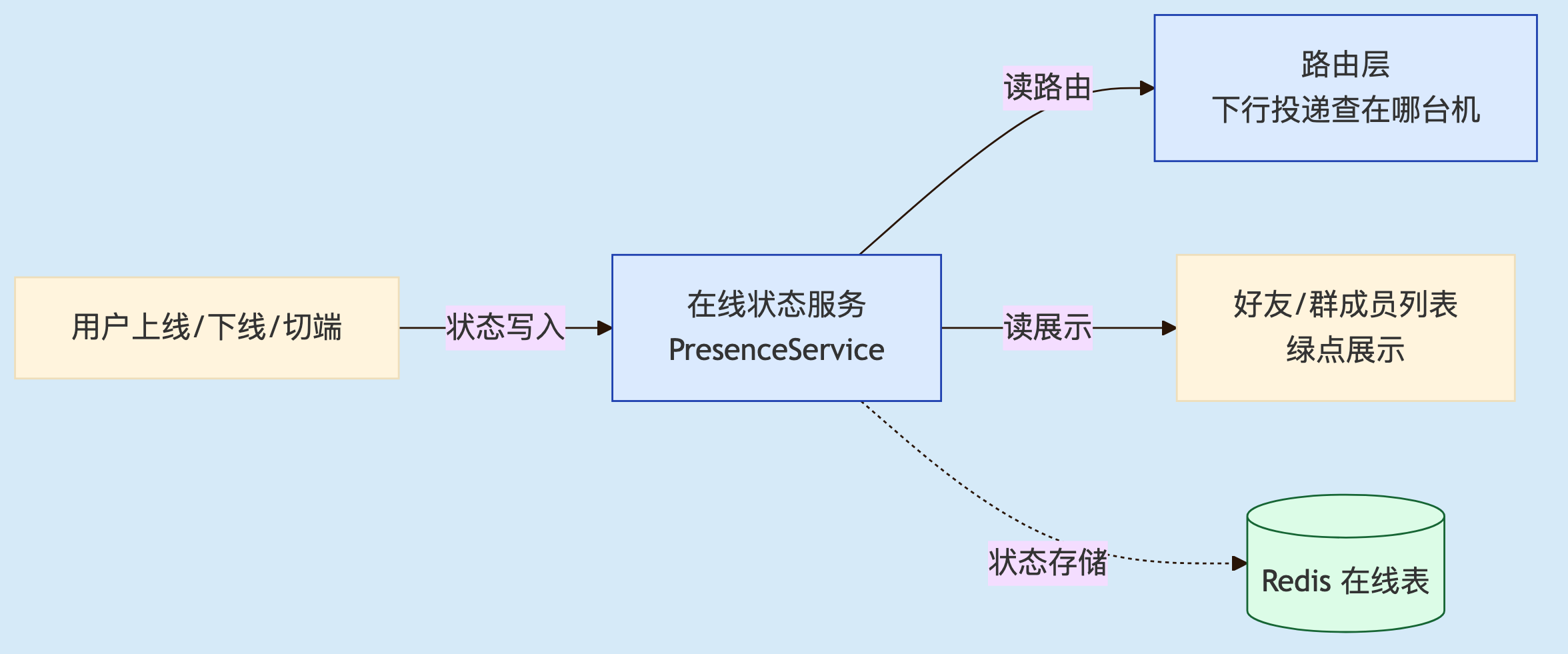
在线状态服务的两个下游:投递路由(内部)与状态展示(产品)
1.1 让在线状态翻车的三个场景
小小的一个在线状态,到底能触发哪些分布式问题:
场景一:上线扇出风暴。 一个 500 好友的用户打开 App,若系统老实把「我上线了」推给每个在线好友,这一下就是上百个推送;早高峰几十万人同时上线,这个扇出会把推送链路瞬间顶起来。状态本身一个字节,扇出却是 O(好友数)。
场景二:状态自己不会熄灭。 上线时置成在线,但「下线」往往收不到——手机没电、进电梯断网、进程被杀,都不会规矩地发一条「我下线了」。只靠显式事件维护,「永远在线」的幽灵状态越攒越多,运营某天会发现在线人数虚高一截,全是没熄灭的绿点。
场景三:多端各说各话。 手机、电脑同时在线,电脑退出后整体状态应该还是「在线」(手机还在)。若状态只是用户级布尔值,电脑退出一置 false,手机端就被误判离线、消息走离线推送——用户明明盯着手机屏幕,却收到一条厂商推送。多端共存让「在线」从布尔值变成一组按设备维度的状态。
二、存储选型与推/拉模型
在线状态技术选型,这一层要考虑点:
写要快、扛抖动(早高峰每秒上万次上下线/切端);
读要全局可见(任意接入机、任意入口读到同一份);
状态能自愈(收不到下线事件时自己过期);
扩散要可控(一次变更的通知量不能随好友/群规模线性炸开);
多端要可分辨(能区分在哪几个端在线)。
2.1 状态存哪里:四种数据结构的取舍
放 Redis 几乎是中等规模项目的共识——内存级延迟扛得住高频变更,又全局可见。真正要纠结的是用哪种数据结构组织这份状态,它直接决定了多端能不能分辨、过期好不好做、查询快不快。四种常见做法对比:
方案 | 结构 | 多端可分辨 | 过期粒度 | 适用 |
|---|---|---|---|---|
用户级 String | online:<uid> -> 1/0 | 否 | 整个用户 | 最简单,不支持多端 |
设备级 String | online:<uid>:<device> -> host | 是(靠 key 拆分) | 每设备独立 TTL | 多端共存的主流落点 |
用户级 Hash | online:<uid> -> {mobile:host, pc:host} | 是(field 区分) | 只能整 key 过期 | 查整人状态快,但过期粒度粗 |
全局 ZSet | online:all -> member=uid, score=ts | 否 | 靠 score 当时间戳扫 | 适合「批量查谁在线」 |
这里的选择具体比较:
Hash的问题, 在于把过期粒度坑了。 用一个 Hash 装下用户所有端的状态,HGETALL 查整人很爽,但 Redis 的过期是 key 级的——没法给某个 field 单独设 TTL。手机端该过期、电脑端不该过期,Hash 分不开,只能在 field 里塞时间戳、读时自己判,等于把过期逻辑搬回应用层。多端的这个不能选。
设备级 String ,是大多数多端 IM 的选择。 一个 <uid>:<device> 一个 key,各自独立 TTL,过期粒度天然对齐设备维度,多端语义干净。代价是查整人状态得按固定 device 列表逐个点查——需要整人视图时在应用层几次点查合并,但比用 Hash 牺牲过期粒度划算。
ZSet 是给「批量查在线」的特化结构:member 设 uid、score 设最后心跳时间戳,一次 ZRANGEBYSCORE 就能筛出「最近 N 秒内有心跳的」,顺便用 score 当过期判据。它不替代设备级 String,是叠在上面的批量读优化,群场景很适合。
2.2 TTL 与心跳续期:怎么让状态自己过期
避免幽灵状态的策略,我们可以采取:不信任显式下线,让状态自己过期:给每条状态记录设一个 TTL,靠心跳续期来「证明我还活着」。
on_user_online(uid, device, host):
SET online:<uid>:<device> = host EX 90// 90 秒过期
on_heartbeat(uid, device):
EXPIRE online:<uid>:<device> 90// 每次心跳把过期时间往后推
on_user_offline(uid, device): // 正常退出走快路径,立刻熄灭
DEL online:<uid>:<device>
// 收不到下线事件也不怕——没心跳,90 秒后 key 自动消失(TTL 兜底) 这里的设计,有几个要点:TTL 要比心跳间隔大、但不能大太多——设小了一次心跳丢失就误判离线,设大了幽灵状态滞留太久、投黑洞的窗口变长,经验上取心跳间隔 2~3 倍是稳妥起点,弱网往大调。显式下线可以当做「快路径」——正常退出主动删 key 立刻熄灭,然后用TTL 兜底,专治发不出下线事件的异常退出。但是要注意:别让续期变成写风暴——百万连接每隔几十秒一次 EXPIRE 就是每秒上万次写,最好把续期和心跳处理合成一次操作。
2.3 单聊在线状态:一次点查的代价
单聊最简单:A 给 B 发消息,系统要知道 B 在不在线,决定走实时投递还是离线兜底——一次对 B 状态的点查。
on_send_message(to=B):
states = mget(online:B:mobile, online:B:pc, online:B:web)
if any(states is not null):
route_online(B, states)// 在线,走长连投递
else:
route_offline(B) // 离线,写离线盒子 + 触发三方推送这个看着很简单,但有两个容易踩的点:
「查不到」不等于「确定离线」。 Redis 抖动时点查可能返回空,但用户其实在线。无差别地把「查空」当「离线」,一抖动就把一批活用户判离线、消息全转离线推送,瞬时打爆推送链路。
展示状态和投递状态可以不一致。 给 B 看的绿点和「投消息时查的状态」是两份用途:展示能容忍几秒延迟。
2.4 好友列表:推 vs 拉与订阅模型
到了好友列表,问题从「查一个人」变成「一个人状态变了,怎么让所有关心他的人知道」——这是在线状态最经典的一道选择题:推还是拉。两种朴素方案:
拉(轮询)。 客户端定期问「我这些好友谁在线」。服务端逻辑极简、不主动扩散,但状态变化最多有一个轮询周期的延迟,且状态没变时全是无效请求,在线用户一多就是一片空转。
推。 状态一变就把变更推给所有「在线的反向好友」。注意是反向好友——「把他加为好友的人」,不是「他的好友」,单向关注的产品里这两个集合完全不同,很容易写反。推的优点是实时,缺点藏在高峰期的量级里。
所以好友状态很少用纯推或纯拉选择考虑,在于按实时性诉求折中:
策略 | 实时性 | 服务端压力 | 适用 |
|---|---|---|---|
纯轮询拉 | 差(一个周期延迟) | 无效请求多 | 对实时性不敏感、好友少 |
纯推(推给反向好友) | 好 | 扩散系数高,易雪崩 | 反向好友少、活跃度低 |
登录全量拉 + 在线增量推 | 较好 | 扩散收窄到「在场的人」 | 多数中等规模项目的折中 |
我们的经验是落在第三种:登录时一次性全量拉回当前好友状态(解决冷启动),之后只对「此刻正看着好友列表的在线用户」推增量——没在看的人等下次拉时自然就对了。
把这个收窄思路工程化,就是订阅模型:谁想实时知道某人状态就显式订阅,状态变更只推给订阅者,而不是全部反向好友。
subscribe(viewer=A, targets=[B, C, D...]) // A 打开列表/进聊天页,订阅这几个人
on_status_change(uid=B):
subscribers = get_subscribers(B) // 只有此刻订阅 B 的人
push_to(subscribers, B.new_status) // 推给他们,不是 B 的全部反向好友
unsubscribe(viewer=A) // A 离开页面/断开,撤订阅这个方案,可以把扩散的分母从「反向好友总数」换成「当前订阅者数」,后者通常小一两个数量级——大部分好友此刻并没在看你的状态。代价是多维护一份订阅关系、且要随连接生命周期清理,否则又会攒出一批幽灵订阅。
2.5 群在线状态:按需拉取与延时拉取
群比好友更狠:群友的扩散分母在反向好友之上还要再乘「人加的群数 × 每群人数」,一个人上线要通知的群友轻松到数百上千,纯推根本扛不住。
所以群在线状态几乎只能拉,而且不是轮询拉,是按需拉 + 延时拉:只在用户真正点开某个群那一刻才拉这个群的在线状态(按需),且进群拉一次快照就够、看的过程中不必实时刷新群友绿点(延时)。效果是用户主观感觉「实时、一致」,系统却只在真正需要的时刻做一次批量查询,把上千的推送压力转移成进群时一次批量读——这正是前面说的 ZSet 存储的用武之地,一次 ZRANGEBYSCORE 就能把整群在线状态捞出来。
一个反直觉但重要的结论:好友和群友用的是两套机制——好友偏推(实时性诉求高、扩散可控),群友偏拉(扩散太大、实时性诉求没那么高)。决定推还是拉的归根到底是扩散系数。
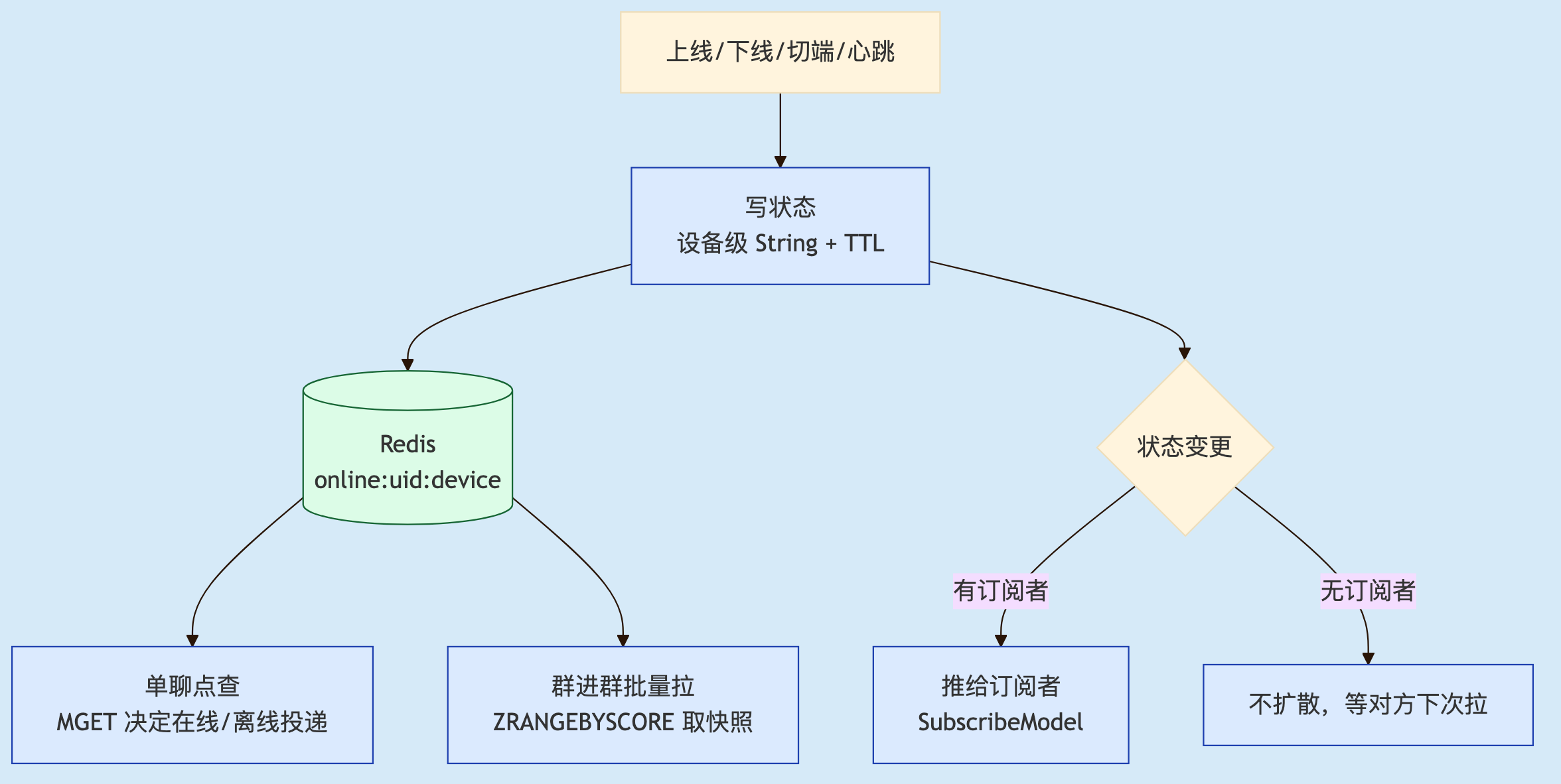
在线状态全貌:设备级存储 + TTL 自愈 + 单聊点查 / 群批量拉 / 订阅式推
三、某钉如何设计
公开资料分享讲在线状态的同步常停在「好友推、群友拉」这个共识,往往只回答了「状态变更通知谁」,没回答另一个在线状态路由问题:在线状态作为投递依据,怎么参与到消息同步决策里。 某钉公开的 DTIM 技术设计在这一半讲得很透——同步服务推消息前先查用户各端在线状态,再决定推哪些端、走自建通道还是三方通知。这是把在线状态当「投递路由」用的典型案例。
3.2 同步服务里的在线状态判定
某钉公开资料里的核心结构是一个同步服务:它给每个用户分配一个 FIFO 的同步队列,把各类需要同步的动作抽象成统一的「同步事件」写进队列(按其框架推断,消息、已读、会话变更、多端红点清除都属于此)。
在线状态在这里扮演推送的开关。有事件要同步时,同步服务先查当前用户各端的在线设备状态再决定怎么发:某些端在线,就从队列捞未同步的增量经长连接推到这些端;全部端离线,就把消息连同「离线用户状态列表」打包成通知事件,转三方通道做厂商推送。
他们的方案关键在于:在线状态不是孤立展示的数据,而是嵌在每一次同步决策里的一个查询——每条消息要不要推、推给哪几个端、推不到时降级到哪条通道都由它决定,这正印证了我们之前说的「投递状态比展示状态更要紧」。
维度 | 详情 |
|---|---|
优势 | 在线判定与同步决策合一,一次判定同时决定推哪端、是否降级三方通道; 按各端在线状态做增量推送,多端语义清晰; 离线时打包「离线用户状态列表」走通知服务兜底,不丢消息 |
代价 | 同步服务与在线判定耦合较深,整套同步队列 + 状态判定复杂度高; 为每用户维护 FIFO 队列与位点是不小的存储成本; |
3.3 推优先模型对在线状态的反向约束
某钉在同步模型上选了「服务端主动推为主」,公开资料称推优先模型(PPM)。理由跟在线状态强相关:拉取间隔很难定(短了压服务端、长了时效差),推拉结合又比纯推多一次 RTT、弱网下增加功耗和失败率;而企业场景里实时性和功耗都是硬指标,所以我们以推为主。
这反过来对在线状态提出更高要求:既然以推为主,「在不在线」就必须判得准——判错成在线消息推进黑洞,判错成离线又白走三方通道。按公开资料描述,某钉的应对是给 PPM 配兜底:消息堆积到阈值就触发 Rebase,客户端转为主动拉取最新位点、服务端跳过这段继续推。这等于承认「在线判定 + 主动推」不可能 100% 可靠,必须留一条「推不动就回退到拉」的逃生通道。
对中小项目的启发不在照搬 PPM,而在这个权衡逻辑:越依赖推、越依赖在线判定的准确性,就越要为「判错了 / 推堆积」准备好回退到拉的兜底。
四、如何把在线状态做稳
我们回到工程实践的现实:在线状态在中小规模 IM 里最容易在哪儿出问题、怎么做得更稳。
4.1 实时性
做在线状态之前,先想清楚一个产品问题:这个绿点到底要多实时。
倾向是把「投递用的在线判定」和「展示用的在线状态」拆成两套要求:投递判定要准、要有降级,值得多花成本;展示状态能容忍秒级延迟和短暂不准,用最省的拉取就够。绑在一起用同一套高强度同步满足,是常见的过度设计。
4.2 状态机扩张
很多产品的在线状态不止「在线/离线」,还有忙碌、离开、隐身、勿扰。一个反共识观点:这些扩展状态绝大多数应是客户端展示态,不该进服务端的投递判定。
理由是「隐身」「离开」对投递没有区别——隐身用户的消息照样要投到他在线的端,只是别人看不到绿点。把隐身做进服务端在线表,就得维护「真实状态」和「对外展示状态」两份,还要处理「对 A 隐身对 B 不隐身」这种按关系区分的可见性,复杂度陡增。更工程化的做法是:服务端权威状态只管「在不在线、在哪几个端」这个投递事实,隐身/离开/勿扰作为独立展示标志位由展示层合并——两者解耦,状态机才不会越长越乱。
4.3 扩散风暴如何兜底
早高峰集中上线那一波扩散最危险:即使上了订阅模型,几十万人同一分钟上线,订阅者推送的瞬时量依然可能顶起链路。三个兜底:一是状态变更合并,对弱网抖动出来的「上线又下线」做个去抖动窗口只推最终态,时间窗口 200~500ms 既能滤掉大部分抖动、又不明显拖慢正常上下线;二是扩散降级,推送积压时把群友/低优先级订阅者降级成拉,优先保好友这类高价值订阅;三是分级实时性,聊天页正在交互的对象实时推,好友列表允许批量、延迟、合并推。把实时性按场景分级,而非所有状态追求同一档。
4.4 可观测:在线状态的对账
在线状态最难的地方在于它没有天然的正确性校验——很难知道此刻在线数准不准,所以可观测要专门设计。至少盯三个指标:在线数与连接数的比值,两者应大致吻合,如果持续超过 1.2~1.5 往往就是幽灵状态在堆积的信号;状态查询的空返回率,单聊点查返回空的比例突然飙升往往是 Redis 抖动或批量误过期,即将误判一片的前兆;扩散量,每次变更实际产生的推送数远超订阅者规模,说明订阅关系没清干净或扩散范围算错了。
在线状态看着是一个绿点,本质是一道IM扩散与状态过期的权衡题。架构选择的终点,就是平衡术的境界。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号