存储三兄弟:块存储、文件存储、对象存储,到底怎么选?一篇讲透

存储三兄弟:块存储、文件存储、对象存储,到底怎么选?一篇讲透

悠悠12138
发布于 2026-07-02 13:40:34
发布于 2026-07-02 13:40:34
做运维这些年,被问得最多的问题之一就是:"我们这个业务场景,到底该用块存储、文件存储还是对象存储?"
说实话,每次听到这个问题我都挺头疼的——不是不会答,而是这东西它不是一句话能说清楚的。你得结合业务场景、数据类型、性能要求、预算限制这些因素综合来看。很多人上来就问"哪个最好",这就好比你问"轿车、货车、客车哪个最好"一样,得看你拉什么货、走什么路。
今天这篇文章,我把这些年踩过的坑、趟过的雷、生产环境里实际用过的方案,都揉在一起讲讲。不讲那些云里雾里的概念,就讲人话,讲实际怎么用。
先搞清楚一个根本问题:数据是怎么存的?
在聊三种存储之前,有个底层的东西得先想明白——不管什么存储,数据最终都是落在磁盘上的。硬盘它不认识什么文件、什么对象,它只知道扇区、磁道这些物理结构。那为什么会有块、文件、对象这三种不同的存储方式呢?
说白了,这三种存储就是三种不同的"数据组织方式",或者说三种不同的"看数据的视角"。你站在不同的高度去看同一份数据,它呈现出来的形态是不一样的。
打个比方,同样是一堆砖头(数据):
- • 块存储就像你只管把砖头一块块码好,编上号,谁要哪块砖你给哪块,至于这些砖头拼成什么房子,那是上层的事
- • 文件存储就像你把砖头按房间、楼层组织好,要找客厅的砖头,你就走"1楼→客厅"这个路径去找
- • 对象存储就像你把每块砖头扔进一个大仓库,贴个标签写上"这是张三家客厅东南角的砖头",要的时候报标签号就行
这个比喻可能不太精准,但能帮你快速建立直觉。下面我一个一个展开讲。
块存储:最底层的狠角色
它到底是个什么东西
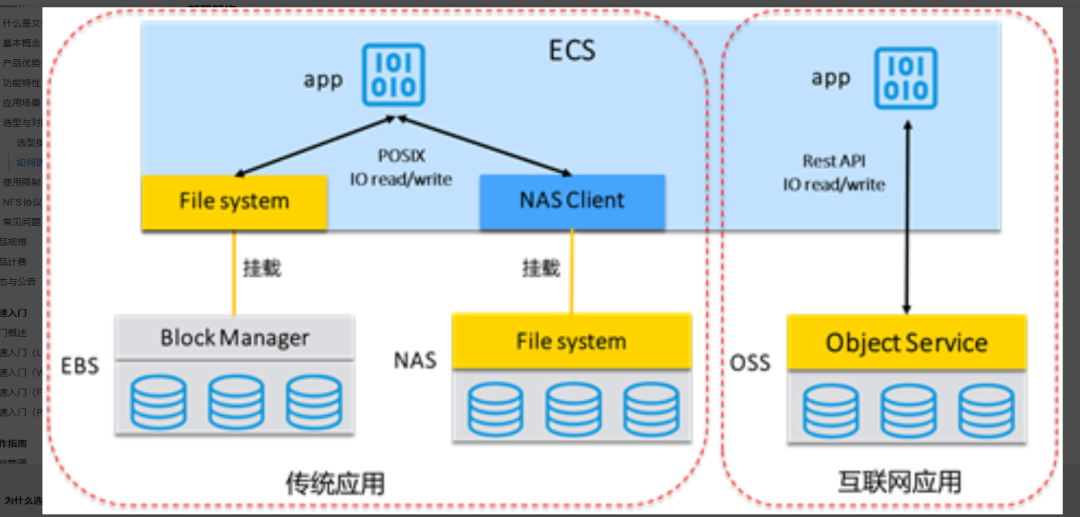
块存储是三种存储里最接近物理硬件的。它把数据切成固定大小的块(block),每个块都有一个唯一地址,存储系统通过这个地址来定位和读写数据[1]。
你不需要关心数据存在哪个盘上,块存储系统会帮你搞定这些。对上层操作系统来说,块存储呈现出来就是一个裸设备,就像你插了一块硬盘到服务器上一样。操作系统拿到这个裸设备之后,需要自己格式化文件系统,然后才能用。
我之前在一家公司搞虚拟化平台,ESXi 主机上挂的就是 SAN 存储分出来的 LUN。说白了那个 LUN 就是一个块设备,ESXi 在上面创建 VMFS 文件系统,然后虚拟机的磁盘文件(vmdk)就放在这个 VMFS 上。多个 ESXi 主机可以同时访问同一个 VMFS 卷,这就是块存储在虚拟化场景下的典型用法[4]。
块存储的脾气
性能是块存储最大的优势。因为它离硬件最近,中间没有文件系统那一层开销,数据读写的延迟非常低,IOPS 也高[3]。你想想,数据库这种对延迟极其敏感的东西,每次查询都要读写磁盘,如果中间多了文件系统的转换,那延迟就上去了。所以像 MySQL、Oracle 这些数据库,基本都跑在块存储上面。
但块存储也有它的问题。它几乎没有元数据的概念——什么是元数据?就是描述数据的数据,比如文件名、创建时间、文件大小这些信息。块存储不管这些,它只管"第1024号块里存了什么数据",至于这个块属于哪个文件、是什么类型的数据,它一概不知[3]。
这就带来一个问题:管理起来比较麻烦。你得自己在上层搞文件系统或者数据库来管理这些数据。而且块存储的成本通常比较高,尤其是企业级 SAN 存储,动不动就几十万上百万[4]。
生产环境里块存储长什么样
说几个实际场景吧。
场景一:数据库存储。 这是最经典的。我们公司之前跑一套 Oracle RAC,底下挂的是 EMC 的 SAN 存储,通过光纤通道(FC)连接。数据库直接读写裸设备,性能杠杠的。IOPS 能做到几万甚至十几万,延迟在亚毫秒级别。你换文件存储试试?分分钟给你卡到怀疑人生。
场景二:虚拟机磁盘。 VMware 环境下,ESXi 主机通过 iSCSI 或 FC 连到 SAN 存储,SAN 分出来一个 LUN,ESXi 把它格式化成 VMFS,虚拟机的磁盘文件就存在上面。这种方案的好处是支持多主机并发访问,做 vMotion 迁移的时候很方便。
场景三:容器持久卷。 现在搞 Kubernetes 的同学应该不陌生。很多 StatefulSet 的持久卷(PV)底层就是块存储。比如 AWS 的 EBS、阿里云的云盘,本质上都是块存储。Pod 挂载一个 EBS 卷,就跟插了一块硬盘一样[4]。
块存储的典型协议
这块顺便提一下,免得有人搞混:
- • iSCSI:通过 TCP/IP 传输 SCSI 命令,成本低,但性能受网络影响
- • FC(Fibre Channel):走光纤,性能好但贵,需要专用的 FC 交换机和 HBA 卡
- • FCoE:把 FC 协议跑在以太网上,算是个折中方案
- • NVMe-oF:这几年比较火,基于 NVMe 协议通过网络访问远程存储,延迟极低
选哪个看你预算和性能需求。预算充足直接上 FC,想省钱就用 iSCSI,追求极致性能就上 NVMe-oF。
文件存储:大家都认识的老朋友
你天天在用它
文件存储可能是三种存储里大家最熟悉的了。你打开电脑,进 D 盘,打开"工作资料"文件夹,找到"季度报告.docx"——这个过程就是在用文件存储[1]。
文件存储用一种层级结构来组织数据:磁盘→目录→子目录→文件。你要访问一个文件,得知道它的路径,比如 /home/user/documents/report.pdf。这个路径就是文件系统帮你维护的"导航地图"[2]。
常见的文件系统协议有 NFS(Linux 下用得多)、SMB/CIFS(Windows 下用得多)。NAS 设备就是典型的文件存储,它自带文件系统,你通过网络挂载就能用,不需要自己格式化[4]。
文件存储的优缺点
好处显而易见——好用啊!人人都会用文件夹,不需要学习成本。而且它支持文件级别的权限控制,可以设置谁能读、谁能写、谁能执行。多人协作的时候,文件共享很方便[4]。
但问题也很明显。当文件数量大到一定程度,这个层级结构就开始扛不住了。你想想,一个目录下放几百万个文件,光列个目录都要等半天。而且文件系统的扩展性有限,它本质上是纵向扩展的——容量不够了加硬盘,但单台 NAS 的处理能力是有上限的[3]。
还有个问题是锁机制。NFS v3 的锁就是个老大难问题,经常出现文件锁死、进程挂住的情况。NFS v4 好了一些,但也不是完全没毛病。SMB 协议在 Windows 环境下还好,跨平台的时候偶尔也会抽风。
实际用在哪
场景一:NAS 文件共享。 这是最常见的。公司里搞个 NAS 服务器,大家把公共资料放上面,各部门有自己的目录,设置好权限。小公司一台群晖就搞定了,大公司可能用 NetApp 或者 Isilon 这种企业级 NAS。
场景二:应用日志集中存储。 有些业务系统产生的日志需要集中收集和共享,运维和开发都要看。这时候用 NFS 挂一个共享目录,大家都能访问,比每台机器上单独看方便多了。
场景三:HPC 高性能计算。 科研机构跑大规模计算任务的时候,经常用到并行文件系统,比如 Lustre、GPFS。这些其实也是文件存储的一种,只不过做了并行优化,能支持多节点并发读写,IOPS 和吞吐量都很高。之前我在一个气象局项目里用过 GPFS,几十个计算节点同时读写,性能还不错。
场景四:容器共享存储。 K8s 里有些场景需要多个 Pod 同时读写同一个卷,比如配置文件共享、静态资源共享。这时候用 NFS 挂载就比块存储合适,因为块存储的 RWO(ReadWriteOnce)模式只允许一个节点挂载。
对象存储:互联网时代的新宠
它跟前两位有啥不一样
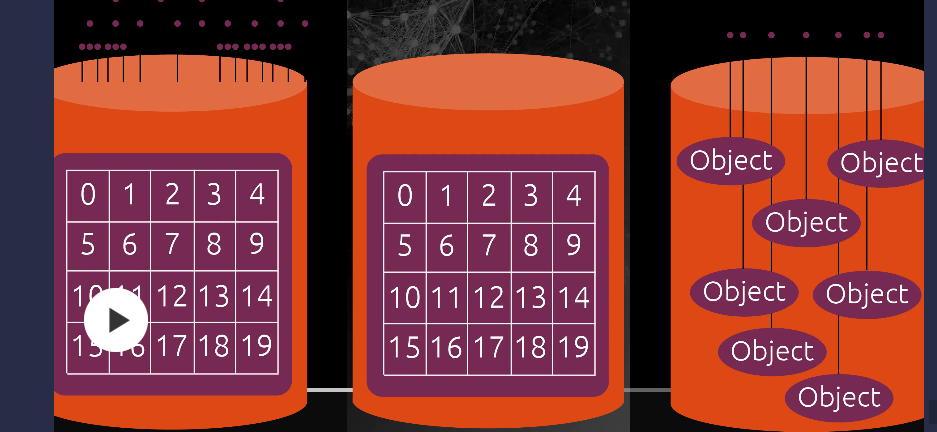
对象存储跟前两个最大的区别在于:它是扁平结构的,没有目录层级[2]。
在对象存储里,所有数据都被封装成一个个"对象"。每个对象包含三部分:数据本身、元数据、唯一标识符(Object ID)[1]。你不需要记住什么路径,只要知道对象的 ID 或者 key,就能把它取出来。
这就像你存东西到快递柜——你不需要知道快递柜内部怎么排列的,你只需要一个取件码。对象存储的 API 就相当于那个取件码的接口,你通过 HTTP 请求(一般是 RESTful API)来存取数据[4]。
Amazon S3 是对象存储的标杆,它定义了一套事实标准。现在你去看市面上大部分对象存储——阿里云 OSS、腾讯云 COS、MinIO、Ceph RGW——基本都兼容 S3 协议[4]。
对象存储凭什么火起来
互联网时代数据量爆炸式增长,动不动就是 PB 级别的数据。文件存储扛不住这个量,块存储又太贵。对象存储正好填了这个空[4]。
它的扩展性几乎是无限制的。你往里面扔十亿个对象都没问题,系统会自动把数据分散到多个节点上。而且它的成本很低,因为用的是普通 x86 服务器加普通硬盘,不需要专用硬件[4]。
元数据是对象存储的另一个亮点。每个对象可以带非常丰富的自定义元数据,你可以给一个图片对象加上"拍摄地点=北京""拍摄时间=2024-01-01""摄影师=张三"这些标签,然后通过这些标签来检索数据。这在文件存储里是很难做到的[3]。
但对象存储也有硬伤。它不支持文件的随机修改——你要改一个对象,只能整个重新上传。这就像你不能只修改一个 Word 文档的某一页,你只能把整个文档重新保存一遍[1]。所以对象存储不适合跑数据库,也不适合需要频繁随机读写的场景。
对象存储的延迟也比块存储高。因为它是通过 HTTP API 访问的,中间有网络开销和协议解析开销。你做一次 PUT 或 GET 请求,延迟可能在几十毫秒到几百毫秒,跟块存储的亚毫秒级延迟比差了不少[3]。
对象存储实际怎么用
场景一:图片和视频存储。 这是最经典的场景。用户上传的头像、短视频、直播录像,全部丢到对象存储里。前端通过 CDN 回源到对象存储,用户访问的时候 CDN 缓存一层,既快又省钱。我之前经手的一个短视频项目,每天产生几个 TB 的视频数据,全丢 OSS,按量付费,成本比买存储阵列低太多了。
场景二:备份和归档。 数据库备份、日志归档这些不需要频繁访问的数据,放对象存储里再合适不过了。很多云厂商还提供低频访问和归档存储类型,价格更便宜。我们公司的数据库备份策略就是:本地保留 7 天,7 天以上的自动传到 S3 标准存储,30 天以上的转到 S3 Glacier 归档存储,成本直接降了一个数量级。
场景三:静态网站托管。 把前端静态资源(HTML、CSS、JS、图片)放到对象存储里,开启静态网站托管功能,直接就能对外提供服务。配合 CDN 一起用,效果不比传统 Web 服务器差,还省去了运维 Web 服务器的麻烦。
场景四:大数据分析的数据湖。 这几年特别火。企业把各种结构化、非结构化数据全部灌到对象存储里,形成"数据湖",然后用 Spark、Presto 这些计算引擎来分析。对象存储成本低、容量大,作为数据湖的底座非常合适[4]。
场景五:AI 训练数据集。 搞机器学习的同学应该深有体会,训练数据集动辄几十 GB 到几个 TB。放本地磁盘不够用,放块存储太贵,对象存储正好。训练的时候批量拉取到本地,训练完了再删掉[4]。
三者对比:一张表不够,得掰开了说
网上很多文章就放一张对比表就完事了,但我觉得光看表不够直观。我把几个关键维度掰开来讲讲。
性能
块存储 > 文件存储 > 对象存储,这个排序基本没什么争议。
块存储的延迟可以做到 0.1ms 级别,IOPS 可以做到几十万。文件存储次之,延迟一般在几毫秒级别。对象存储最慢,延迟几十毫秒到几百毫秒都有可能[3]。
但要注意,这是"一般情况"。你拿一个低端 SAN 跟一个高性能并行文件系统比,那文件存储可能更快。性能这东西得看具体产品和配置,不能一概而论。
扩展性
对象存储 > 块存储 > 文件存储。
对象存储天生就是分布式的,加节点就行,容量和性能都能线性扩展,PB 级别轻松搞定。块存储扩展靠加磁盘或者加存储节点,但管理复杂度上来了。文件存储扩展性最差,单文件系统容量有上限,跨节点扩展需要做分布式文件系统,复杂度很高[3]。
成本
对象存储 < 文件存储 < 块存储(单位成本)。
对象存储用普通服务器和普通硬盘,成本最低,而且云上按量付费,不用的不花钱。文件存储中等,NAS 设备不算太贵但也不便宜。块存储最贵,企业级 SAN 动辄几十万,云上的块存储按月收费也不便宜[4]。
数据访问方式
这个很多人搞不清楚,我单独说一下。
- • 块存储:通过块设备协议(iSCSI、FC 等)访问,操作系统看到的是一块裸磁盘
- • 文件存储:通过文件系统协议(NFS、SMB 等)访问,用户看到的是文件和目录
- • 对象存储:通过 HTTP RESTful API 访问,用户看到的是一个个对象[4]
访问方式不同意味着你的应用代码也不同。块存储和文件存储对应用是透明的,你用普通的文件 I/O 就能读写。但对象存储需要你调 API,或者用 SDK,代码得改。
一致性模型
块存储和文件存储都是强一致性的——你写进去的数据,立刻就能读到最新的值。对象存储在很多实现中是最终一致性的——你刚写进去的对象,可能过一会儿才能被读到[2]。
不过现在很多云厂商的对象存储已经支持强一致性了,比如 AWS S3 在 2020 年之后默认就是强一致性。但如果你用的是自建的对象存储,还是得注意这个问题。
实际选型:别纠结,看场景
讲了这么多理论,落到实际怎么选?我给几个原则。
跑数据库?选块存储。 这个没什么好商量的,数据库对延迟和 IOPS 的要求很高,块存储是唯一靠谱的选择。不管是 MySQL、PostgreSQL 还是 MongoDB,底层都应该是块存储。
文件共享和协作?选文件存储。 多人需要同时访问同一批文件,需要目录结构和权限控制,文件存储最合适。比如设计团队的素材库、开发团队的代码仓库(Git 也可以用,但大文件还是 NAS 靠谱)。
海量非结构化数据?选对象存储。 图片、视频、日志、备份数据,量大但访问频率不高,对象存储性价比最高。
虚拟机磁盘?选块存储。 不管是 VMware 还是 OpenStack,虚拟机的磁盘镜像都放在块存储上。
容器持久化?看需求。 需要高性能独占的用块存储,需要多 Pod 共享的用文件存储,存配置文件或静态资源的用对象存储。
大数据和 AI?选对象存储。 数据湖的标配,成本低容量大,计算引擎都支持 S3 协议。
实际生产中,大部分企业是三种混用的。比如我们公司现在的架构:数据库跑在云盘(块存储)上,应用日志和共享配置放 NFS(文件存储),用户上传的图片视频全丢 OSS(对象存储)。各司其职,谁也不抢谁的活。
几个容易踩的坑
最后说几个我踩过的坑,希望你们能绕过去。
坑一:拿对象存储当文件系统用。 有些人觉得对象存储便宜,就把所有东西都往里扔,还想像用文件夹一样去管理。结果发现不能随机修改、不能直接 mount、延迟还高。对象存储就是对象存储,别硬把它当文件系统用,该用文件存储的场景就老老实实用文件存储。
坑二:块存储不备份。 觉得块存储有 RAID 保护就万事大吉了。RAID 只防磁盘故障,防不了误删数据和逻辑错误。该做的快照备份、异地容灾一个都不能少。我见过最惨的一次,有人误操作把生产数据库的 LUN 给删了,没有快照没有备份,直接从删库到跑路。
坑三:文件存储跨网段挂载不设超时。 NFS 挂载的时候如果不设 soft 模式和 timeo 参数,一旦 NFS 服务端出问题,客户端进程就会卡死,而且卡得死死的,kill -9 都杀不掉。这个坑我踩过好几次,后来学乖了,挂载参数一定写全。
坑四:对象存储不设生命周期策略。 数据往里一扔就不管了,几个月后发现账单越来越贵。对象存储一定要设生命周期策略,热数据放标准存储,冷数据自动转到低频存储,归档数据转到归档存储。这样能省不少钱。
坑五:忽略对象存储的元数据。 很多人用对象存储就是存取文件,完全忽略了元数据这个强大的功能。其实你可以通过自定义元数据来实现很多有意思的东西,比如给图片打标签、给日志加索引,后面检索起来会方便很多。
写在最后
存储这个话题其实挺大的,一篇四千字的文章也只能讲个大概。但核心的东西我都尽量讲到了——三种存储的本质区别、各自的优缺点、适用场景、选型原则、还有实际踩过的坑。
说到底,没有最好的存储,只有最合适的存储。你在选型的时候,先想清楚三个问题:你的数据是什么类型的?你的访问模式是什么样的?你的预算是多少?想清楚这三个问题,答案基本就出来了。
技术选型这事儿,别追求"一步到位",也别想着"一招鲜吃遍天"。业务在发展,数据在增长,存储架构也得跟着演进。今天用块存储够用,明天数据量上来了可能就得加对象存储。保持灵活性,留好扩展空间,这才是正确的姿势。
如果这篇文章对你有帮助,欢迎转发给身边搞运维、搞架构的兄弟们。有什么问题或者不同意见,评论区聊。
公众号:耕云躬行录
个人博客:躬行笔记
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号