IM分布式架构系列(18)直面消息扇出风暴 | 10000人群优化设计
原创
IM分布式架构系列(18)直面消息扇出风暴 | 10000人群优化设计
原创
拉丁解牛说技术
发布于 2026-07-02 01:10:58
发布于 2026-07-02 01:10:58
最近世界杯太火了,大半夜经常听到周边小伙们胜利的欢呼声、还有拍大腿的惋惜。
有多少人和我一样,内心藏着一个很深的想法:希望有生之年,可以看一次有国足参加的世界杯!
一、扇出风暴是什么
二、批量、合并与削峰的设计
三、某钉如何设计
四、挑战与优化
一、扇出风暴是什么
一个 1 万人的全员群,群主发了一条「明天全公司放假,庆祝xx挺近世界杯64强」。
对群主来说这是一次点击。但在写扩散模型下,服务端要在这一瞬间做 9999 次投递判断:查 9999 次在线状态、给在线的几千人各推一帧、给离线的几千人各写离线盒子并各触发一次三方推送、各更新一次未读数。一条消息在一秒内放大成上万次后端操作——这就是扇出风暴。
之前《写扩散账单》算过这笔账:千人群一条消息要扇出 999 次,写扩散贵但绕不开,既然要扇出,这上万次操作挤在同一秒涌向推送链路,怎么扛住?
风暴的可怕之处不在总量,在瞬时性。一万次操作摊到一天毫无压力,但若几个万人群在同一分钟集体活跃——开早会、抢红包、发通知——洪峰同时打在接入层、推送、MQ broker 和客户端上,任何一段扛不住,整条链路就一起延迟、堆积、雪崩。
1.1 扇出风暴在 IM 链路中的位置
扇出风暴发生在"1 条原消息"变成"N 份投递"的那一跳——群服务展开成员、把副本交给下游推送的环节。它横跨几个组件,没有单一归属:

扇出风暴贯穿群服务
1.2 让推送链路被打爆的三个瞬间
瞬间一:接入网关单机被打满。 接入层按机器分片,极端情况下一台接入机恰好持有上千个该群成员的长连接,一条群消息扇出后要同时 writeAndFlush 上千帧——不做批量与限速,单机出口带宽和 CPU 瞬时打满,连带拖慢它上面其他会话。
瞬间二:MQ broker 被扇出副本灌爆。 扇出走逐条 MQ,一条万人群消息就是近万条写入;十个这样的群同时活跃,broker 每秒要吞十万条。单 partition 串行处理,瞬时洪峰会让队列堆积、消费延迟、ACK 超时连环触发重投,形成正反馈雪崩。
瞬间三:客户端被刷屏刷死。 万人群活跃时一秒可能有几十条消息,服务端逐条下推、客户端逐条渲染,低端机会因 UI 主线程被刷新占满而卡顿。
三个瞬间对应削峰的三类问题:降低单次扇出操作次数(批量)、削平瞬时洪峰(合并 + 缓冲限速)、保护链路末端(降级 + 客户端聚合)。
二、批量、合并与削峰的设计
2.1 批量推送:按接入机聚合的扇出
风暴的第一个放大器是"逐个目标各做一次操作"——一条万人群消息若对每个成员各查一次在线状态、各发一次 RPC、各推一帧,操作次数就是成员数。
降低操作次数的关键洞察是:很多目标其实落在同一台机器上。在线状态和路由缓存按用户哈希分布在若干台缓存机,长连接也按用户分布在若干台接入机。既然如此就不该逐个查推,而该按目标所在机器把操作聚合成批。
瓜子某车分享的大群推送优化把它拆成两层批处理:按成员算出路由分布后,一次从某台缓存机检索出落在它上面的所有成员状态,把上千次点查压成几十次;推送同理,按接入机把这台机器要收的所有副本打成一个批量包投过去本地展开下推。微某信做法可能也是同一思路——把每步的 RPC 按目标机器聚合成批量操作并行执行。
on_group_message(msg):
members = filter_sender(group.members, msg.from) # 9999 人
// 1) 按缓存机分组,批量查在线状态/路由
by_cache_node = group_by(members, m -> hash_node(m.uid))
routes = {}
for node, uids in by_cache_node:
routes.merge(batch_query_route(node, uids)) // 一次查一批
// 2) 按接入机分组,批量下推
by_gw = group_by(online(members, routes), r -> r.gateway)
for gw, batch in by_gw:
send_batch_to_gateway(gw, msg, batch) // 一次一个批量包维度 | 详情 |
|---|---|
优势 | 操作次数从 O(成员数) 降到 O(机器数),万人群查询/RPC 压缩一两个数量级; 接入机单批一次系统调用,出口效率高 |
代价 | 群服务要懂路由分布、做两次分组; 批内部分失败的处理比逐条复杂;批太大单包延迟上升 |
2.3 合并窗口:把多条消息攒成一次下发
批量推送解决"一条消息内"的放大,合并窗口解决"多条消息之间"的洪峰。万人群活跃时一秒可能涌入几十条消息,每条都立刻独立扇出,接入层和客户端就要承受每秒几十轮下推。合并的思路是开一个很短的时间窗口(如 200ms~1s),把窗口内同一群的多条消息攒在一起一次性下发。
对纯聊天消息合并要克制——延迟一秒下发,活跃群用户能感知到"对话变迟钝",所以聊天窗口通常很短或不开。但有一类数据非常适合合并:已读回执、未读数、群状态这类"只关心最终值"的更新。万人群几千人同时读消息,已读事件每秒上千;可发送方只需要知道"现在有多少人读了",不需要逐条收到上千个事件。窗口内累积、到点取最新值一次下发即可。
// 适合合并的是"最终值"类更新,不是聊天消息本身
on_read_event(group_id, reader):
pending[group_id].add(reader) // 累积进窗口,不立即下发
every 1s for group_id in pending: // 定时触发批处理
snapshot = pending[group_id].drain()
push_merged_read_count(group_id, snapshot) // 一次下发合并后的已读数合并处理按类型分档:聊天走低延迟通道,已读/状态/未读走合并窗口——某钉就是这么落地的。
2.4 削峰:队列缓冲、限速与优先级
批量和合并降低了操作总量,但瞬时洪峰仍可能超过下游处理能力。这时需要"削峰填谷"——把超出的洪峰用队列缓冲存起来匀速放给下游。三件事配套:
队列缓冲。 MQ 天然是削峰缓冲池:洪峰来时副本堆在 broker 里,消费端按自己的节奏拉。关键是别让扇出走同步 RPC——同步链路没缓冲,一段慢则全链路慢。
消费限速。 缓冲只是把洪峰存下来,还得控速,避免消费端为追堆积把自己和下游打满。订阅侧限速是反复出现的保护手段,副作用是堆积期间延迟上升。
优先级隔离。 削峰最忌讳"高时效消息排在刷屏消息后面"。红包、@我、系统通知必须走独立高优通道,不和普通群消息挤一个队列。代价是资源翻倍,但这是体验刚需,尤其ToB场景。
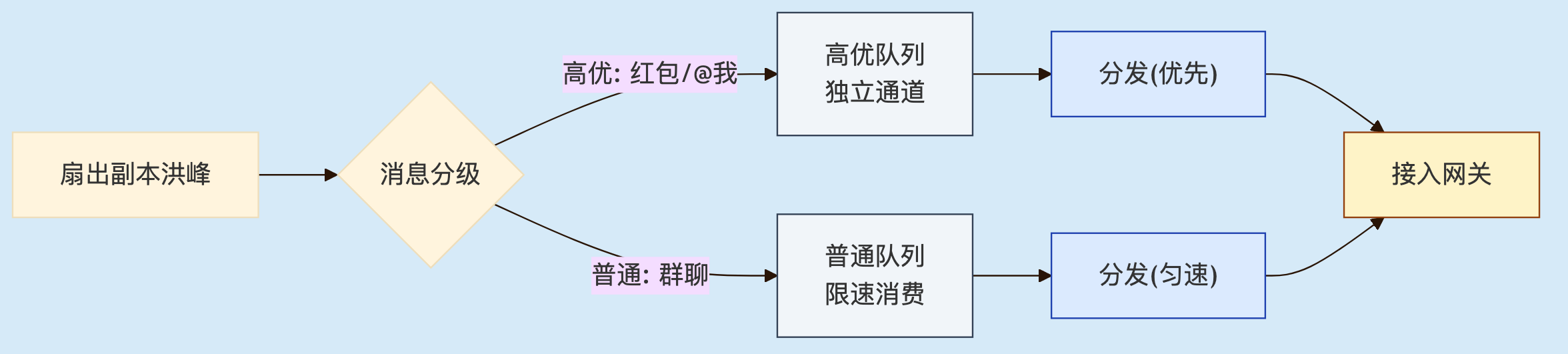
2.5 降级:活跃优先与推拉分流
前面三招都还在"把所有人都推到"的框架里。这里有个非常实用的小技巧,也是一个事实值得注意:不是所有成员都需要同等实时性——万人群里真正盯着窗口的只有一小部分。由此引出降级,按活跃度分级把推送资源留给真正在看的人:
- 活跃成员(在线且近期看过该群):实时推送
- 在线但不活跃成员:降级为只推一个"有新消息"的轻量信号,切回该群再拉完整内容
- 离线成员:异步写离线盒子 + 延迟触发三方推送,完全脱离实时洪峰
活跃度信号通常是最近一次切到该群会话窗口的时间戳,存 Redis 按 TTL 自动失效,避免维护成本过高。
这本质是把一部分成员从"推"切到"拉":服务端不再为不活跃成员承担实时扇出,改由客户端按需主动拉。推测万人群里不活跃成员往往占大多数,这一刀能显著压低瞬时推送量,代价是这部分成员消息有轻微延迟。
2.6 读扩散兜底:超大群只写一份
群规模继续往上走——几万、十万人——写扩散在物理上就走不通了:一条消息扇出十万次,无论怎么批量、合并、削峰,总操作量摆在那里。唯一的出路是换模型:超大群不再写扩散,群消息只存一份,成员读群时按需拉。代价是已读、未读这些原本依赖每成员投递记录的功能要在读路径上重新设计,客户端也更重。
以下是不同规模群,设计策略:
群规模 | 主导策略 |
|---|---|
< 500 | 朴素写扩散,逐条扇出 |
500 ~ 2000 | 批量化写扩散 |
2000 ~ 万人 | 批量 + 活跃优先 + 合并 + 重度削峰,逼近上限 |
万人 | 切读扩散,只写一份 + 按需拉 |
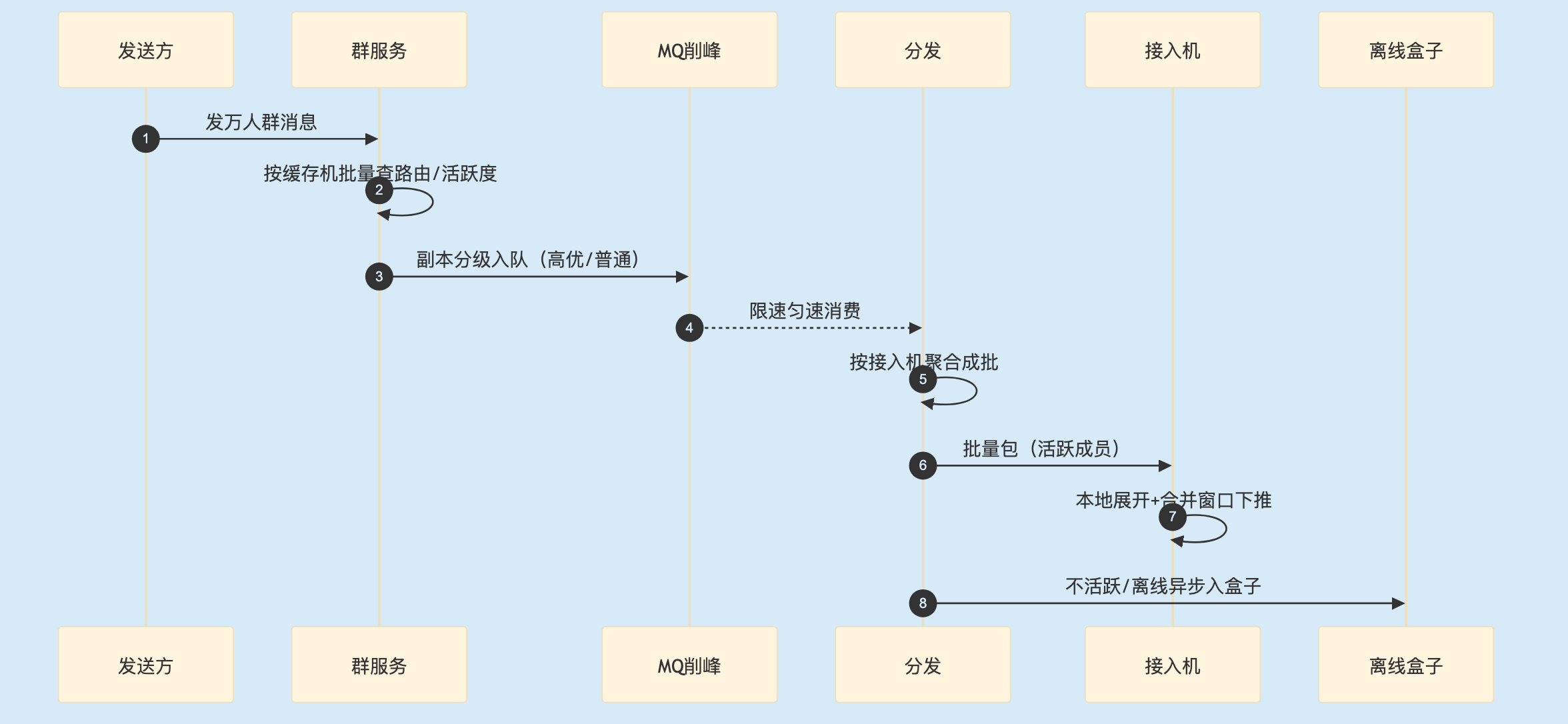
2.7 削峰链路全貌
万人群消息的削峰链路大致如下:
三、某钉如何设计
3.1 为什么选某钉
万人群削峰这件事,国内公开资料最扎实的是某钉——DAU 过亿里少有的 toB 产品,公开提到已能支持十万人级别的群,且专门分享过用 RocketMQ 做削峰填谷、限速以及"分布式定时任务"合并万人群更新的实践,正好覆盖我们说的的削峰、合并两条主线。
3.2 RocketMQ 做削峰填谷与限速
某钉 IM 把发消息和已读链路都建在消息队列上,核心动机之一就是削峰填谷。发消息时入口应用只做"能否发送"的校验,通过就投进队列即返回用户,入库、推送交给下游订阅,入口不被下游洪峰拖累。它在两个地方做了削峰相关的关键设计:
- 订阅侧限速:对消费限速,避免突发峰值给系统带来灾难性后果——也就是"缓冲之后还要控速"。
- 异常流量隔离:处理失败的消息不在原队列原地重试,而是重投到独立的异常 topic,用定时消息退避、对其限速消费,与正常流量隔离、优先处理正常消息。某钉也直言,持续异常又不限速,回旋重试的流量叠加容易雪崩。
3.3 用定时消息把万人群更新合并成批
某钉分享里有一个直接命中"合并"主线的例子:几千人的群发一条消息,假设四分之一成员开着窗口,不对已读更新做合并,更新 QPS 会高达 1000/s;而它能支持十几万人的超大群,但用户实际只需要秒级更新。
他们的做法是用 RocketMQ 的定时消息实现"分布式定时任务":用户请求先放进集中式请求队列,再用定时消息生成一个比如 5 秒后触发的任务;到点把累积的所有请求一次性批量处理。某钉把它抽象成通用组件,万人群的群状态更新、消息扩展更新都接了进来——效果是大群活跃时段流量显著压低并保持平稳。
维度 | 详情 |
|---|---|
优势 | 已读/状态类更新从每秒上千次压成每几秒一批; 削峰填谷 + 限速 + 异常隔离让突发洪峰可控; 支撑到十万人级群 |
代价 | 合并引入秒级延迟; 强依赖 MQ 的定时消息与堆积能力; |
四、挑战与优化
4.1 写放大、实时性与成本的三角矛盾
万人群扇出的本质矛盾,是写放大、实时性、成本三者不可同时拉满。写扩散给你最简单的读路径和最好的实时性,代价是写放大 N 倍、成本随群规模线性涨;读扩散把写放大压到 1,代价是读路径复杂、客户端变重。批量、合并、削峰本质都是在三角内部腾挪——批量降成本但加复杂度,合并和削峰降成本保稳定但牺牲实时性。
4.2 合并窗口的取舍
合并是性价比最高的削峰手段,但窗口大小是个真正难调的参数:太短合不掉几条,太长用户感知延迟、活跃群"变迟钝"。
应对的关键是别用一个全局窗口:聊天消息窗口极短或不开保实时;已读、未读、群状态这类"最终值"更新窗口可开到秒级——某钉的 5 秒批处理就是这一档。一个反共识点是:合并收益和群活跃度强相关,冷群开窗口纯属白增延迟,更工程化的做法是让窗口随活跃度自适应——活跃群才开合并、冷群直接透传。
4.3 热点大群的隔离
第二个绕不开的坑是热点群。几个万人群、全员群同时活跃,足以把公共的接入机、broker partition、分发线程池占满,连累成千上万个无关的小群和单聊一起延迟——少数热点拖垮大盘。
业界成熟的应对是隔离:某钉把异常流量重投到独立 topic 隔离,瓜子把红包消息单独部署 Deliver 节点走独立通道。同一思路可推广到热点群——给识别出的超大活跃群分配独立扇出资源(独立队列、独立分发实例),让它的洪峰关在隔离舱里打不到普通会话。识别通常靠近实时滑动窗口统计扇出次数,超阈值自动打热点标签,下次扇出走隔离通道。代价是要有热点识别和可隔离的资源调度,但对"一个大群拖慢全系统"这种 P0是值得提前部署。
4.4 客户端聚合渲染
洪峰的最后一棒砸在手机上,这段最容易被后端忽略:即使服务端削峰再好,万人群一秒几十条消息逐条刷 UI,低端机照样卡死。
应对要从服务端延伸到客户端:服务端批量下发让客户端一次收到一批;客户端则做聚合渲染——把短时间内到达的多条消息攒一帧统一刷新;刷屏严重的超大群甚至可以"抽帧",速率过高时主动降频只保证最新消息可见:削峰是端到端的,服务端扛住了,但不等于用户体验扛住。
削峰不是消灭风暴,是把它摊平到链路扛得住的节奏里——代价永远是某个维度的让步,区别只在让哪一个。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号