用WorkBuddy打通投放+CRM+客服三系统,搜索词全链路归因实操
原创
用WorkBuddy打通投放+CRM+客服三系统,搜索词全链路归因实操
原创
用户12594727
发布于 2026-07-01 09:16:12
发布于 2026-07-01 09:16:12
用 WorkBuddy 打通投放后台+CRM+客服对话三套系统,做搜索词到到诊的全链路归因实操
代码
报告漏斗图
前言
做搜索广告投放的人基本都遇到过同一个老大难问题:前端投放数据和后端转化数据对不上。
广告后台只能看到消费、展现、点击、一句话咨询、留线索,看不到用户最后有没有真成交;客服对话系统知道聊了什么,但不知道这人是哪个搜索词来的;转化数据在业务系统的CRM里,记录了搜索词但经常跨月甚至跨季度才转化。三套系统各管一段,数据全是孤岛。
以前想搞清楚"哪个搜索词最后真的带来转化"这种问题,得手动导三份表对,对一次少说半天,还经常对不上。后来用 WorkBuddy 搭了一套数据全链路分析的工作流,几个小时就能跑完一轮深度归因,这里把整套实操过程写出来,给同样被数据孤岛折磨的同行一个参考。
一、先理清楚:三套系统各有什么数据
这是我踩坑踩出来的认知,写在这里省得你重走一遍。
系统 | 有什么 | 没什么 |
|---|---|---|
广告投放后台 | 消费、展现、点击量、一句话咨询、留线索量、计划/单元/关键词 | 是否转化 |
客服对话系统 | 对话内容、承接质量、转线索情况 | 搜索词来源、是否转化 |
业务系统CRM | 姓名、录入日期、转化日期、来源、搜索词、是否转化 | 前端消费、对话内容 |
关键矛盾:广告后台前端留线索900多条,但CRM里同月转化只有30多条,中间差了一大截,没法一对一追溯。如果只看广告后台数据做否词决策,一定会误杀真正能转化的词。
二、用 WorkBuddy 干了什么
整个工作流拆成三步,每一步都让 WorkBuddy 用 Craft 模式直接处理文件:
第一步:统一三套系统的数据格式
三套系统导出来的格式完全不一样——广告后台搜索词报表是 GBK 编码的 CSV,CRM 是 XML 格式的 XLS,渠道库是普通 XLSX。直接读会乱码或报错。
让 WorkBuddy 写一个共享的数据加载模块 data_loader.py,把三套数据统一成一份标准结构。关键点:
- 广告后台CSV要指定
encoding='gbk',否则中文乱码 - CRM的XLS是XML格式,要按列位读(比如 Col 0=姓名, Col 4=录入日期, Col 6=转化日期, Col 10=来源, Col 18=搜索词),不能按表头名读,表头经常变
- 渠道库是来源→归属的映射表,用来把CRM里五花八门的来源归一到投放渠道
踩坑提醒:千万别让AI"补充"数据。我一开始让模型对着残缺数据"推测一下",结果它编了一堆不存在的数字进去,后面全错了。铁律:所有数字必须从原始数据来,缺就是缺,不做任何填充。
第二步:词级转化漏斗分析
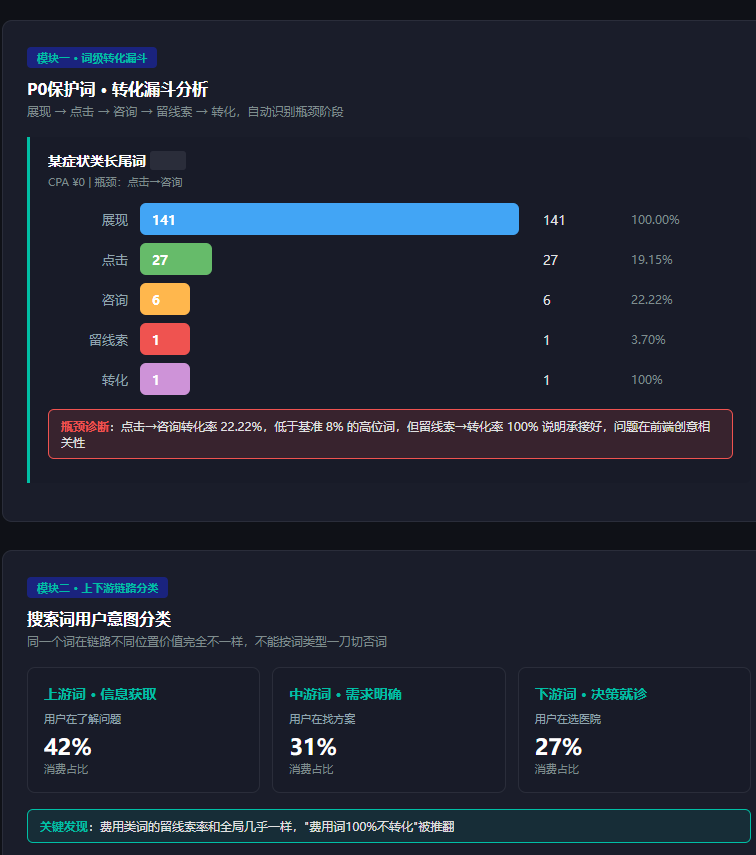
三套数据合并后,对每一个重点保护词构建完整漏斗:
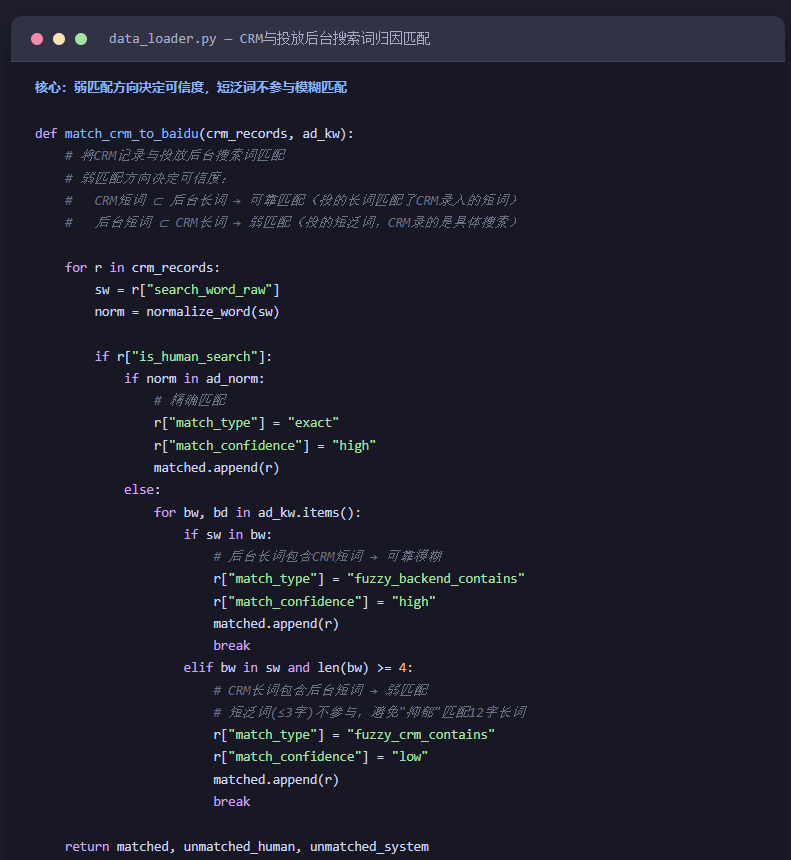
展现 → 点击 → 咨询 → 留线索 → 转化前四步广告后台有,最后一步要到CRM里匹配。这里有个最关键的归因规则,按这套规则匹配,而不是简单的字符串相等:
弱匹配方向决定可信度:
- CRM短词 ⊂ 广告后台长词 → 可靠匹配(投的长词匹配了CRM录入的短词)
- 广告后台短词 ⊂ CRM长词 → 弱匹配(投的是短泛词,CRM录的是具体搜索)
短泛词(≤3字)不参与模糊匹配:比如"抑郁"这种2字词,不能去匹配"某地抑郁症医院哪家最好"这种12字长词,只能归因到病种维度,不能归因到具体词。
这套规则是对照真实数据一条条核出来的,WorkBuddy 帮它落成了代码(funnel_analysis.py),以后每月新数据来了直接跑,不用再人工核。
第三步:搜索词上下游链路分类
这是最有价值的一步。把所有搜索词按用户意图分三类:
- 上游词(信息获取阶段):用户在了解问题
- 中游词(需求明确阶段):用户在找解决方案
- 下游词(决策阶段):用户在选服务商
分类规则写在 pipeline_classify.py 里。分类之后能看出一个很重要的问题:同一个词在链路不同位置价值完全不一样。如果一刀切按"费用类词不转化"否掉,会把真正能转化的词一起否了。
实际跑下来发现:费用类词的留线索率和全局几乎一样,"费用词100%不转化"是个被推翻的错误假设。还有6个词前端0留线索,但CRM里实际有转化——这种词按当月数据否就废了,因为转化可能滞后数月。
三、踩过的坑(避免你重走)
- 当月数据不足以判断否词。转化经常跨月甚至跨年,CRM里有5个2022-2025年录入的客户,2026年才转化。否词必须看历史3个月以上的CRM数据。
- 不要按词类型一刀切否词。费用词、症状词、品牌词,每一类里都有能转化的和不能转化的,得看后端转化,不能只看前端留线索。
- 数据严禁补充。AI特别爱"帮忙补全",一定要盯死,缺数据就标缺,不能编。
- 追踪码是第四块拼图。搜索词告诉你用户想什么,追踪码(搜索词→关键词→单元→计划)告诉你投放策略哪里出问题。一开始忽略了追踪码,分析总是差点意思。
- 多账户/多地区数据要分开看。不同账户、不同地区的转化特征差很多,混在一起分析会把差异抹平。
四、效果和省时估算
以前手动做一轮全链路归因:3-5天,还容易出错。 现在用 WorkBuddy 跑:2-3小时出一份HTML深度分析报告,包含词级漏斗、链路分类、异常词个案深挖三个模块。
输出是一份可以直接给老板看的 HTML 报告,不用再手动排版。每个月新数据来了,换一下输入文件路径,跑一遍就行。
五、一点心得
WorkBuddy 在这种"多系统数据打通 + 规则化分析"的场景下特别好用,因为它能直接读文件、写代码、跑脚本、出报告,一条龙。不像纯对话型AI,得把数据复制粘贴进去,还限制长度。
几个使用建议:
- 先理清规则再让它干活。归因规则、分类规则这种业务逻辑,得自己先想清楚,再让WorkBuddy落成代码,不能指望它自己猜业务规则。
- 数据输入规范要写死。哪个字段在第几列、什么编码、什么格式,写成文档固定下来,否则每次数据格式一变就崩。
- 简单查询用Ask模式,深度分析用Craft模式。Ask不碰文件省积分,Craft能读写文件适合干活,按需切换能省不少额度。
如果你也在做投放数据分析,被多系统数据孤岛困扰,可以参考这套思路搭一个自己的工作流。有问题欢迎评论区交流。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号