Kubernetes 升级实录:一次 1.34 → 1.36 集群升级过程中踩过的几个坑

Kubernetes 升级实录:一次 1.34 → 1.36 集群升级过程中踩过的几个坑

一根头发丝的宽度
发布于 2026-06-29 13:07:46
发布于 2026-06-29 13:07:46
你以为升级就是几条命令?太天真了。
最近我把自己的 Kubernetes 集群从 1.34 升级到了 1.36。
跨两个小版本,官方建议逐级升级:
v1.34 → v1.35 → v1.36
我心里想的是:不就是几条命令的事?
kubeadm upgrade apply
apt upgrade kubelet
systemctl restart kubelet
结果呢?
一连踩了好几个坑。
kubeadm 版本不匹配、kubelet 启动失败、etcd 升级超时、drain 卡住不动……每一步都让人头大。
由于篇幅原因本篇文章仅记录部分升级步骤,完整的内容请参考末尾的“阅读原文”。
我的集群长这样
先交代一下背景:
- 3 台 Master+ 3 台 Worker
- Kubernetes v1.34→ 目标 v1.36
- 容器运行时:containerd 1.7
- CNI:Calico
- 操作系统:Debian 13
目标路径:
v1.34 → v1.35 → v1.36
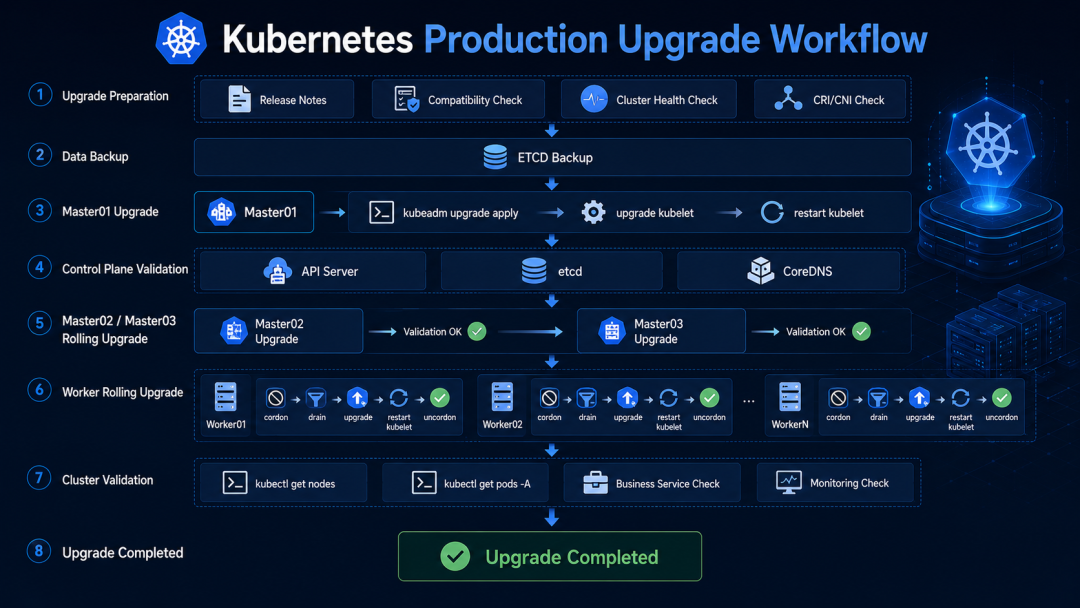
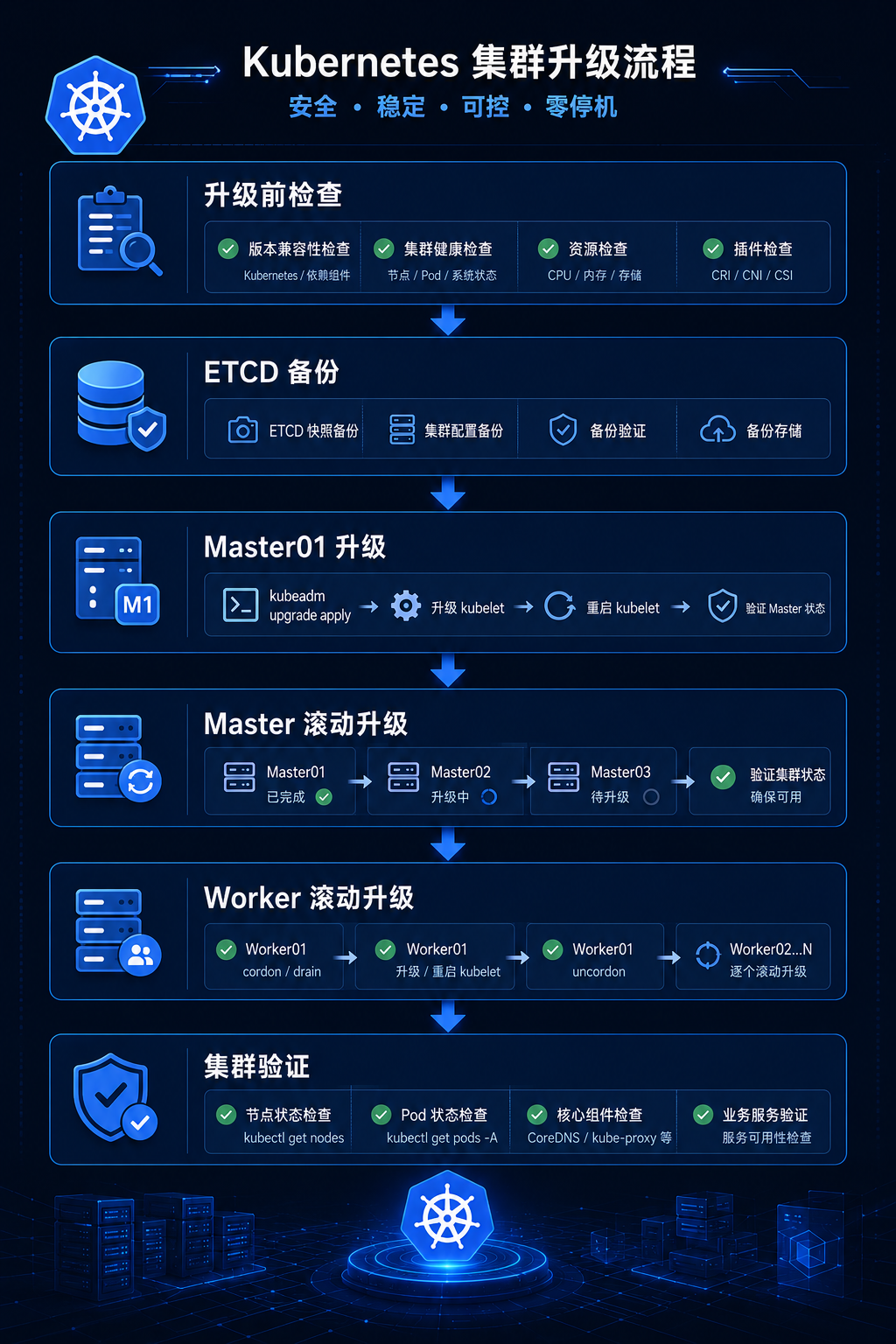
升级流程
整个升级流程如下图所示:
升级前,这两件事必须做
1️⃣ 确认集群健康
kubectl get nodes
kubectl get pods -A
确保:
- 所有节点
Ready - 没有异常 Pod
- etcd 正常工作
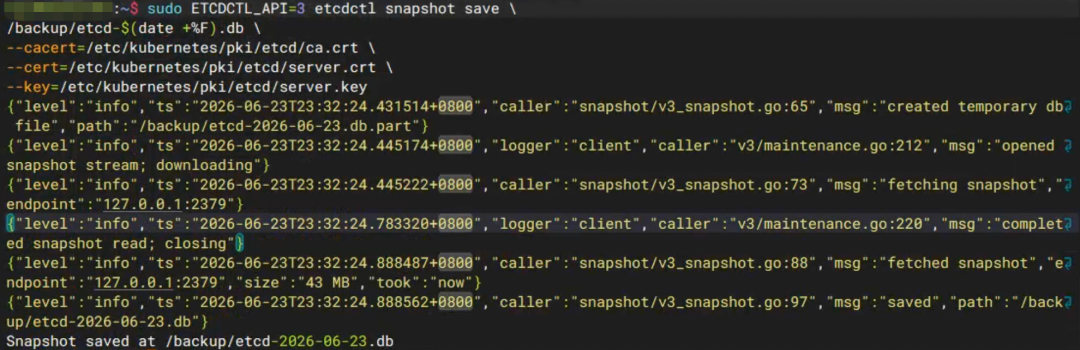
2️⃣ 备份 etcd(这条救命)
ETCDCTL_API=3 etcdctl snapshot save snapshot.db
一旦控制平面升级失败,这就是你最后的退路。
坑 ①:kubeadm 版本太低,不让升级
我上来就执行:
kubeadm upgrade apply v1.35.6
结果直接报错:
Specified version to upgrade to "v1.35.6"
is higher than the kubeadm version "v1.35.0"
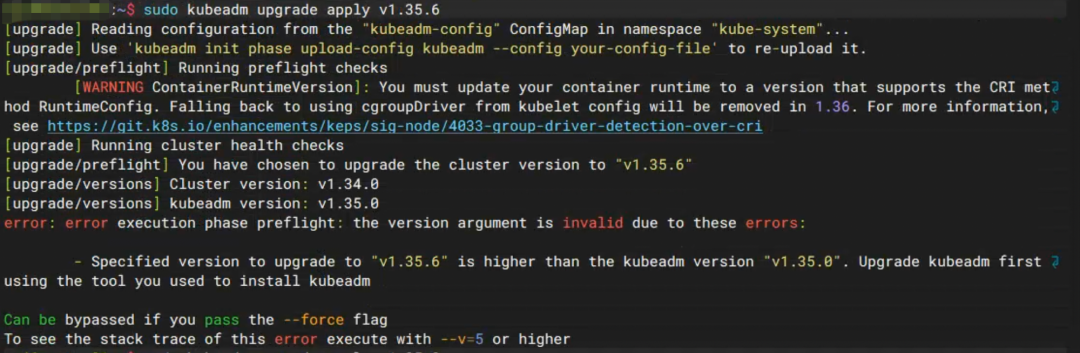
原来 kubeadm 的版本必须 ≥ 目标版本。
先升级 kubeadm:
apt install kubeadm=1.35.6-1.1
再继续。
坑 ②:ContainerRuntimeVersion 告警
升级过程中弹出:
ContainerRuntimeVersion:
You must update your container runtime
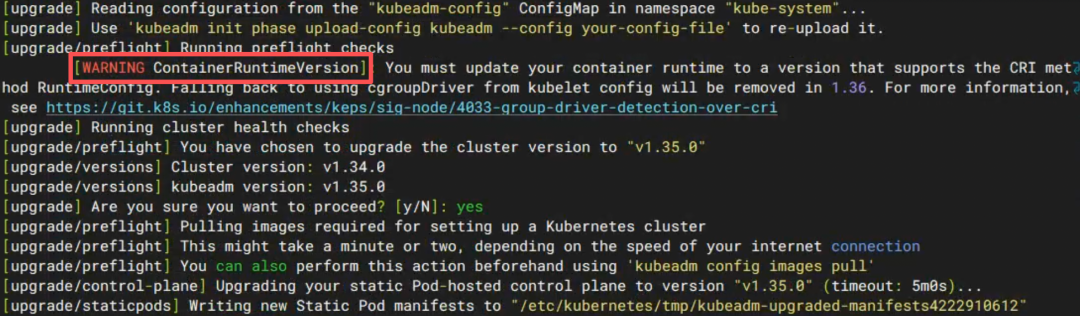
当时心里一紧。
检查 containerd 版本:
containerd --version
# containerd 1.7.24
再检查 kubelet 配置:
grep cgroupDriver /var/lib/kubelet/config.yaml
# cgroupDriver: systemd
确认暂时不影响 1.35 升级,但到了 1.36 之后,containerd 2.x 会成为刚需。建议后续关注。
第一个 Master 升级
控制平面节点的标准流程:
apt install kubeadm=1.35.0-1.1
kubeadm upgrade apply v1.35.0
apt install kubelet kubectl
systemctl restart kubelet
升级完检查:
kubectl get nodes
master01 顺利升级。
坑 ③:etcd 升级超时,自动回滚
升级 master02 时,卡住了:
static Pod hash for component etcd on Node master02
did not change after 5m0s

kubeadm 自动回滚。
查看 kubelet 状态:
systemctl status kubelet
发现一直在重启。
坑 ④:kubelet 启动失败,因为一个废弃参数
日志里看到:
unknown flag: --pod-infra-container-image
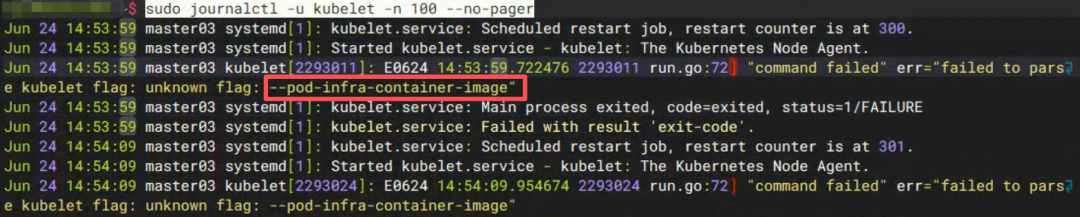
这个参数在新版 kubelet 中已经被移除了。
检查配置文件:
cat /var/lib/kubelet/kubeadm-flags.env
果然还残留着这个参数。
删除参数值后重启:
systemctl daemon-reload
systemctl restart kubelet
节点恢复正常。
坑 ⑤:kubeadm 后置阶段报错
升级结束后弹出:
error backing up the kubelet env file
stat /var/lib/kubelet/kubeadm-flags.env:
no such file or directory
实际上 kubelet 正常运行,节点也 Ready。
这是 kubeadm 在备份历史文件时发现文件不存在,属于非致命错误,可以忽略。
Worker 节点升级流程
Worker 节点的升级步骤是标准的滚动升级:
# 驱逐 Pod
kubectl drain worker01 \
--ignore-daemonsets \
--delete-emptydir-data
# 升级软件包
apt install kubeadm kubelet kubectl
# 执行节点升级
kubeadm upgrade node
# 重启 kubelet
systemctl restart kubelet
# 恢复调度
kubectl uncordon worker01
逐个节点轮替。
坑 ⑥:Drain 失败,因为有个裸 Pod
升级 worker02 时,drain 卡住:
cannot delete Pods that declare no controller
排查发现:
default/recovery-nginx
这是一个没有控制器管理的裸 Pod(没有 Deployment / ReplicaSet / StatefulSet)。
默认情况下 drain 不会删除它。
加上 --force强制驱逐:
kubectl drain worker02 \
--ignore-daemonsets \
--delete-emptydir-data \
--force
顺利通过。
完整升级顺序总结
✅ 升级前检查
✅ etcd 备份
✅ 升级 master01
✅ 验证控制平面
✅ 升级 master02
✅ 升级 master03
✅ drain worker01 → 升级 → uncordon
✅ drain worker02 → 升级 → uncordon
✅ drain worker03 → 升级 → uncordon
✅ 业务验证
最终集群状态
master01 Ready v1.36
master02 Ready v1.36
master03 Ready v1.36
worker01 Ready v1.36
worker02 Ready v1.36
worker03 Ready v1.36
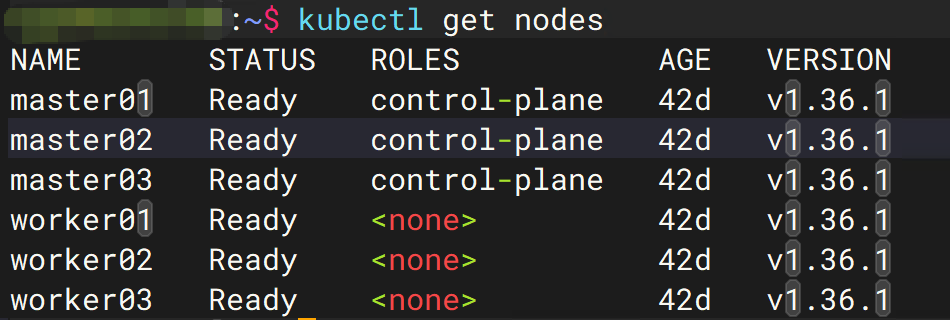
全部升级完成 ✅
这次升级,我学到了什么?
Kubernetes 升级,真正难的不是命令。
难的是:
- 历史遗留配置怎么处理
- 运行时版本是否兼容
- kubelet 参数变了没有
- 软件源配置对不对
- drain 策略有没有坑
- etcd 稳不稳定
升级命令只有几条,但决定成败的,是整个集群的运维状态。
给准备升级的你几点建议
如果让我重新来一次,我会记住这几条:
- 先备份 etcd——这是最后的保险。
- 永远逐版本升级——不要跳,跳了必后悔。
- Master 逐个升级——不要同时动所有控制平面。
- Worker 必须滚动升级——业务优先。
- 升级前检查 kubelet 配置——有些参数说删就删。
- 遇到问题先看 kubelet 日志——大多数答案都在那里。
Kubernetes 升级,从来都不是一次简单的软件更新。
它更像是一场对集群运维能力的综合考试。
希望你的升级之路,比我顺利。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号