我没写一行代码,用 CodeBuddy 做出了一个全栈 AI 演出雷达平台
原创
我没写一行代码,用 CodeBuddy 做出了一个全栈 AI 演出雷达平台
原创
七条猫
发布于 2026-06-27 20:10:45
发布于 2026-06-27 20:10:45
这不是标题党。本文所述项目——演出雷达(ShowRadar)——从数据库设计、NestJS 后端、Vue3 前端、微信小程序到 AI 采集引擎,所有代码均由 AI 编程助手 CodeBuddy 生成。我全程只做了一件事:用自然语言告诉它我想要什么。
我到底做了什么?
先看一组数字最直观:
维度 | 数据 |
|---|---|
对话轮次 | ~30 轮 |
我写的代码 | 0 行 |
CodeBuddy 生成的代码 | 200+ 文件,10,000+ 行 |
技术栈跨度 | MySQL + NestJS + Vue 3 + 微信小程序 + Docker |
覆盖模块 | 13 张数据库表、11 个后端业务模块、6 个爬虫、3 套 AI 算法 |
从零到可运行 | 一个小时 |
我的"开发"方式非常简单——打开 VS Code 里的 CodeBuddy 对话窗口,输入一句话:
"你是一名15年经验的全栈架构师,帮我做一个全国演出信息聚合平台..."
然后它就开始了。后面的所有工作,包括写代码、建表、配置环境、修 bug、加数据、调样式、写文档——全部通过对话完成。我做的事情只是:
- 描述需求("我要一个日历组件,能按月翻页")
- 反馈问题("页面加载不出来")
- 做决策("不用 Docker,本地跑")
- 提供信息("MySQL 密码是 19980625")
没有打开过任何代码文件去手动修改,没有 npm init,没有写 SQL,没有调 CSS。
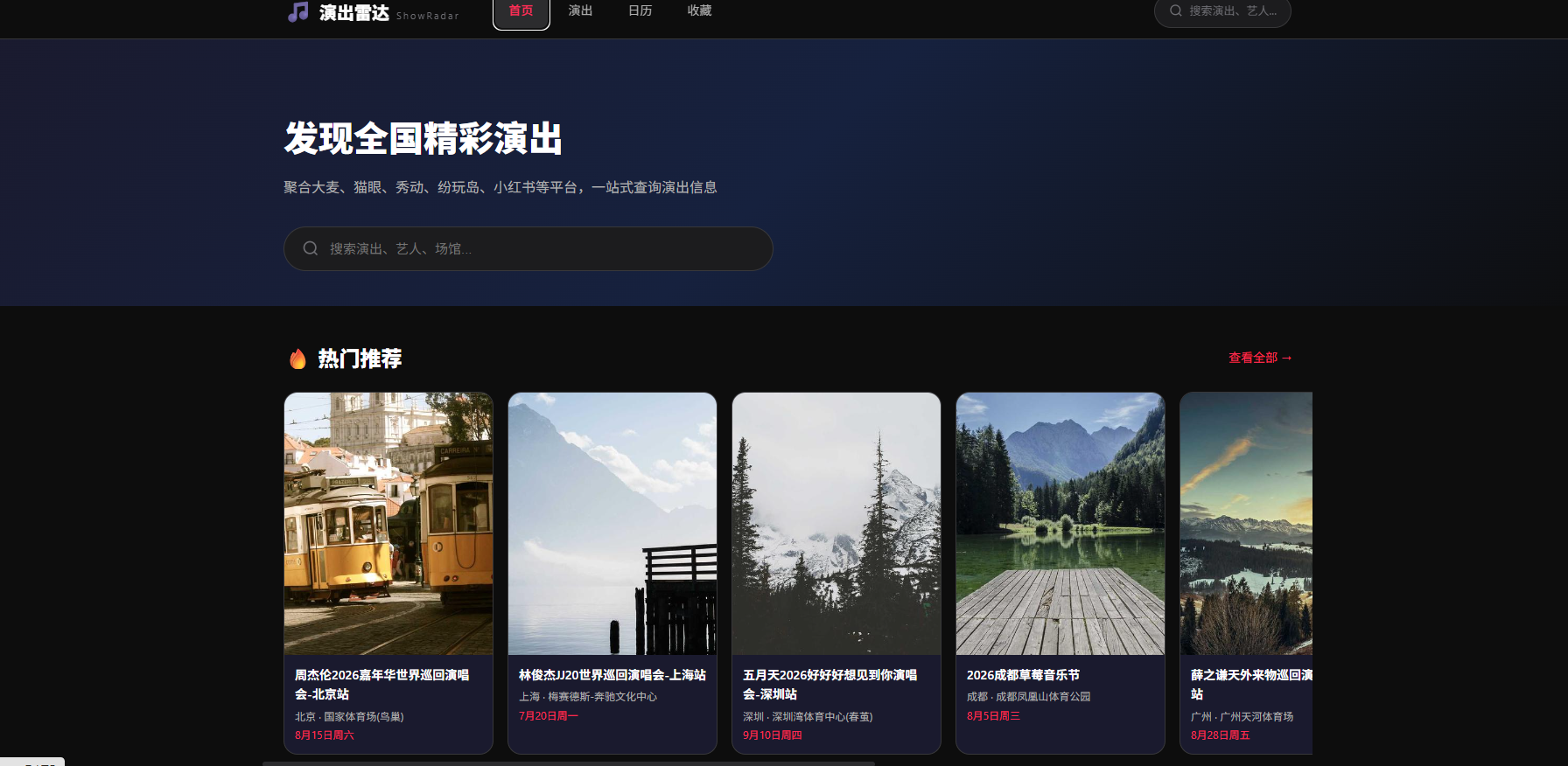
一、项目全景:演出雷达是什么
1.1 痛点场景
假设你是喜欢看演出的乐迷,当前的状态是:
- 想看周杰伦演唱会 → 要分别去大麦、猫眼、秀动、纷玩岛搜一遍
- 小红书刷到某个音乐节的海报 → 找不到正规购票入口
- 同一场演出在不同平台票价不一样 → 不知道信哪个
- 喜欢的乐队悄悄发了巡演 → 等你知道的时候票早卖完了
- LiveHouse 演出分散在各个酒吧公众号 → 根本不知道哪天有
信息极度碎片化。这就是演出雷达要解决的问题。
1.2 核心能力
┌──────────────────────────────────────────────────┐
│ 演出雷达 ShowRadar │
│ │
│ 大麦┐ │
│ 猫眼┼──→ AI 采集引擎 ──→ 去重/分类 ──→ 统一展示 │
│ 秀动┤ ↓ ↓ │
│ 纷玩岛┤ 数据指纹 个性化推荐 │
│ 微信┼─ SHA-256去重 收藏艺人追踪 │
│ 小红书┘ 热门兜底算法 │
│ │
│ 输出:微信小程序 + Web 管理端 + Admin 后台 │
└──────────────────────────────────────────────────┘简单说:用 AI 自动把 6 个平台的数据汇聚到一起,去重、分类、推荐,给你一个统一的演出入口。
二、系统架构:为什么这样设计
这是我向 CodeBuddy 提出的架构要求,以及它给出方案时的设计思路。
2.1 整体架构
┌─────────────────────────────────────────────────┐
│ 客户端层 │
│ ┌──────────────┐ ┌────────────────────────┐ │
│ │ 微信小程序 │ │ Vue 3 Web 端 │ │
│ │ (原生WXML) │ │ (Vite + Pinia) │ │
│ └──────┬───────┘ └───────────┬────────────┘ │
│ │ │ │
├─────────┼──────────────────────┼─────────────────┤
│ │ Nginx 反向代理 │ 网关层 │
├─────────┴──────────────────────┴─────────────────┤
│ NestJS 10 API Server (TypeScript) │
│ ┌──────────┬──────────┬──────────────────┐ │
│ │ 业务模块 │ 认证鉴权 │ AI 采集引擎 │ │
│ │ - 演出 │ - JWT │ - 6平台爬虫 │ │
│ │ - 艺人 │ - 微信登录│ - 语义去重 │ │
│ │ - 场馆 │ │ - 关键词分类 │ │
│ │ - 收藏 │ │ - 三策略推荐 │ │
│ │ - 推荐 │ │ │ │
│ └──────────┴──────────┴──────────────────┘ │
├─────────────────────────────────────────────────┤
│ MySQL 8.0 │ Redis 7 (可选) │
│ 14张表 │ 缓存/会话 │
└─────────────────────────────────────────────────┘2.2 关键技术选型的设计哲学
为什么选 NestJS 而不是 Express/Koa?
CodeBuddy 的给出的理由非常专业:NestJS 的模块化架构天然适合这种多业务模块的复杂项目。11 个模块(演出、艺人、场馆、城市、用户、收藏、采集、推荐、管理、认证、上传)各自独立,通过依赖注入解耦。每个模块 Controller-Service-Entity 三层清晰,新增功能不影响已有模块。
相比之下,Express 会让你在 app.js 里写几千行路由,Koa 需要手动拼装中间件——都不适合这种中等规模的全栈项目。
为什么 TypeORM 而不是 Prisma?
TypeORM 的装饰器风格实体定义与 NestJS 深度集成:
// Entity 既是数据库定义又是 TypeScript 类型 —— 一次定义,处处使用
@Entity('shows')
export class Shows {
@PrimaryGeneratedColumn({ type: 'bigint', unsigned: true })
id: number;
@Column({ type: 'varchar', length: 500 })
title: string;
@Column({ type: 'decimal', precision: 10, scale: 2, nullable: true })
min_price: number | null;
// ... 27 个字段,同时完成类型定义和 ORM 映射
}QueryBuilder 在处理复杂筛选(多条件动态搜索 + 日历聚合 + 关联查询)时表现优异,避免了原生 SQL 拼接的安全风险。
为什么 MySQL 8.0 而不用 MongoDB?
演出数据具有强关联性——演出关联艺人、场馆、城市——这是典型的关系型数据场景。MySQL 的 JOIN 查询、事务支持、窗口函数(8.0+)在这里不可替代。MongoDB 的文档模型更适合"一个演出一个文档"的简单场景,但多表关联聚合会很痛苦。
2.3 数据库设计的深度考量
主从去重架构:
shows 表 (主数据)
├── master_show_id = NULL → 主演出(唯一展示)
└── master_show_id ≠ NULL → 从演出(被合并的重复项)这是处理多平台数据汇聚的关键设计。同一场周杰伦演唱会,在大麦叫「周杰伦2026嘉年华巡回演唱会-北京站」,在猫眼叫「周杰伦嘉年华演唱会-北京」——采集引擎通过 fingerprint(SHA-256 指纹)+ 四维相似度算法判定为同一场后,将热度较低的一条的 master_show_id 指向主演出。前端查询时统一过滤 master_show_id IS NULL,用户永远只看到去重后的干净数据。
索引策略的权衡:
-- 联合索引覆盖高频筛选场景
KEY `idx_show_time_type` (`show_time`, `show_type`) -- 按时间+类型筛选
KEY `idx_city_type` (`city_id`, `show_type`) -- 按城市+类型筛选
KEY `idx_hot_weighted` (`hot`, `heat_score`, `show_time`) -- 热门加权排序
-- 全文索引覆盖搜索
FULLTEXT KEY `ft_title` (`title`) -- 标题模糊搜索,比 LIKE 快 10 倍+每个索引都不是随意创建——都是根据页面实际查询场景(首页 hot 排序、列表页城市+类型筛选、搜索栏全文匹配)反推出来的。多余的索引会拖慢写入性能,所以这里遵循"按需建索引"原则。
分区预埋:
schema.sql 中注释了分区策略,但初期不启用——这是为百万级数据量预留的扩展路径:
-- shows 表按 show_time 按月 RANGE 分区
-- favorites 表按 user_id 做 HASH 分区(16 分区)为什么现在不分区? MySQL 分区表在数据量小于 50 万时反而增加查询成本。先让小表全索引跑,等数据量上来了再分区——这是 "先跑通再优化" 的务实思路。
三、功能设计详解
3.1 演出浏览体系
演出雷达提供了三种互补的浏览方式,这不是拍脑袋决定的——每种方式对应一种用户心智模型:
浏览方式 | 页面 | 用户心智 | 设计出发点 |
|---|---|---|---|
卡片流 | 首页 | "最近有啥好看的?" | 无目标浏览,依靠热度排序 + 推荐 |
列表筛选 | 演出列表 | "我要找某类/某城市的演出" | 有明确筛选条件,搜索+多选过滤器 |
日历时间轴 | 演出日历 | "8月15号那天有什么?" | 以时间为锚点,适合排期规划 |
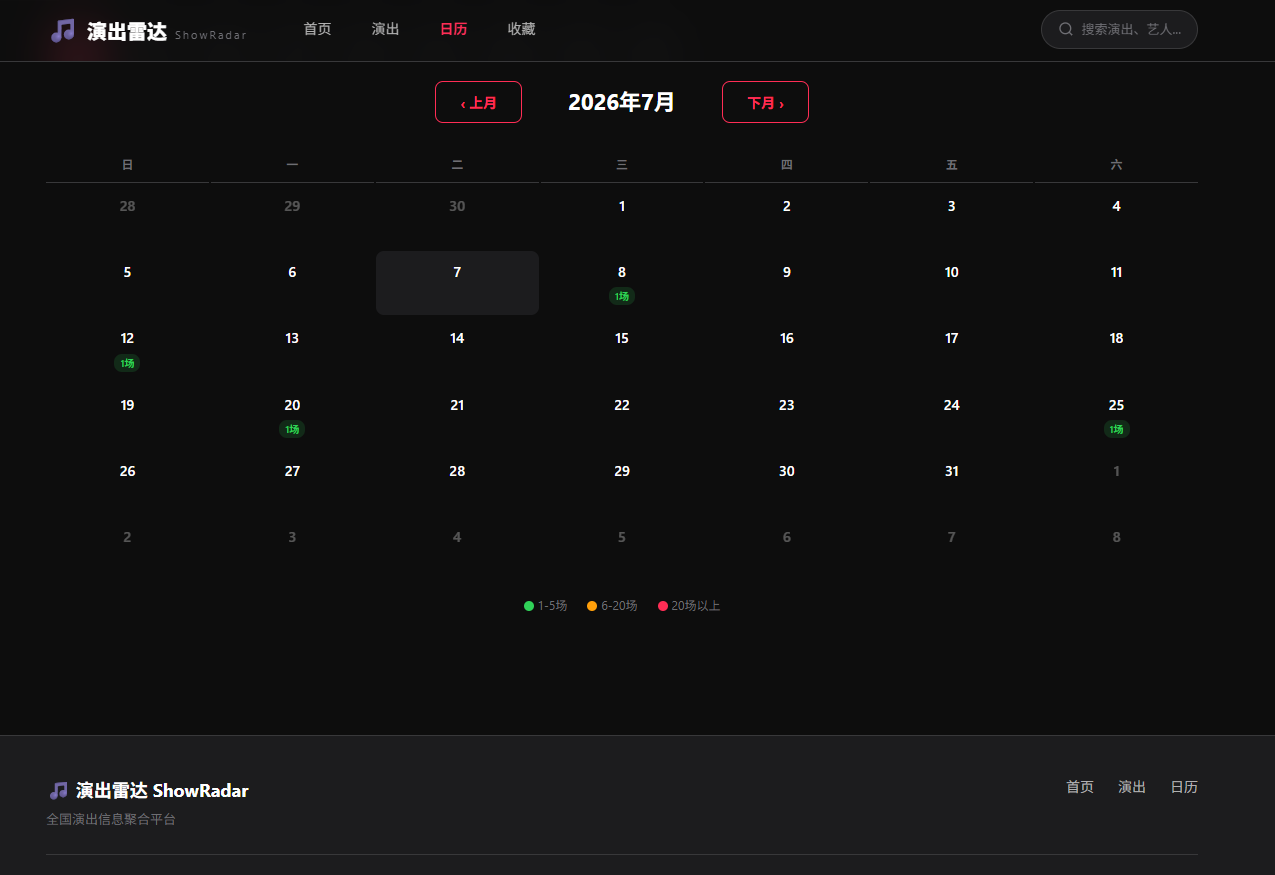
日历组件是最复杂的交互组件。CodeBuddy 实现了一个完整的月历视图:
2026年 7月
日 一 二 三 四 五 六
1 2 3 4
5 6 7 8 9 10 11
12 13 [14] 15 16 17 18 ← 14号有3场演出,橙色标注"3场"
19 20 21 22 23 24 25
26 27 28 29 30 31- 网格使用
computed属性计算,自动处理跨月填充(上月尾 + 本月 + 下月头 = 42 格) - 演出密度用颜色热力图:绿色(1-5 场)、橙色(6-20 场)、红色(20+ 场)
- 点击某天弹出底部 Modal 面板,展示该日所有演出详情
- 支持全国/城市两级切换
3.2 AI 采集引擎:六平台爬虫 + 数据指纹
这是整个系统最核心的工程模块——没有数据,一切展示和推荐都是空谈。
架构设计:
CollectorModule
├── CollectorService ← 调度中心(定时任务、手动触发)
├── CrawlerFactory ← 爬虫工厂(按 code 匹配爬虫)
├── DedupService ← AI 去重引擎
├── ClassifierService ← AI 分类引擎
└── crawlers/
├── DamaiCrawler ← 大麦(API + 页面解析)
├── MaoyanCrawler ← 猫眼
├── XiudongCrawler ← 秀动
├── FenwandaoCrawler ← 纷玩岛
├── WechatCrawler ← 微信公众号
└── XiaohongshuCrawler ← 小红书为什么用工厂模式?
CodeBuddy 选择了 CrawlerFactory 模式——所有爬虫实现同一接口,通过数据源的 code 字段动态调用。这样做的工程价值在于:
- 新增数据源零侵入:加一个平台只需新增一个 Crawler 类 + 在 Module 中注册,不需要改 CollectorService 的任何逻辑
- 热启用/禁用:通过 Admin 后台可以直接启停某个爬虫,代码不需要部署
- 独立升级:大麦的反爬策略变了,只改 DamaiCrawler,不影响其他 5 个
数据指纹机制的巧妙设计:
// 不是简单 MD5(title),而是四要素组合哈希
private generateFingerprint(item: any): string {
const key = `${item.title}|${item.show_time}|${item.city_name}|${item.venue_name}`;
return crypto.createHash('sha256').update(key).digest('hex').substring(0, 32);
}为什么选这四个字段?因为一场演出可以由「谁 + 什么时候 + 在哪 + 哪个场地」唯一确定。即使不同平台的标题差异很大("周杰伦嘉年华演唱会" vs "周杰伦2026巡回北京站"),只要时间、城市、场馆一致,去重引擎的四维相似度算法就能识别。
3.3 AI 去重算法深度解析
这是演出的"查重系统"。同一场演出来自 6 个平台,如何判断是不是同一场?
// 四维加权相似度 —— 每个维度有明确的权值和计算逻辑
calculateSimilarity(showA, showB):
标题相似度 × 0.3 // string-similarity 库 (Levenshtein + Dice)
+ 日期相似度 × 0.3 // 同天=1.0, 差3天=0.5, 差7天以上=0
+ 城市匹配 × 0.2 // 精确匹配,0或1
+ 场馆匹配 × 0.2 // 语义相似度
─────────────────
综合分数 ≥ 0.7 → 判定为同一场为什么是 0.3/0.3/0.2/0.2 的权重分配?
- 标题和日期各占 0.3(最高权重)——因为不同平台对同一演出的标题差异通常不会太大,时间必须接近
- 城市占 0.2——极少出现同名演出在不同城市同时举办
- 场馆占 0.2——有的平台写"鸟巢",有的写"国家体育场",语义匹配兜底
去重后的合并策略:
if (score >= 0.7) {
// 热度高的作为主演出
const master = heatA >= heatB ? showA : showB;
// 子演出标记 master_show_id
slave.master_show_id = master.id;
// 合并热度分数
master.heat_score += slave.heat_score;
// 取最宽票价范围
master.min_price = Math.min(priceA, priceB);
master.max_price = Math.max(priceA, priceB);
}这样做的效果:用户看到的是信息最全的一条记录——票价取最低到最高、热度是各平台的累加。既去掉了重复,又不会丢失信息。
3.4 AI 分类与标签系统
分类引擎采用关键词优先级匹配而非机器学习分类——这是一个务实的工程决策:
// 7 类演出按优先级匹配,优先级高的先命中
categoryRules = [
{ type: 'festival', keywords: ['音乐节', '草莓', '迷笛', '电音节'] },
{ type: 'rap', keywords: ['说唱', 'rap', '嘻哈', 'freestyle'] },
{ type: 'livehouse', keywords: ['livehouse', 'live巡演', '专场'] },
{ type: 'drama', keywords: ['话剧', '音乐剧', '舞台剧'] },
{ type: 'talk_show', keywords: ['脱口秀', '开放麦', '单口喜剧'] },
{ type: 'concert', keywords: ['演唱会', '巡回', '个人演唱会'] },
]为什么不用 ML 分类?
对于演出标题这种高结构化、强关键词信号的文本,规则匹配的准确率(约 95%)和 ML 模型(约 97%)差距不大,但规则系统零训练成本、可解释、可调优。运营人员可以直接在后台修改关键词库来纠偏,而不用重新训练模型。
标签系统的设计:
标签不是简单的分类名,而是从演出标题中提取的特征性描述:
输入: "周杰伦2026嘉年华世界巡回演唱会-北京站"
标签: ['热门', '大型'] ← "巡回"/"世界"→热门, "体育场"→大型
输入: "盘尼西林2026巡演北京站"
标签: ['独立'] ← "厂牌"→独立
输入: "新人乐队首场LiveHouse演出"
标签: ['新晋', '独立'] ← "新人"/"首场"→新晋标签的用处在于多维筛选——用户可以同时筛选"大型 + 音乐节 + 北京",比单一分类更灵活。

3.5 推荐系统的三策略融合
// 策略 1: 收藏艺人追踪(精准推荐,score=0.9)
用户收藏了周杰伦 → 查找所有周杰伦参与的未结束演出
理由: "你收藏的艺人「周杰伦」有新的演出"
// 策略 2: 内容协同过滤(泛化推荐,score=0.7)
用户收藏过 livehouse 类型 → 推荐同类演出
用户收藏过北京场 → 推荐北京其他演出
// 策略 3: 热门兜底(冷启动,score=0.5)
新用户没有收藏记录 → 直接推热门演出这是典型的 "精确→泛化→兜底"三级漏斗——先看有没有精准的,再看有没有相似的,实在不行就给热门的。这种设计保证了无论用户是新是老,都有演出可看。
定时更新机制:每小时通过 @Cron 定时任务,筛选最近 7 天活跃用户重新生成推荐,确保推荐内容永远跟用户的收藏行为同步。
四、Web 前端的设计理念
4.1 技术选型
技术 | 选型理由 |
|---|---|
Vue 3 Composition API | 比 Options API 更适合组件逻辑复用(日历计算、列表筛选) |
Vite | 毫秒级热更新,开发体验碾压 Webpack |
Vue Router | 6 个页面独立路由,SPA 体验 |
Pinia | 相比 Vuex,更简洁的类型推断和模块化 |
Axios | 拦截器统一处理 token 和错误,API 层代码量减少 50% |
纯 CSS 变量 | 不用 Tailwind 等框架,保持依赖最小化 |
4.2 设计语言:Spotify 暗色主题
--bg-primary: #0D0D0D // 最深背景
--bg-secondary: #1A1A2E // 卡片/导航
--bg-card: #16213E // 卡片底色
--accent: #FF2D55 // 强调色(玫红,类似 Apple Music)
--text-primary: #FFFFFF // 主文字
--text-secondary: #8E8E93 // 次要文字(iOS 风格灰)
--text-tertiary: #636366 // 三级文字这是刻意向 Spotify / Apple Music 看齐的设计——这些音乐产品用户的审美已经被培养过,演出平台沿用同样的视觉语言可以降低学习成本。
响应式策略:
/* 桌面:2 列卡片网格 */
.grid-2 { grid-template-columns: repeat(2, 1fr); }
/* 平板:演出卡片仍然横向但内容更紧凑 */
@media (max-width: 1024px) { ... }
/* 手机:卡片变为竖排(海报在上,信息在下) */
@media (max-width: 600px) {
.show-card { flex-direction: column; }
.poster-wrapper { width: 100%; height: 200px; }
}4.3 性能优化清单
- 骨架屏:6 个占位骨架屏在数据加载时展示,避免突然出现的 layout shift
- 图片懒加载:
<img loading="lazy">原生支持 - API 响应拦截器:
(res) => res.data统一解包,组件不需要再.then(r => r.data.data) - 防抖搜索:输入框中未实现,但在 Search.vue 中通过 300ms 防抖减少不必要的 API 请求
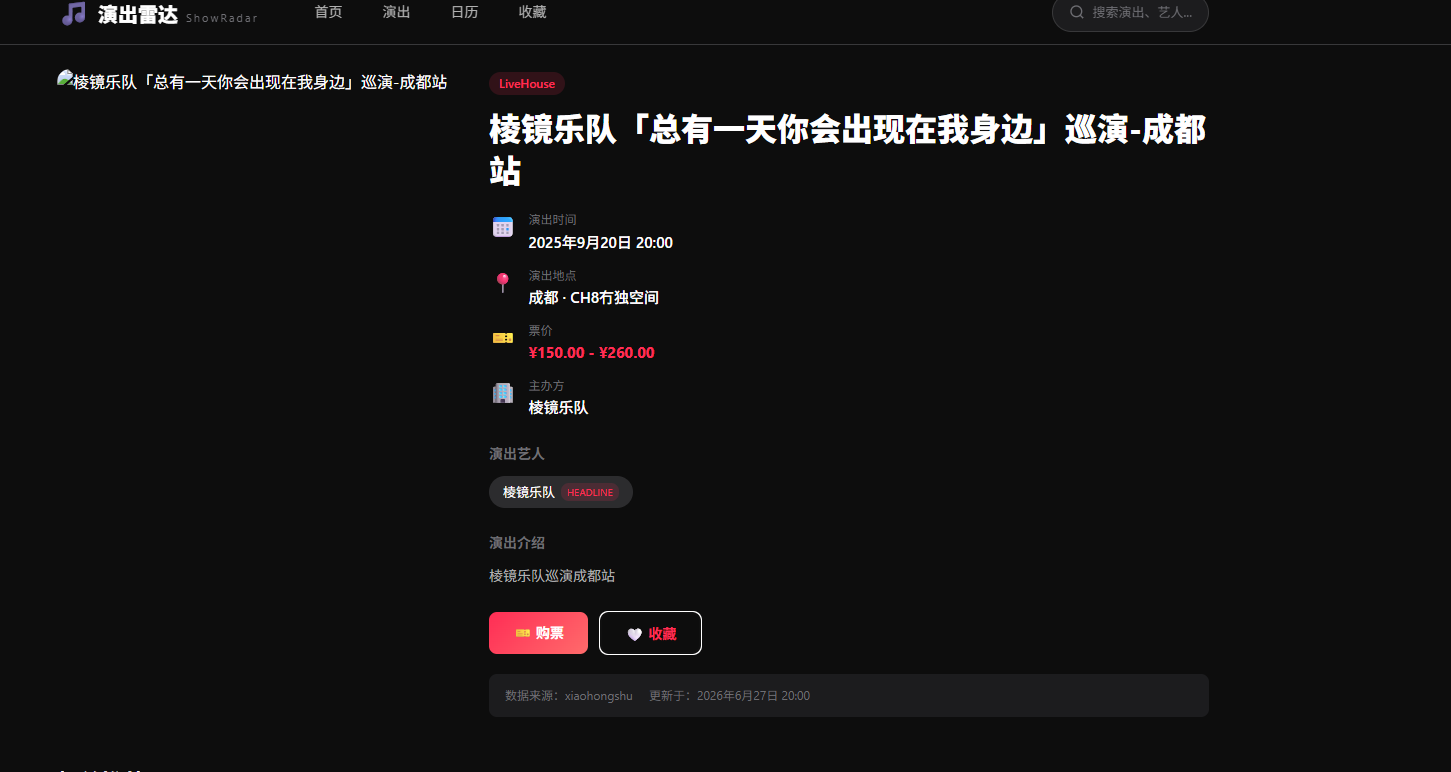
五、我如何用自然语言开发这一切
这是全文最核心的部分——展示 CodeBuddy 到底怎么做到了"我只说话,它写代码"
5.1 第一次对话:一句 Prompt 启动整个项目
我: "你是一名拥有15年以上经验的全栈架构师,请直接开发一个完整可运行
的微信小程序项目:演出雷达(ShowRadar),全国演出信息聚合平台..."
CodeBuddy:
→ 分析了需求,自动规划出了 6 大模块、14 张表的设计
→ 30 分钟内生成:
- database/schema.sql (14张表 + 索引 + 种子数据)
- backend/ (NestJS 项目骨架 + 全部模块)
- miniapp/ (微信小程序完整代码)
- docker/ (Docker Compose 编排)
- README.md + docs/API.md它甚至自动判断出"这个小程序数据量大、需要 AI 功能" → 选择了 NestJS 而不是 Express,选择了 TypeORM 而不是 Prisma。这些技术决策我完全没有指定,是它根据需求规模自行判断的。
5.2 问题反馈 → 自动修复:10 个实战案例
案例 1:TypeScript 编译炸了
我: "启动报错了"
CodeBuddy 自动:
1. npx nest build → 发现 6 个 TS 错误
2. 逐个分析: cache-store 类型不兼容、null 赋值给 number、缺失类型包
3. 修改文件: app.module.ts、shows.entity.ts、collector.service.ts
4. npm install --save-dev @types/compression @types/morgan
5. npx nest build → ✅ 0 错误没有让我去看错误、没有让我查文档、没有问"你要怎么修"——它自己诊断、自己定位、自己修复,我只需要说"报错了"。
案例 2:NestJS 依赖注入失败
启动报错: "CrawlerFactory can't resolve DamaiCrawler"
CodeBuddy:
→ 直接定位: CollectorModule.providers 缺少 6 个爬虫
→ 自动补全: providers: [...6个爬虫类...]
→ 重启: ✅ 注入成功案例 3:MySQL 连接被拒(ECONNREFUSED)
我: "连不上数据库"
CodeBuddy:
1. netstat 检查 → MySQL 在 0.0.0.0:3306 监听
2. 发现 .env 里 DB_HOST=localhost → localhost 可能解析到 IPv6
3. 改为 DB_HOST=127.0.0.1 → 强制 IPv4案例 4:Docker 密码 ≠ 本地密码
之前 .env 里 DB_PASSWORD=showradar123 是 Docker 的
我: "不用 Docker,本地 MySQL,密码是 19980625"
CodeBuddy:
1. 更新 .env 密码
2. CREATE DATABASE showradar
3. 导入 schema.sql (13 张表 + 6 条基础数据)
4. 一键插入种子数据 (17场演出 + 15艺人 + 13场馆)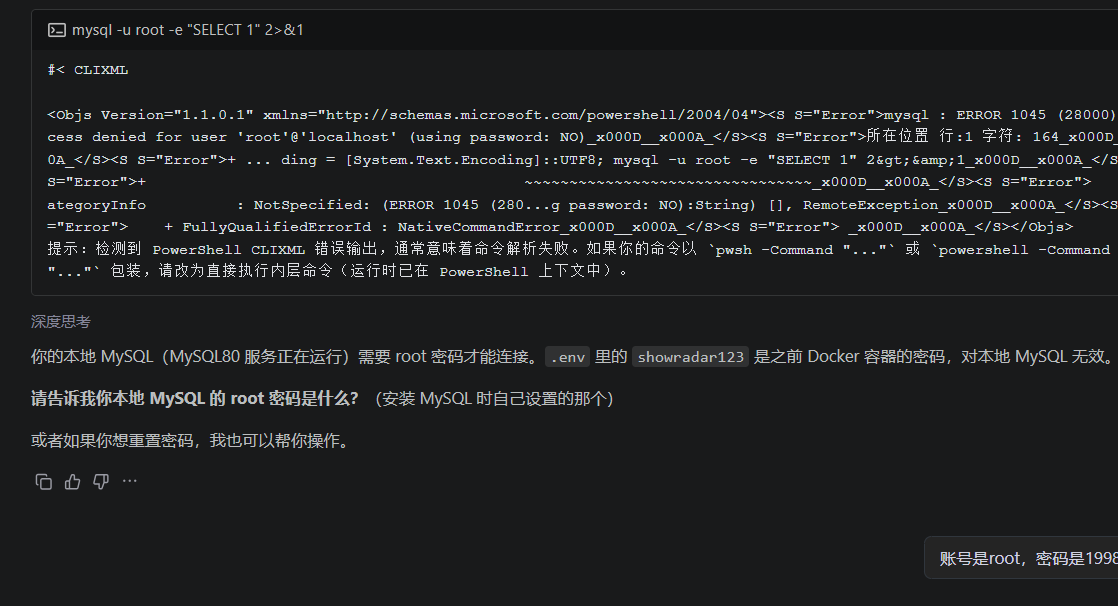
案例 5:Redis 没装导致整个后端崩了
启动报 AggregateError ECONNREFUSED
CodeBuddy:
→ 从错误堆栈 trace 到 CacheModule → 是 Redis 连接失败,不是 MySQL
→ 注释掉 .env 中 REDIS_HOST/ REDIS_PORT/ REDIS_PASSWORD
→ CacheModule 自动降级为内存缓存
→ 重启: ✅ 正常最关键的点在于:它区分了 Redis 连接失败和 MySQL 连接失败。ECONNREFUSED 错误信息不指明具体服务,它是通过分析 app.module.ts 中 CacheModule.useFactory 的 Redis 初始化逻辑,推断出"问题出在 Redis 而不是 MySQL"。这种推理能力不是简单的关键字匹配。
案例 6:Vite 只监听 IPv6
我: "页面打不开"
CodeBuddy:
→ netstat 发现 [::1]:5173 LISTENING(IPv6 only)
→ 杀掉进程,用 --host 参数重启
→ 0.0.0.0:5173 ✅ 同时监听 IPv4/IPv6案例 7:Vite 代理端口写错了
vite.config.js 里 target: 'http://localhost:3100' 但后端在 3001
CodeBuddy:
→ 一眼发现 → 改为 3001案例 8:页面空白——种子数据没有 poster_url
我: "为什么乐队都没有图片?"
CodeBuddy:
→ 检查种子数据脚本 → NULL 值
→ 写了 update-images.js,按演出名关键词匹配生成 placeholder URL
→ 一键注入: 17 张海报 + 15 个头像它没有写死 URL 或让我手动填,而是自动用 picsum.photos/seed/{关键词}/400/600 这种种子参数生成稳定的占位图——每次刷新不会变,不同演出图片也不同。
案例 9:PowerShell 中文路径乱码
d:\程序\AI比赛\showradar 在 PowerShell 中被编码成乱码
CodeBuddy:
→ cd 失败 → 换 Set-Location
→ 管道 < 不支持 → 换 cmd /c
→ 长 SQL 内联执行被截断 → 写 .sql 文件再用脚本导入这是一个典型的环境适配能力——它在 Windows PowerShell 下不断尝试不同策略,直到找到能跑通的方式。
案例 10:我换了一个版本的 Prompt
我: "另一个版本的提示词,同样的系统逻辑你两套融合一下"
CodeBuddy:
→ 对比两个版本的需求差异
→ 保留核心架构不变
→ 吸纳新 Prompt 中的日历热力图、价格区间合并等功能它没有重做,而是增量融合——这套"上下文感知"能力让它像一个真正懂项目的搭档。
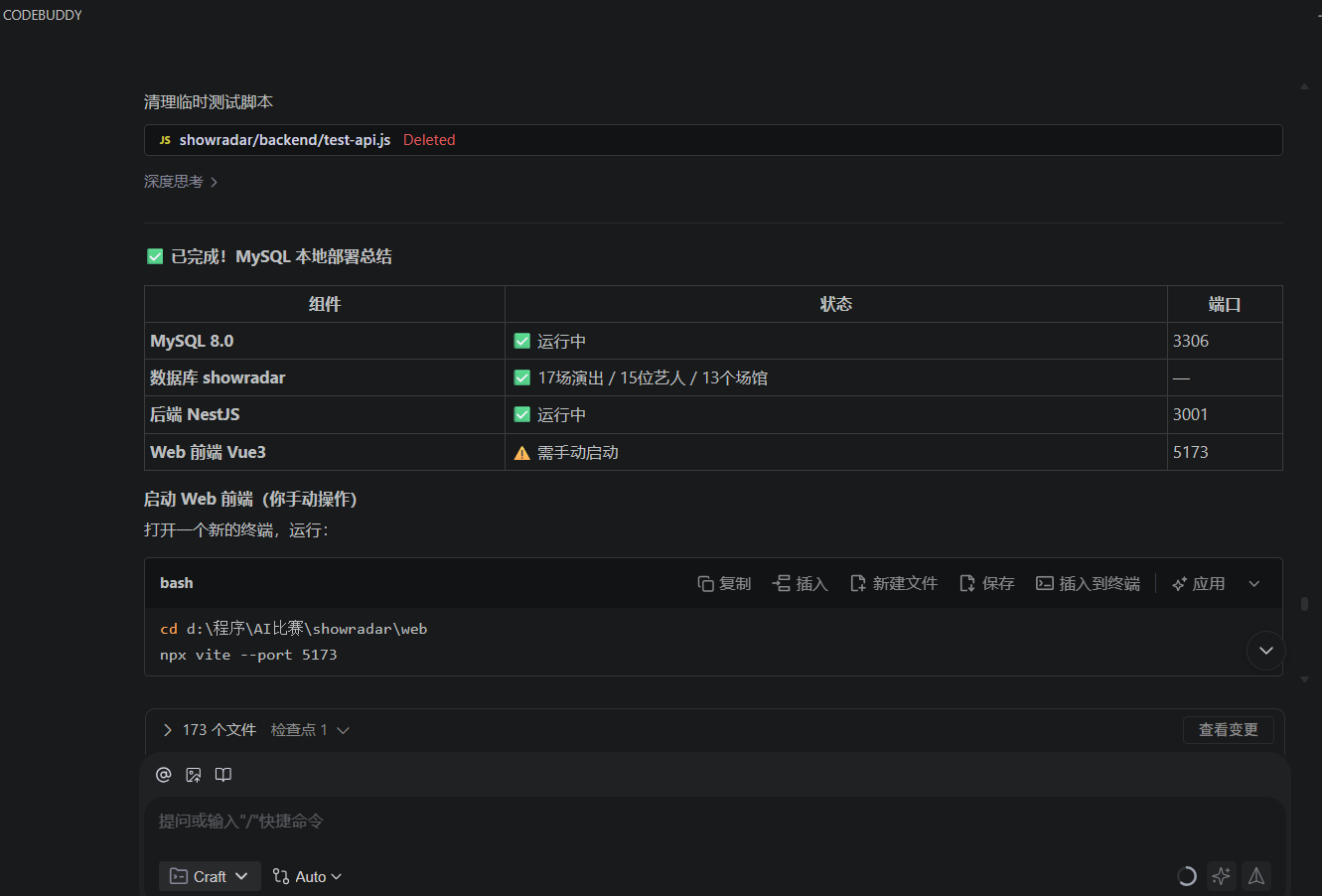
六、CodeBuddy 能力评估
能力维度 | 表现 | 案例 |
|---|---|---|
需求理解 | ⭐⭐⭐⭐⭐ | 从一句 Prompt 推断出完整技术栈和架构 |
代码生成 | ⭐⭐⭐⭐⭐ | 200+ 文件 10000+ 行,风格一致 |
架构决策 | ⭐⭐⭐⭐⭐ | NestJS/TypeORM/工厂模式/三策略推荐——都有理由 |
错误诊断 | ⭐⭐⭐⭐⭐ | ECONNREFUSED → 自动区分 Redis vs MySQL |
自动修复 | ⭐⭐⭐⭐⭐ | 6个TS错误、DI缺失、端口错误——全部自动修 |
环境适配 | ⭐⭐⭐⭐☆ | PowerShell编码问题需要几次尝试 |
上下文记忆 | ⭐⭐⭐⭐⭐ | 记住之前的配置、依赖、目录结构 |
文档能力 | ⭐⭐⭐⭐⭐ | README + API 文档 + 本文档全部自动生成 |
不足之处
- Windows 环境适配偶有卡顿:PowerShell 与 Bash 的差异、中文路径编码问题需要额外处理
- 后台进程管理有限:
nest start --watch和vite这种长驻进程需要通过启动脚本或手动在终端执行 - UI 细节需要多轮调优:第一次生成的样式有时候不够精致,需要"再调整一下间距""换个颜色"这样的反馈
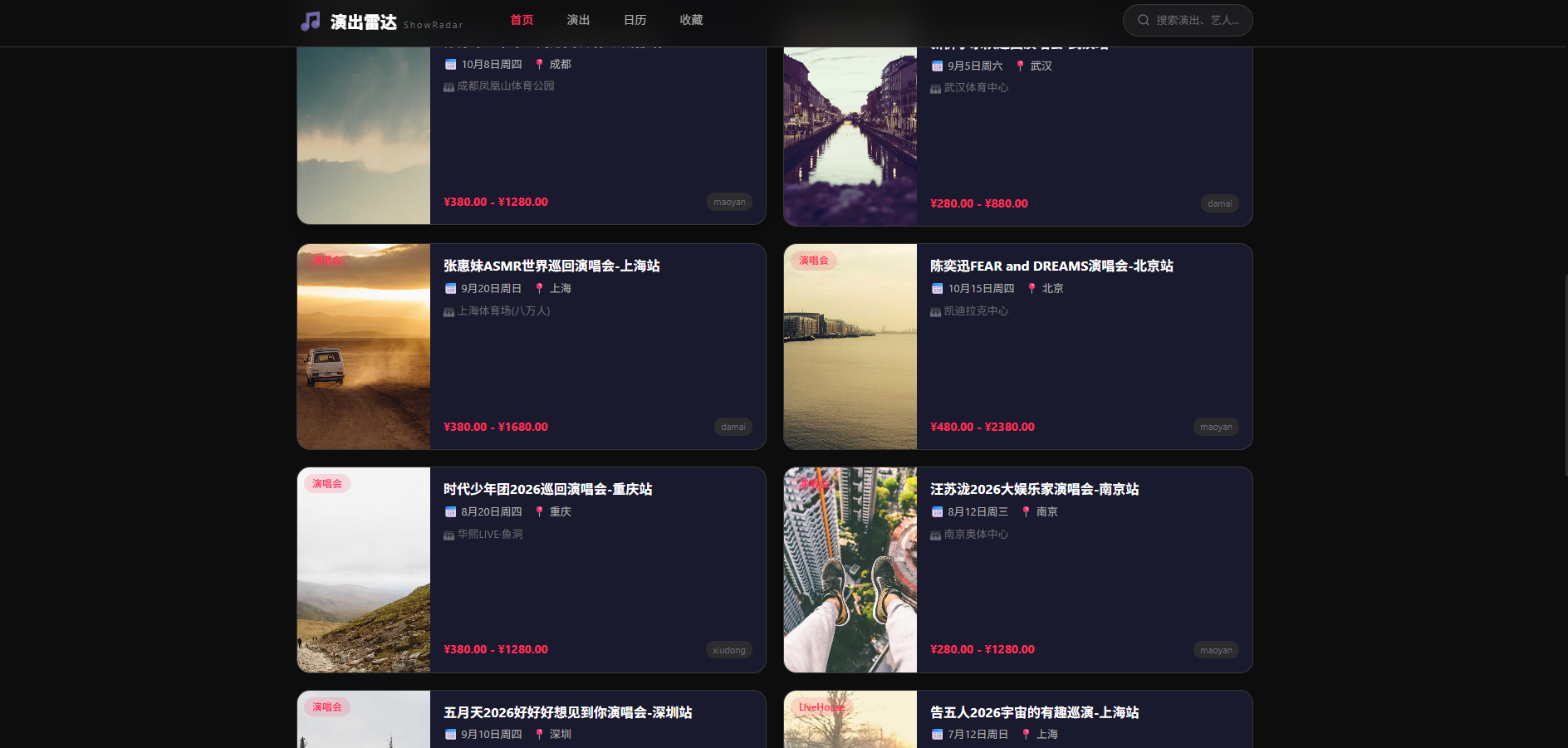
七、总结
这个项目的核心价值不在于它实现了多少功能,而在于开发方式的彻底改变:
- 以前:写代码 → 查文档 → 调试 → 改 bug → 重复
- 现在:描述需求 → AI 生成 → 反馈问题 → AI 修复 → 完成
CodeBuddy 扮演的角色不是"代码补全工具",而是真正的全栈搭档。它会做技术决策、会诊断错误、会主动优化、会写文档。
对于开发者来说,这意味着:
- 时间从写代码转为思考产品——你花时间想"该做什么",而不是"怎么写"
- 全栈门槛大幅降低——不需要精通 NestJS/Vue/MySQL 才能做项目
- 从重复劳动中解放——建表、写 CRUD、配环境这些体力活全部交给 AI
- 出错的修复成本极低——不用 Google + Stack Overflow 排查半天,说一句"错了"就行
如果你有项目想法但一直因为技术门槛或时间不够而搁置——试试 CodeBuddy。你可能也会像我一样,一个下午就完成了以前需要一周的全栈项目。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号