用了 AI 反而慢了 19%,为什么 88% 的人还在每天都用?
原创
用了 AI 反而慢了 19%,为什么 88% 的人还在每天都用?
原创
ranky
修改于 2026-06-25 15:31:00
修改于 2026-06-25 15:31:00
用了 AI 反而慢了 19%,为什么 88% 的人还在每天都用?
2025 年 7 月,研究机构 METR 做了一个让整个行业不太想聊的实验。
他们找来 16 名开源社区的大牛——平均 22000+ Stars,工作在百万行代码的仓库里。每人从同一个真实 issue 池里领任务。一半人可以用当时最强的 Cursor Pro + Claude,另一半纯手写。
246 个任务。每个耗时约 2 小时。开发者时薪 150 美元。
结果:用了 AI 的那组,完成时间反而延长了 19%。
但问他们"你觉得自己快了多少"——回答是:快了 20%。
AI 到底是在帮我们变快,还是在制造一种"变快了"的错觉?
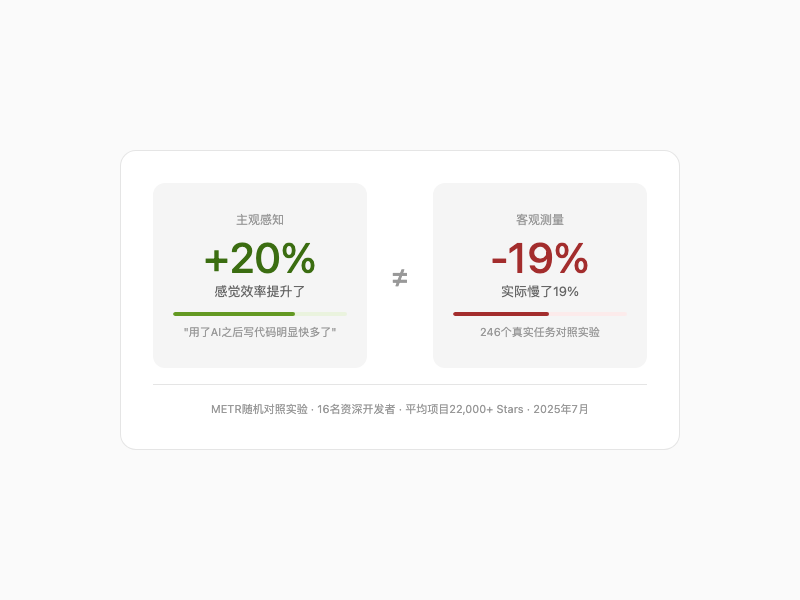
效率悖论:感知快了20%,实测慢了19%
这个反直觉的结论不是个案。
2026 年 1 月,Opsera 发布了一份覆盖 25 万开发者、60+ 家企业的报告。受控实验里,AI 工具让任务速度提升 30-55%。听起来不错。但算上完整的代码审查、调试和重构——净提速只有 18%。
付出也不小。AI 代码的安全漏洞多了 15-18%,平均每个开发者多出 9% 的 Bug。
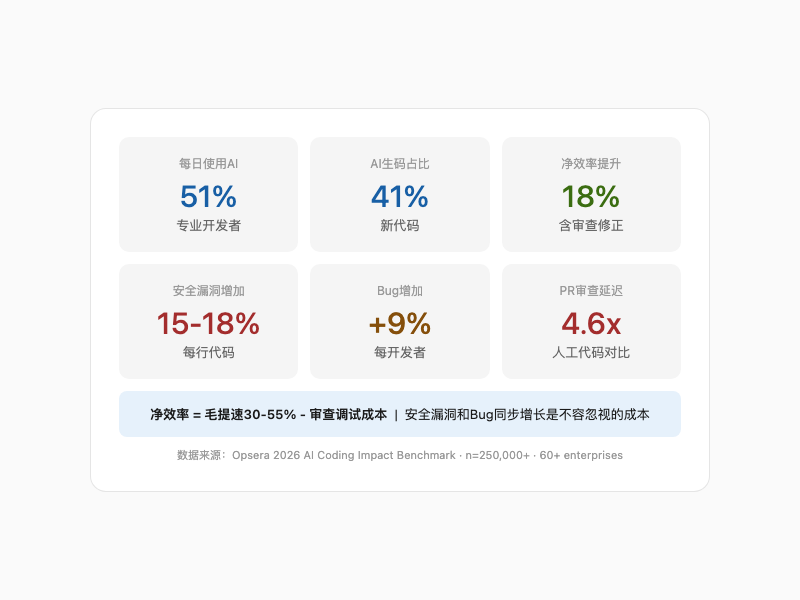
Opsera 2026 AI编程关键指标
Stack Overflow 2025 调查补上了另一刀。84% 的开发者用 AI,但最主流的 GitHub Copilot——月活 1500 万——满意度只有 9%。Claude Code 是 46%,Cursor 是 19%。
量大,但不满。大多数人选工具,不取决于"哪个最好",取决于"公司买了哪个"。
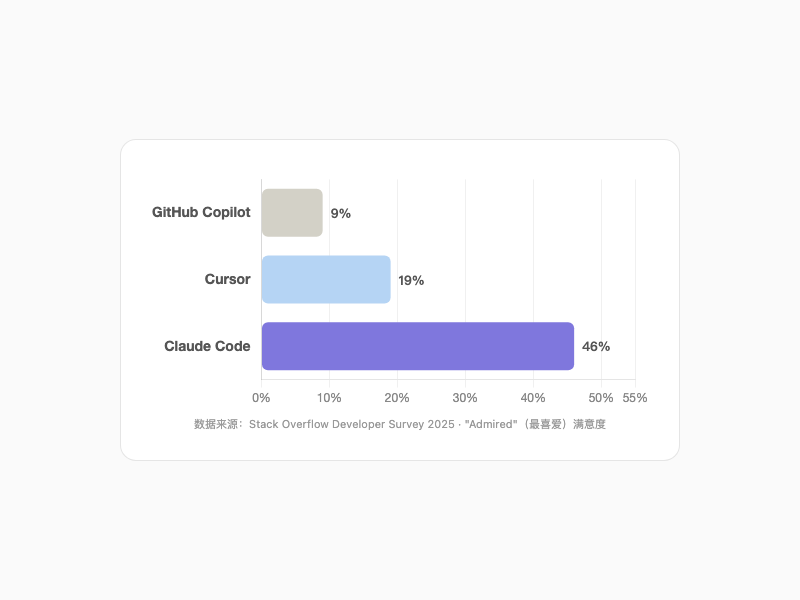
AI工具满意度对比
信任度也在滑坡。仅 33% 的开发者信任 AI 输出,比 2023 年少了 9 个百分点。好感度从 77% 跌到 60%。Opsera 还发现,AI 写的 Pull Request 等审查的时间是人工代码的 4.6 倍。
信任赤字,变成了实打实的流程瓶颈。
AI 确实让你变快了——在有些地方
先说不争的事实。
样板代码。 带分页、搜索、排序的表格组件。过去熟练工 40 分钟起——搭 TypeScript 接口、绑状态管理、写事件处理器、覆盖加载态和错误态。
现在:自然语言描述,30 秒出骨架,10 分钟微调。
省下来的不是"写代码"的时间,是"不想写但必须写"的机械劳动。GitHub 的研究显示,Copilot 用户每天平均接受 312 次代码建议,接受率 27%。一天里 300 多次,不用从零手敲。
后端也一样。CRUD 接口、数据库迁移脚本、测试模板——AI 出骨架再微调,效率提升 60-80%。
学新技术。 以前接手一个新框架,标准流程:读文档、搭环境、跑 demo、踩两三天配置坑。
现在把项目上下文和目标一起丢给 AI。半小时,从"完全不懂"到"能写能改"。
Stack Overflow 2025:69% 的开发者在过去一年学了新语言,44% 用 AI 辅助学习——比 2024 年涨了 7 个百分点。
代码审查。 人会累。第三个 PR 注意力漂移,第五个空指针跳过,第十个格式"大概扫一眼"。
AI 不累。把 20 个低级错误同时丢给三个审阅者和一个 AI——AI 检出率接近 95%,人类平均 70%,而且越到后面越差。
函数注释、API 文档、CHANGELOG——这些高耗时低价值的东西,AI 处理效率提升 30-50%,几乎感知不到质量下降。
那个你没注意到的代价
上面这些故事,行业喜欢讲。下面这些,不太讲。
最危险的代码:几乎正确
Stack Overflow 2025 有一个数据,所有带团队的人都该反复看:66% 的开发者把"几乎正确但不完全正确的 AI 方案"列为最大挫败来源。 45% 表示调试 AI 代码花的时间超过预期。
"几乎正确"比"完全错误"危险太多。
完全错误的代码一眼能识别。几乎正确的——逻辑自洽、编译通过、大部分场景能跑。只是某个边界条件下静默失败。
等你发现的时候,已经在这个代码上垒了三天新功能。
一个典型:退款逻辑模块。AI 写的顺序是"先退款 → 再更新订单状态"。函数调用上没毛病。但生产环境里,支付回调可能在状态更新前到达,触发重复退款。
时序耦合这种隐含约束,AI 很难主动考虑——它只看到了你描述的需求规格,看不到系统上游的依赖链。
修复一段"几乎正确"代码的时间,往往比从零手写更长。 你不仅要找哪里错了,还要理解 AI 为什么这么写,然后在不破坏整体结构的前提下做局部修正。
安全:45% 的代码选了不安全的方案
Veracode 2025 年做了个实验。用 80 个已知安全漏洞的编程任务,让 100+ 个模型生成代码,再用静态分析扫描。
AI 在 45% 的测试用例中引入了 OWASP Top 10 级别漏洞。 当"安全实现"和"不安全实现"摆在面前,45% 的情况下它主动选了不安全的。
这个问题不分模型大小。大模型小模型安全表现差不多——说明是系统性问题,不是"模型还不够大"。
按语言拆:Java 漏洞率超过 70%,Python 38-45%,C# 和 JavaScript 紧随其后。防跨站脚本(CWE-80)失败率 86%,防日志注入(CWE-117)失败率 88%。
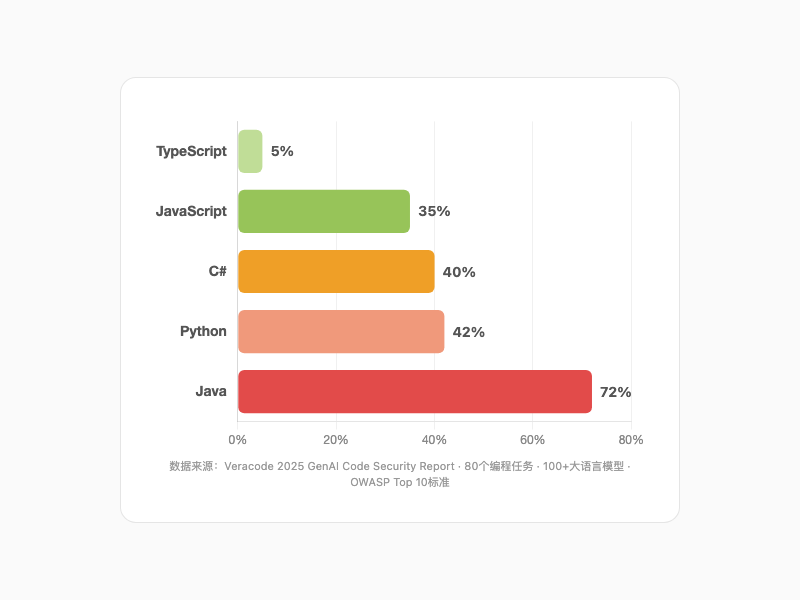
AI代码安全漏洞率
另一项基于 7703 个 GitHub 公开文件的分析给了相对温和的数字:87.9% 的 AI 生成文件没发现 CWE 漏洞。但 12.1% 有——Python 漏洞率 16-18%,明显高于 JavaScript(8-9%)和 TypeScript(2.5-7%)。
关键的细节:漏洞离 AI 归因注释的中位距离是 43 行。很多漏洞不是"AI 写的那一行",而是它生成的那一整段逻辑有安全缺陷。
AI 写的代码能跑。但你不知道它什么时候会炸。
Opsera 2026 还量化了一个附加伤害:代码重复率从 10.5% 涨到 13.5%。AI 不只引入漏洞,还顺手帮它们复制粘贴。
架构决策:大多数开发者不交钥匙
76% 的开发者不把部署决策交给 AI。69% 不用于项目规划。仅 29% 觉得 AI 能处理复杂问题——比 2024 年的 35% 还降了。
技术选型、模块拆分、接口设计——这些决策依赖的不是代码经验。是对业务走向的判断、团队能力的预估、运维成本的权衡。
AI 可以帮你列出 React 和 Vue 的优劣表。但它不知道你们团队有没有人愿意学 Vue,不知道下个季度业务方向会不会转,不知道运维对哪个中间件最熟。
这些信息,不在它的训练数据里。
最需要帮助的人,最容易被误导
这是最让人不安的一点。
初级开发者对 AI 代码"过度信任"——自信地用着那些看起来没问题、实际上有重大错误的代码。资深开发者的策略完全相反:审查 AI 输出,把它当起点而不是终点。
CACM 的研究证实了这种分化。初级开发者从 AI 受益的点是"写出更好的代码"(熟练度越低,受益反而越大)。资深开发者的受益点是"保持工作流"、"专注更有价值的工作"、"在不熟悉的语言里更快上手"。
AI 在最需要正确性的场景里——辅导新人——恰恰是最不可靠的。
为什么感觉快了,实测却慢了
回到开头那个实验。为什么实测慢 19%,开发者却觉得自己快了 20%?
答案在认知心理学里。
效率有两种量法。一种是产出效率:单位时间写了多少行代码。另一种是认知效率:完成一件事烧了多少心智能量。
AI 提升的主要是后者。
写样板代码不用动脑。修 bug 不用反复翻文档。接手新项目的理解成本被大幅削减。省掉的不是墙上时钟,是注意力和思考带宽。
Stack Overflow 的数据从侧面印证:54% 的开发者用六个以上工具完成日常工作。上下文切换本身,就是一种隐性的生产力税。
AI 帮你省掉的,是这个税。
关键的转折来了:注意力省下来之后,你把这些认知资源投到了更有价值的地方——更复杂的架构设计、更深的业务理解、更系统的错误处理。
这些投入的产出,不在"今天多写了多少行代码"里。在"下个月线上事故少了几个"里。
自觉效率提升了,客观测量却显示变慢——因为你在用省下来的脑子,想更难的问题。
还有一个有趣的数据支撑这个逻辑:每天用 AI 的开发者,好感度 88%。每周用的只有 64%。
高频使用者已经内化了 AI 的工作流。知道什么时候依赖它,什么时候警惕它。
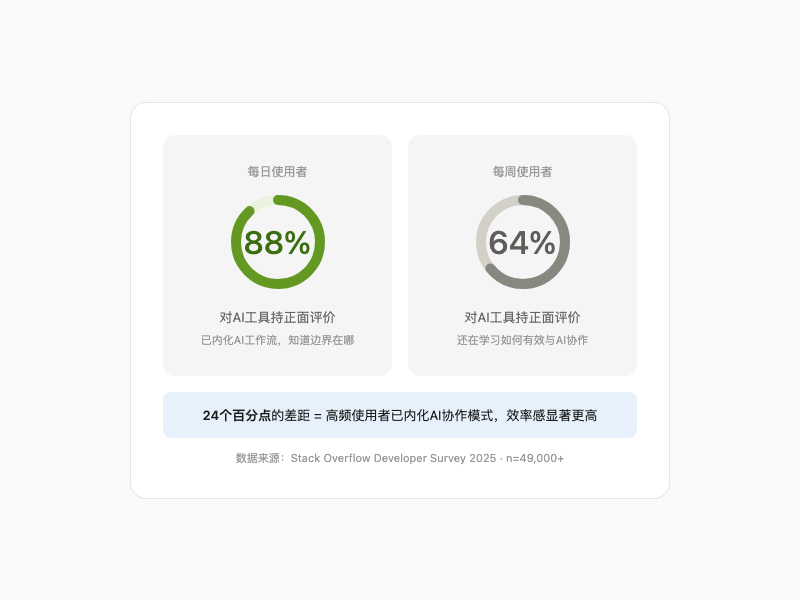
AI使用频率与效率好感度
好感度和使用频率之间,存在一个正反馈循环。
五条能用上的东西
基于上面的数据和踩过的坑,说几条不虚的。
一、AI 是手,不是脑
这是最高优先级。AI 执行,你决策。
具体操作很简单,但大部分人没做:写代码前,先给自己写一份需求说明。不是给 AI 写 prompt——是给自己写。
这个过程本身就是一次深度思考。把模糊想法,掰成清晰规格。
代码出来后,三遍审查:
- 第一遍,整体逻辑对不对
- 第二遍,边界条件和异常处理补了吗
- 第三遍,性能和安全性过关吗
Copilot 的建议接受率是 27%。换句话说,73% 的建议被开发者拒绝了。拒绝 AI,本身就是一种核心能力。
关键模块不让 AI 写。交易核心、权限校验、数据一致性、密钥管理——一行一行自己来。AI 可以帮你写这些模块的测试,但不能写实现。
Veracode 的数据已经够清楚了:45% 的情况下,AI 选了不安全的方案。
二、用 AI 探索,不用 AI 交付
AI 最大的价值,不是让你更快交付。是让你以极低成本验证更多方案。
过去试一条技术路线:搭环境、写 demo、踩配置坑、跑 benchmark——折腾半天发现走不通。沉没成本高到让人不想再试第二次。
现在 30 分钟内跑完:AI 在现有项目里直接出方案雏形,看效果。行就深化,不行就放弃。
一个项目只能手写一个方案的时候,你交付的往往是第一个想到的。两小时跑完五个方案对比——你交付的,自然是五选一的最优解。
三、别浅尝辄止
Stack Overflow 数据已经够直白了:每天用的好感度 88%,每周用的 64%。Opsera 2026 补了一刀:高频团队 AI 工具 ROI 比低频高 2-3 倍。
METR 实验里的开发者用 Cursor 只有几十个小时。研究团队自己说,不排除超过 50 小时后还有学习效应。有研究表明需要数百小时才能释放这些工具的完整效能。
用两天说"不好用"的,不是在评判工具——是在评判自己的 prompt 能力。
工具的上限,取决于你对它的理解深度。
四、工具选型速查(截至 2026 年 6 月)
不展开了,直接给结论:
- 日常补全:Cursor 或 Windsurf。前者 Tab 补全区段最快,后者跨文件上下文更好
- 大规模重构:Claude Code Agent 模式。100 万 token 窗口,跨文件改动一气呵成。预算有限选 Gemini CLI,免费额度管够
- 调试:报错堆栈 + 相关代码一起丢给 Claude 或 GPT,让它做模式匹配而不是代码生成
- 代码审查:AI 做第一轮,拦截低级错误;人类做第二轮,审业务逻辑
- 学新技术:用对话式 AI 交互学习。别被动翻文档
五、建立自己的"写 → 审 → 补"节奏
别指望 AI 一把梭哈出可用代码。接受一个现实:AI 生成的代码永远要改。
第一步:写清楚需求。输入、输出、边界条件、异常场景。
第二步:AI 出初版,快速审核心逻辑。
第三步:人工补全边界条件、性能优化、安全加固。
这个流程的底层逻辑很简单:AI 解决量——代码从 0 到 60 分。你解决质——从 60 到 90 分。
大多数挫败感,来自你期望 AI 直接写到 90 分,然后花大量时间修那些隐藏的 60 分瑕疵。
工具的尽头
上面说的,都基于当前能力。但模型本身进化得更快。
SWE-bench Pro 从 2024 年初约 30%,到 2026 年 6 月突破 80%。开源和闭源的差距缩到了 4 个百分点,DeepSeek 的价格是 Claude 的 1/5。
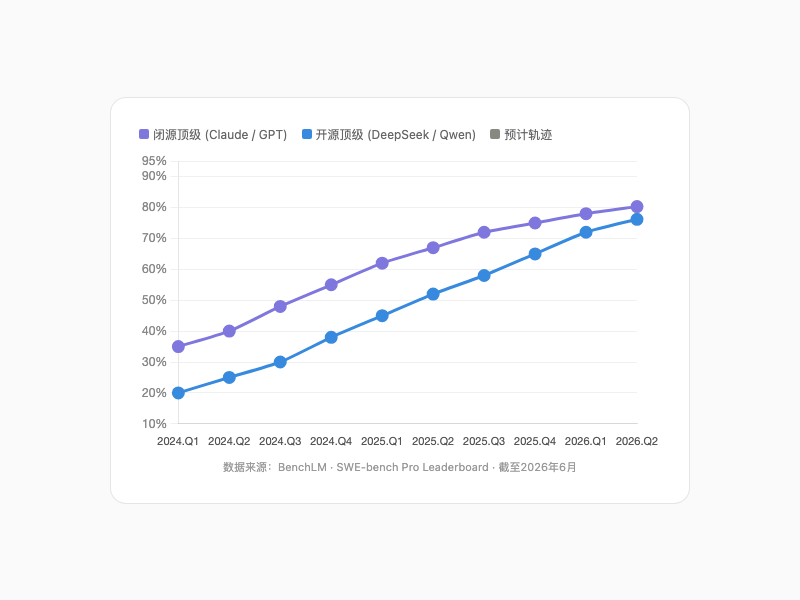
SWE-bench能力轨迹
但模型进化的真正方向,不是"更强的代码生成"——是"更适配真实工作流"。
上下文窗口从百万到千万。Agent 从一步生成到多步验证。视觉理解从手动截图到实时浏览器操控。领域专家化从"什么都能写"到"写对你们团队的代码"。
下一个里程碑不是更高的榜单分数。是改完 20 个文件、跑完 50 次测试、解决 3 个冲突之后,能不能产出一笔靠谱的 PR。
最后
这篇文章的核心逻辑其实一句话就能说清:
AI 对效率的提升是真实的——但它不体现在"代码写得更快",而体现在把大量低认知价值的劳动从你的工作流里剥走,让你可以想更难的问题。
那些"效率提升 300%"的叙事,忽略了一个变量:效率提升多少,不取决于 AI 多强,取决于你会不会用。
接下来的几年,AI 会用和不会用的程序员之间,会被拉出一个显著差距。但这个差距不在谁能更快写 CRUD——在谁的认知资源被解放得更多,谁就能在更高维度的决策里胜出。
三句话收尾:
- 现在就上手。 别等"完美版本"。等来的,只会是被越甩越远。
- 建立你的边界。 哪些交 AI,哪些自己写。边界可以调,但得有一个。
- 效率的本质不是你写了多少行,是你解决了多难的问题。
用了 AI 反而慢了?别慌。
你可能不是在变慢。你是在用省下来的脑子,做更难的事了。
而难的事——才是程序员真正不可替代的东西。
你日常用 AI 写代码最多的场景是什么?有没有那种"看着挺对、跑起来炸了"的经历?评论区聊聊。
参考来源:
- Opsera — "2026 AI Coding Impact Benchmark Report", Jan 2026 (n=250,000+ developers)
- Stack Overflow Developer Survey 2025 — n=49,000+ developers, 177 countries
- METR — "Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity", July 2025 (RCT, n=16 devs, 246 tasks)
- Veracode — "2025 GenAI Code Security Report" (80 tasks, 100+ LLMs tested)
- "Security Vulnerabilities in AI-Generated Code: A Large-Scale Analysis", arXiv 2510.26103
- CACM — "Measuring GitHub Copilot's Impact on Productivity", 2024
- BenchLM — AI Coding Benchmarks Leaderboard, June 2026
- Index.dev — "Top 100 Developer Productivity Statistics with AI Tools", 2025
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号