用 Python + Streamlit 快速搭建小工具

用 Python + Streamlit 快速搭建小工具

找Bug
发布于 2026-06-24 13:02:21
发布于 2026-06-24 13:02:21
大家好呀,今天给大家说个python工具,Streamlit
不知道大家有没有过这样的想法:
- 想做个网页统计工具;
- 想把 Excel 分析结果展示出来;
- 想做个日志分析平台;
- 想做个个人记账系统;
- 想把自己的 Python 脚本变成一个能点按钮使用的小网站。
结果上网一查:
HTML、CSS、JavaScript、Vue、React、Nginx……
还没开始做,已经被一堆陌生名词劝退了。
很多人以为做网页必须会前端,必须懂后端,必须会部署服务器。
其实并不一定。
如果你会一点 Python,哪怕只是会写几个脚本,也可以在十几分钟内做出一个带按钮、输入框、图表和文件上传功能的网页应用。
这就是 Streamlit。
Streamlit 是一个基于 Python 的 Web 应用开发框架,它最大的特点就是:
用写 Python 脚本的方式开发网页。
你不需要学习复杂的前端技术,也不需要研究 HTML、CSS 和 JavaScript。
传统开发一个数据分析平台,通常需要:
- 前端(HTML、CSS、JavaScript)
- 后端(Java、Python、Node.js)
- 数据库
- 接口开发
而使用 Streamlit,只需要编写 Python 脚本即可完成页面开发,大幅降低开发成本和学习门槛。
安装命令:
pip install streamlit那么我这边举两个小例子让大家感受一下,
第一个是接口日志分析,文件是log格式。说一下自己的需求,有这样一个文件,我想分析里面的内容,包括url,耗时等内容,让小工具帮我分析,文件是这样的
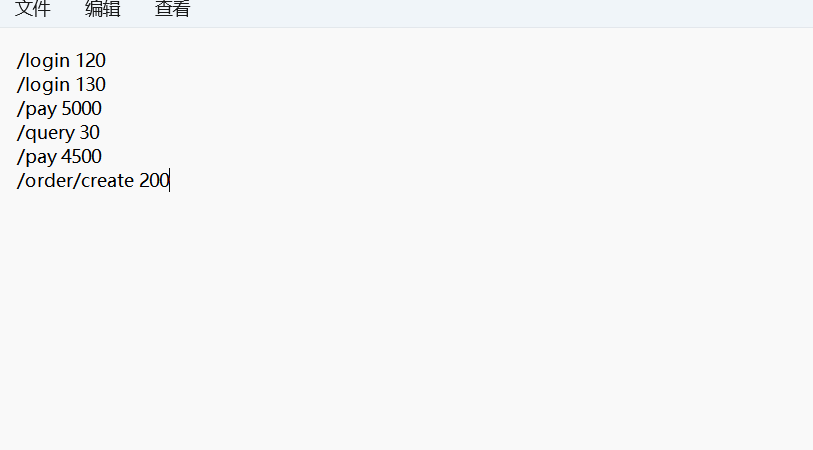
/login 120
/login 130
/pay 5000
/query 30
/pay 4500
/order/create 200有了需求,那就让stremlit帮我们分析吧
这个是有图表的,所以要安装pandas
pip install pandas python文件名为app.py,代码是这样的
import streamlit as st
import pandas as pd
import numpy as np
st.title("接口日志分析平台")
# 上传日志
uploaded_file = st.file_uploader(
"上传日志文件",
type=["txt", "log"]
)
if uploaded_file is not None:
# =========================
# 读取日志
# =========================
lines = uploaded_file.read() \
.decode("utf-8") \
.splitlines()
data = []
# =========================
# 解析日志
# =========================
for line in lines:
arr = line.split()
# 防止脏数据
if len(arr) != 2:
continue
url = arr[0]
cost = float(arr[1])
data.append({
"url": url,
"cost": cost
})
df = pd.DataFrame(data)
# =========================
# 全局统计
# =========================
total_count = len(df)
url_count = df["url"].nunique()
avg_cost = round(
df["cost"].mean(),
2
)
slow_count = len(
df[df["cost"] > 1000]
)
st.subheader("全局统计")
col1, col2 = st.columns(2)
col1.metric(
"总请求数",
total_count
)
col1.metric(
"接口数量",
url_count
)
col2.metric(
"平均耗时(ms)",
avg_cost
)
col2.metric(
"慢请求数量",
slow_count
)
# =========================
# URL聚合分析
# =========================
result_df = df.groupby("url").agg(
请求数=("cost", "count"),
平均耗时=("cost", "mean"),
最大耗时=("cost", "max"),
最小耗时=("cost", "min"),
P95=("cost",
lambda x:
np.percentile(x, 95)
),
P99=("cost",
lambda x:
np.percentile(x, 99)
)
).reset_index()
# 保留2位小数
result_df = result_df.round(2)
# =========================
# TOP10慢接口
# =========================
st.subheader("TOP10慢接口")
top10_df = result_df.sort_values(
by="平均耗时",
ascending=False
).head(10)
st.dataframe(top10_df)
# 柱状图
st.bar_chart(
top10_df.set_index("url")[
"平均耗时"
]
)
# =========================
# URL搜索
# =========================
keyword = st.text_input(
"搜索URL"
)
if keyword:
result_df = result_df[
result_df["url"]
.str.contains(
keyword,
na=False
)
]
# =========================
# 全部分析结果
# =========================
st.subheader("URL详细分析")
st.dataframe(result_df)
# =========================
# 慢请求分析
# =========================
st.subheader("慢请求")
slow_df = df[
df["cost"] > 1000
]
st.dataframe(slow_df)
# =========================
# AI分析建议
# =========================
st.subheader("智能分析")
if slow_count > 100:
st.error(
"系统慢请求较多,"
"建议检查数据库或缓存。"
)
elif avg_cost > 500:
st.warning(
"系统平均耗时偏高。"
)
else:
st.success(
"系统运行稳定。"
)
# =========================
# 导出分析结果
# =========================
csv = result_df.to_csv(
index=False
)
st.download_button(
"下载分析结果",
csv,
"result.csv",
"text/csv"
)启动项目,在下面终端命令启动:
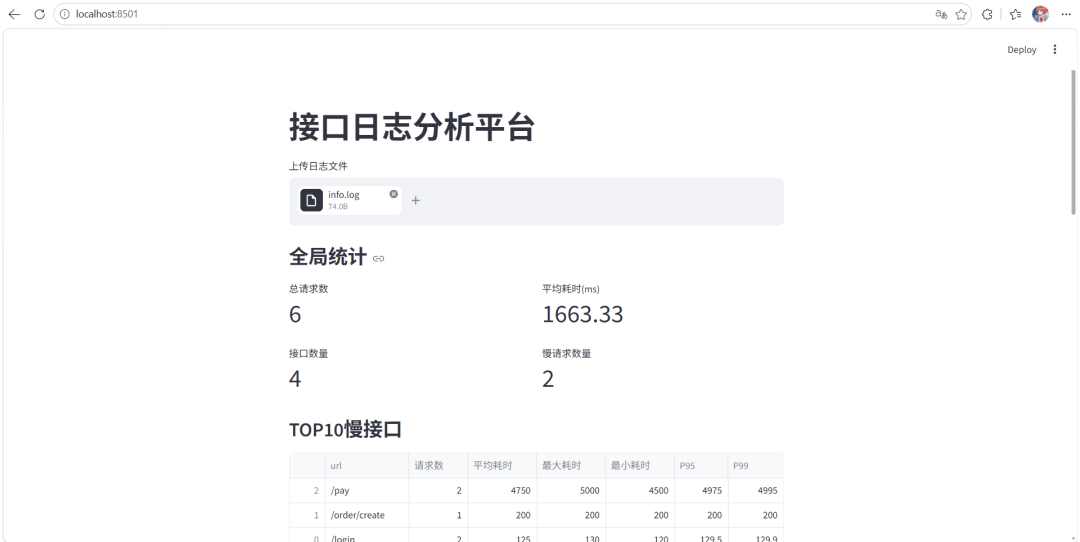
streamlit run app.py执行后会自动打开浏览器访问页面。
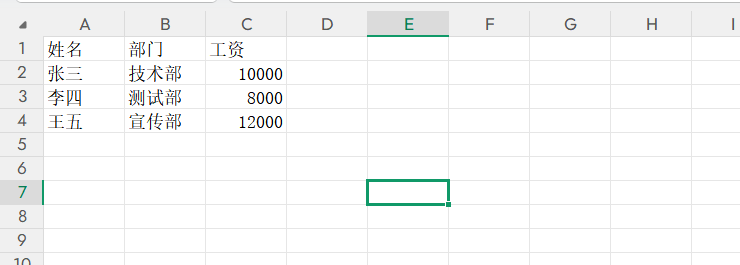
第二个例子是分析excel内容。需求是将工资表分析一下,包括平均工资等内容。
excel内容是这样的
代码是下面这样的,文件是app1.py
import streamlit as st
import pandas as pd
st.set_page_config(page_title="工资分析平台")
st.title("员工工资分析平台")
uploaded_file = st.file_uploader(
"请选择Excel文件",
type=["xlsx", "xls"]
)
if uploaded_file:
df = pd.read_excel(uploaded_file)
st.subheader("原始数据")
st.dataframe(df)
# 基础统计
total_people = len(df)
avg_salary = df["工资"].mean()
max_salary = df["工资"].max()
min_salary = df["工资"].min()
col1, col2, col3, col4 = st.columns(4)
col1.metric("员工人数", total_people)
col2.metric("平均工资", f"{avg_salary:.0f}")
col3.metric("最高工资", max_salary)
col4.metric("最低工资", min_salary)
# 部门统计
st.subheader("部门工资统计")
dept_df = df.groupby("部门")["工资"].agg(
人数="count",
平均工资="mean",
最高工资="max",
最低工资="min"
)
st.dataframe(dept_df)
st.subheader("部门平均工资")
st.bar_chart(dept_df["平均工资"])
st.subheader("部门人数")
st.bar_chart(dept_df["人数"])同样启动项目:
streamlit run app1.py效果如下
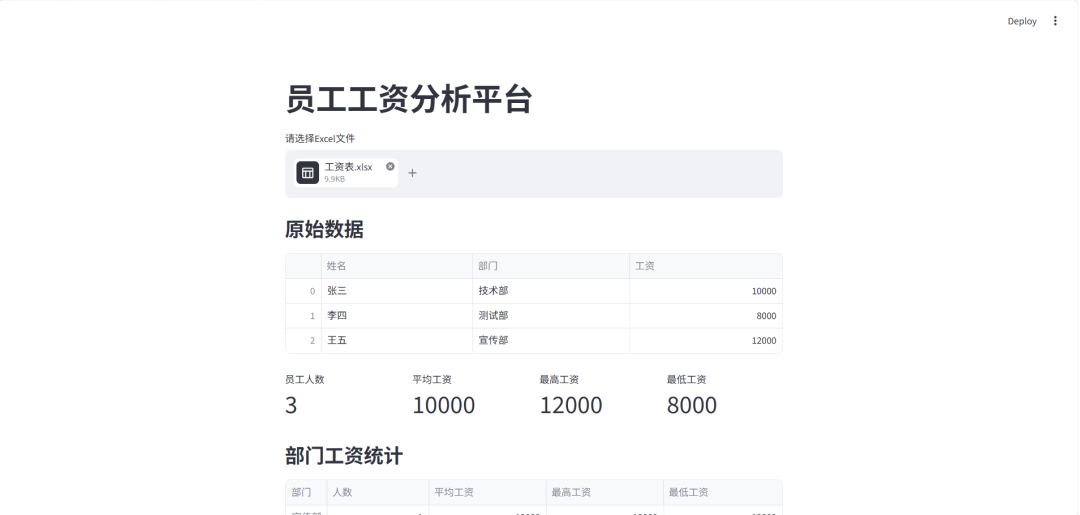
大家可以试试,还有更多使用的方法。现在ai工具也层出不穷,只要说下需求,不用自己去想,可以完全让ai帮我们生成代码。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号