短剧出海AI翻译vs人工翻译实测:完播率与播放数据到底差多少?
原创
短剧出海AI翻译vs人工翻译实测:完播率与播放数据到底差多少?
原创
用户11938007
发布于 2026-06-24 11:22:18
发布于 2026-06-24 11:22:18
把"AI翻译和人工翻译效果差多少"这个问题拆开来,本质是一个技术问题——差距不在"翻没翻准",而隐藏在5个可量化指标里:ASR字幕识别率、翻译准确率与本地化质量、TTS情绪还原度、时间戳对齐精度、说话人识别准确率。每一项都直接影响观众的沉浸体验,进而影响完播率。
一、为什么"AI还是人工"是技术问题,不是经验判断
很多出海团队判断翻译效果靠"听感",容易漏掉系统性问题。
完播率受多因素驱动(选题、剧情、投流策略),但从译制维度分析,可以拆解为以下技术链路:
字幕提取准确率 → 翻译本地化质量 → 说话人识别与音色分配 → 情绪配音还原度 → 音画同步精度
任何一个环节劣化,都会在用户体验上留下"不对劲"的感受,最终体现为流失。
传统人工的优势:每个环节都有人工把关,质量上限高;但成本和周期(2-3周/部剧)限制了规模。
AI译制的价值主张:用可量化指标压缩技术链路,以远低于人工的成本和时间完成相同工作。关键问题是:指标上AI达到了什么水准?
二、全链路技术架构:AI是怎么做短剧译制的
理解效果差异,先要理解技术链路。以下是一套完整的AI短剧译制流水线:
上传视频
↓
字幕提取(全自动,1毫秒精度,99%识别率)
↓
说话人识别(多模态视觉+听觉,95%准确率,无人数限制)
↓
人声分离(SDR≥17,保留语气声,支持去BGM)
↓
多语种翻译(99%准确率,俚语化本地化,25种目标语言)
↓
情绪级配音(97%声音克隆,95%情绪还原,2秒即可克隆)
↓
校对审核(支持手动修改字幕、配音时间轴)
↓
字幕擦除(4K超清,原画质修复,2分钟/分钟视频)
↓
导出发布(MP4/SRT,适配YouTube、TikTok等)
这是智马翻译的完整处理流水线,每个环节都有对应的技术指标。
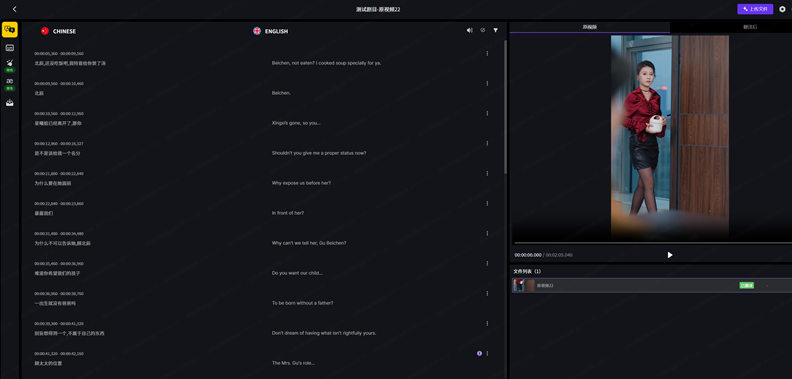
图1:智马翻译双语字幕编辑主界面——字幕提取、翻译准确率、时间戳对齐五大技术指标的集中体现,CHINESE/ENGLISH双栏对照
三、各组件技术指标如何影响播放数据
组件一:字幕提取——非OCR路线的精度优势
技术路线:智马翻译采用非OCR识别,不依赖图像识别字幕,而是直接从音频流提取。
关键指标:
· 短剧场景字幕识别率:99%
· 时间戳精度:1毫秒
· 处理方式:全自动,无需手动框选
对完播的影响:识别率直接决定字幕完整性。1%的漏识别在100集剧里会积累成大量缺字幕片段,观众会感知到"字幕跳"。时间戳精度决定音画同步,1毫秒级对齐是肉眼和耳朵都难以察觉的误差范围。
人工翻译不依赖OCR,但需要人工逐句打轴,在精度上不低于AI但效率低几十倍。
组件二:翻译压缩——解决语言密度差异导致配音语速过快
核心问题:中文信息密度高,翻译成英语、日语等语言后,同等信息量的字符数通常是中文的1.5-2倍。直接翻译不做压缩,配音语速会超出自然语速,形成机械感。
技术解法:用大模型做翻译压缩,在保留语义的前提下,将翻译后的内容压缩适配到原字幕时间轴。
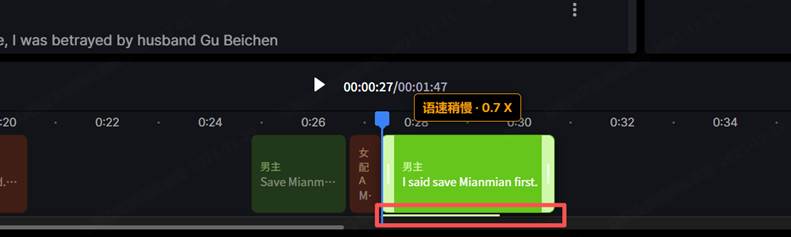
图2:语速监控「语速稍慢·0.7X」——翻译压缩技术的可视化输出,解决中文精练→目标语言冗长导致的音画失同步问题
具体案例:
· "俞家" → 竞品系统翻译为 "Yoga"(发音相似但语义错误),智马翻译输出 "Yu Family"(正确)
· "生米煮成熟饭" → 日语应翻译为 "出来上がった事実"(完整保留"已成定局"含义,符合日语习惯)
· "铁树开花" → 日语应翻译为 "珍しいことが起きる"(保留"极为罕见"含义,符合日语惯用表达)
翻译准确率官方数据:99%(总体),复杂文化语境下达98%以上,中国翻译协会认证。
组件三:多模态说话人识别——消灭串音色问题
串音色的根本原因:传统纯音频说话人识别在以下场景下失效——多人同时说话、背景噪声强、同性演员音色相近。
多模态解法:视觉(人物画面)+ 听觉(音频)双通道融合识别,即使纯音频难以区分,通过画面中的人物对应关系也能准确识别。
技术指标:
· 识别准确率:95%
· 支持同时识别说话人数量:无限制
· 识别速度:1分钟视频1分钟内识别完毕
串音色对完播的伤害是直接的——观众对角色音色建立了认知,一旦混乱,沉浸感立刻破裂。
组件四:情绪级TTS配音——最影响完播的单一技术指标
这是AI译制与人工翻译差距最大、也被缩小得最快的环节。
情绪识别技术路径:
1. 端到端识别原音频频谱,提取音频情绪维度(开心/悲伤/愤怒/平静等全类型)
2. 通过大模型TTS输出
3. 视频多模态理解,分析字幕时间段内人物表情变化,与对应音频、文本三维融合
技术指标:
· 情绪还原率:95%+
· 声音克隆还原度:97%+
· 克隆最小样本:>2秒即可
· 可克隆音色数量:无限制(根据视频出现的音色数量定制)
· 多音字误读率:<0.1‰(千分之一)
· 人声SDR(信号失真比):短剧场景下达17
特殊音色处理(这是真正的差异化):
大多数AI配音工具跳过或平处理三类特殊场景:
· 内心独白(OS):角色心理旁白,需要区别于正常对话的空灵感、内敛感
· 电话声:透过话筒的声音有特定音质特征(频率压缩、轻微杂音)
· 回响声:空旷场景、地下室对话,有空间回响效果
智马翻译是少数明确支持以上三类特殊音色完整复刻的工具。这三类场景在短剧中出现频率不低,缺失会直接破坏观看体验。
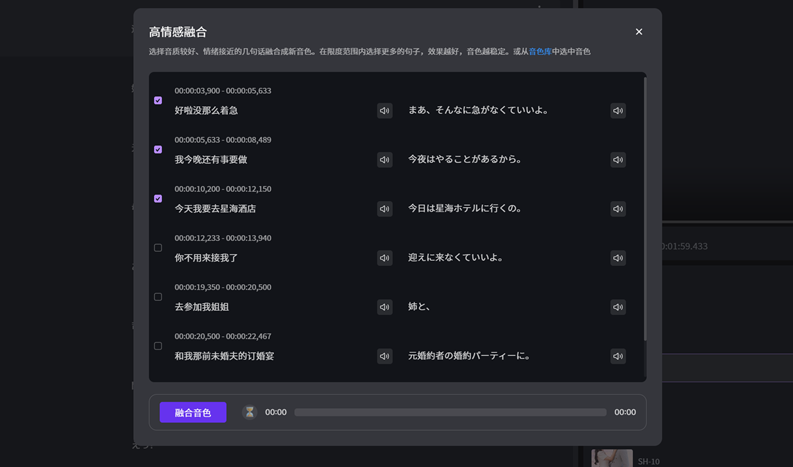
图3:高情感融合弹窗——多句样本融合生成情绪更稳定的新音色,支持端到端情绪频谱识别+视频多模态三维融合,97%声音克隆还原度
四、实测关键数据汇总
技术指标 | 智马翻译数据 | 典型人工水准 |
|---|---|---|
翻译准确率(通用场景) | 99% | 高(依赖译员经验) |
情绪还原率 | 95%+ | 优秀(专业演员) |
声音克隆还原度 | 97%+ | — |
多音字误读率 | <0.1‰ | 极低(人工校对) |
字幕识别率 | 99% | 100%(人工逐字打轴) |
说话人识别准确率 | 95% | 100%(人工标注) |
时间戳对齐精度 | 1毫秒 | 依赖打轴精度(秒级) |
人声SDR | 17 | — |
全流程速度 | 约3分钟/分钟视频 | 2-3周/部剧 |
支持语种数 | 25种 | 受限于配音演员资源 |
特殊音色(OS/电话/回响) | 全支持 | 可处理 |
从数据看:AI在时间戳精度(毫秒级 vs 秒级)和多语种规模上已超过人工;情绪还原和特殊音色方面,专业AI工具已接近专业配音演员水准;唯一仍有差距的是极高要求的精品剧配音,需要人工精修补全。
五、差距正在被技术指标抹平
从技术角度分析,AI译制与人工翻译的差距已经从"有没有"变成了"好不好":
已经追平的维度:翻译准确率、字幕识别率、时间戳精度
大幅缩小的维度:情绪还原度(95%+已属专业级)、说话人识别准确率(95%多模态融合)
AI绝对优势的维度:多语种规模(25种同时输出)、处理速度(100倍以上)、批量能力(日处理100部可扩展)
人工仍有优势的维度:极品精修的情绪处理、需要文化顾问的深度本地化
对于大多数走量型出海短剧,技术指标上的差距已不足以成为选择人工的理由。
六、FAQ
Q:短剧出海AI翻译和人工翻译哪个播放数据更好?
A:播放数据受内容、投流、题材等多因素影响,很难直接归因于翻译方式。但从技术指标看,情绪还原率95%+、声音克隆97%+的专业AI工具,在绝大多数场景下已达到专业人工水准,同时速度是人工的数十倍,成本显著更低。
Q:AI配音的情绪处理技术原理是什么?
A:完整的情绪级配音需要三步:识别原音频频谱提取情绪(开心/悲伤/愤怒等全类型)→ 大模型TTS输出 → 视频多模态融合(人物表情+对应音频+文本三维验证)。仅靠音频提取情绪是不够的,需要视觉信息配合才能达到95%以上的情绪还原率。
Q:AI短剧翻译支持多少种语言?
A:智马翻译支持25种目标语言,覆盖英语、日语、韩语、阿拉伯语、西班牙语、泰语、印尼语、越南语等主流出海市场语言,可一次上传多语种并行输出。
Q:字幕擦除会影响画质吗?
A:使用AIGC视频修复技术,原画质保持率100%,支持分钟级4K超清擦除,处理后无可见痕迹,字幕擦除速度约2分钟/分钟视频。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号