医疗AI智能体:合规可追溯:SKILL架构下的可解释性AI(XAI)医疗落地全解.145
原创
医疗AI智能体:合规可追溯:SKILL架构下的可解释性AI(XAI)医疗落地全解.145
原创
未闻花名
发布于 2026-06-22 08:27:11
发布于 2026-06-22 08:27:11
一、核心概念
1. 什么是可解释性AI
可解释性人工智能XAI,全称Explainable AI,核心是让AI模型的决策过程可理解、可追溯、可验证,而不是给出一个无法拆解的“黑盒结果”。在通用场景中,模型不可解释往往只影响效果优化;但在医疗场景中,不可解释直接关系到:
- 诊断安全:医生无法理解AI的诊断依据,难以判断其建议是否合理,可能因盲目采纳或错误拒绝而增加误诊、漏诊风险,直接威胁患者生命安全。
- 临床责任认定:当AI辅助诊断出错时,由于决策过程不透明,难以界定是医生判断失误、算法缺陷还是数据问题,导致责任归属陷入困境。
- 医疗合规审查:监管机构要求医疗决策过程可追溯、可审核。AI的“黑箱”特性使其难以满足合规要求,影响产品准入和临床应用推广。
- 医患信任:患者无法理解AI的诊断逻辑,只能被动接受,削弱了医患沟通基础,加剧对技术的不信任感。
- 监管准入:各国药监部门(如NMPA、FDA)正逐步将“可解释性”作为AI医疗产品审批的硬性门槛,缺乏透明逻辑的产品将难以通过认证。
传统深度学习模型,如CNN、Transformer、大模型基座本质是高维特征映射,输出结果依赖海量参数拟合,无法清晰说明“为什么得出这个结论”、“依据是什么”、“风险点在哪里”。

2. 医疗场景XAI强制性要求
医疗AI不同于推荐、图像识别等领域,它的决策直接影响生命健康,因此行业具备天然强监管属性:
2.1 临床决策必须有据可依 医生诊断不能只说“我觉得”,必须基于诊疗指南、检验阈值、文献证据、专家共识。
2.2 责任边界必须清晰 若 AI 给出错误建议,必须能定位问题来源:是数据问题、规则问题、模型幻觉,还是触发逻辑错误。
2.3 监管机构要求可审计 NMPA、FDA 等对医疗 AI 器械均要求:决策透明、可复现、可追溯。
2.4 医护人员信任门槛极高 没有医生会信任一个“不知道为什么这么判断”的系统来辅助诊疗。
3. 大模型在医疗中的黑盒与幻觉
大模型具备强大的医学理解、对话、总结能力,但在医疗落地中存在致命缺陷:
- 无法精准锚定医学指南条文
- 无法稳定输出决策阈值与证据来源
- 容易产生医学幻觉,编造不存在的诊疗方案
- 决策链路不可追溯,不满足监管
- 置信度不可量化,无法区分 “高风险必须复核” 与 “低风险可参考”
这导致纯大模型很难直接进入核心诊疗辅助环节,只能用于科普、分诊、病历整理等弱决策场景。
总得来说:医疗AI想要真正进入核心临床辅助、风险决策、合规准入,必须解决可解释、可追溯、可审计问题,而单纯依靠大模型原生能力无法实现,需要一套结构化架构来约束、拆解、记录决策链路,这就是SKILL架构在医疗行业的价值起点。
二、SKILL 架构基础
1. 了解SKILL架构
SKILL是一种面向任务拆解、模块化执行、可追踪决策的智能体架构。它将复杂医疗问题,拆分为一个个独立、原子化、可解释的技能单元,每个SKILL具备:
- 明确触发条件:通过关键词、意图或特定场景精准激活,确保技能在正确时机介入,避免误触发或资源浪费。
- 固定输入输出:标准化的数据接口定义了严格的入参结构与返回格式,确保不同技能间能无缝衔接与流转。
- 内置医学依据:深度整合临床指南与权威文献,确保每一步推理都有据可查,实现从“黑盒”到“白盒”的转变。
- 可量化置信度:输出结果附带概率评分,直观展示系统对结论的把握程度,辅助医生判断是否采纳或需人工复核。
- 可审计执行日志:全链路记录调用参数、推理步骤及耗时,满足合规要求,为故障排查与持续优化提供数据支撑。
不同于端到端大模型直接输出答案,SKILL 架构让 AI 像标准化临床路径一样工作:一步一步执行、一步一步记录、一步一步解释。
2. SKILL架构的设计原则
2.1 原子化拆解 复杂问诊 → 拆分为症状识别、检验判读、指南匹配、风险分层等独立 SKILL。
2.2 规则 + 模型混合 硬规则(医学阈值、指南条款)保证安全,大模型负责理解与语义匹配。
2.3 全链路可追溯 从用户问题 → 触发 SKILL → 匹配依据 → 得出结论,全程留痕。
2.4 置信度显性化 每个 SKILL 输出置信度,高风险自动提醒人工复核。
2.5 合规前置 内置医学证据库,决策必须绑定真实指南、文献,并显示阈值,不允许凭空生成。
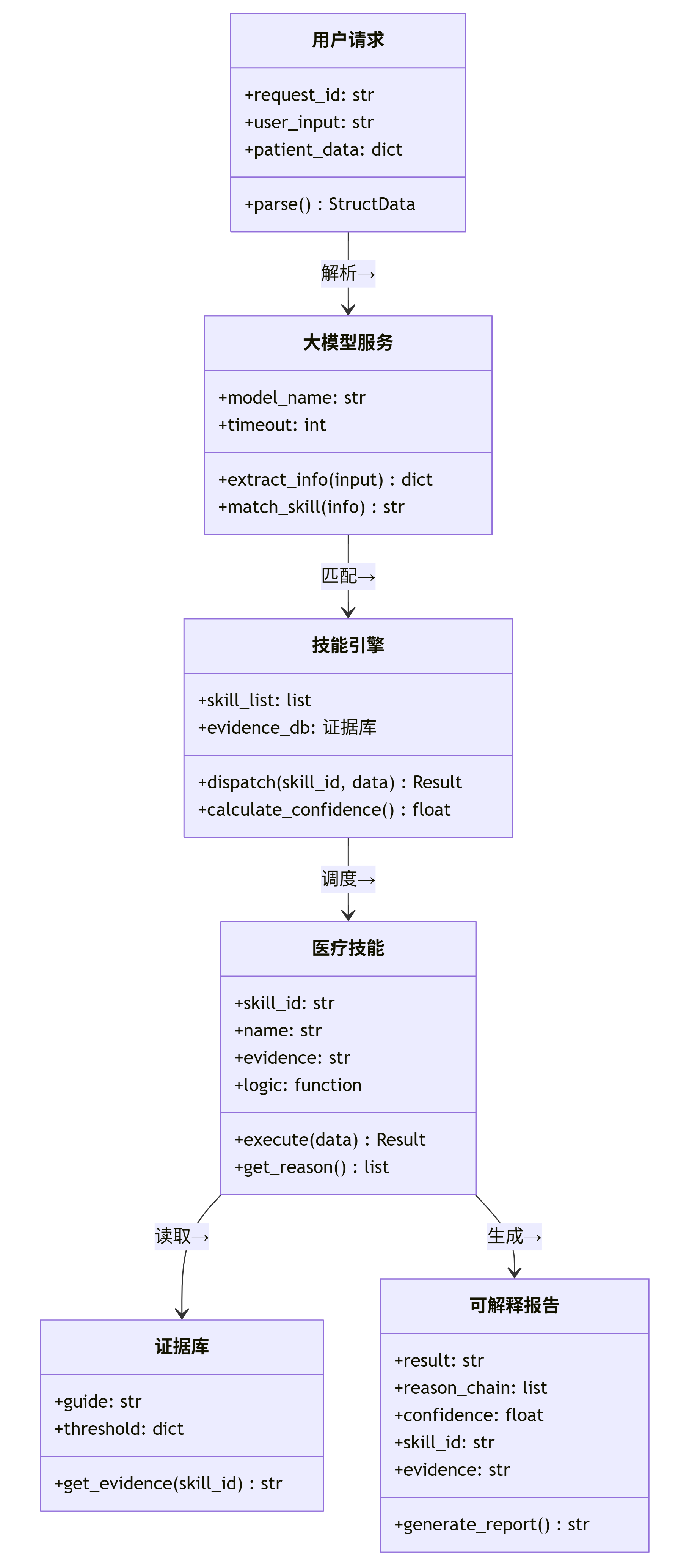
3. 医疗SKILL核心对象模型
医疗SKILL系统的核心结构:用户请求经大模型服务解析并匹配技能,技能引擎调度具体医疗技能,技能内部读取证据库(指南/阈值)后生成可解释报告(含结论、依据、置信度)。整体实现语义理解、技能执行与审计追溯的解耦设计。
3.1 整体分层
系统按职责划分为三层:
- 入口层:用户请求 → 接收原始输入并结构化
- 处理层:大模型服务 + 技能引擎 → 解析意图、匹配并调度技能
- 执行层:医疗技能 + 证据库 → 执行具体医学逻辑并引用权威依据
- 输出层:可解释报告 → 生成含溯源信息的结果
3.2 各模块职责
模块 | 核心属性 | 核心方法 | 作用 |
|---|---|---|---|
用户请求 | request_id, user_input, patient_data | parse() | 将用户原始输入转为结构化数据 |
大模型服务 | model_name, timeout | extract_info(), match_skill() | 提取症状 / 检验 / 病史,匹配候选技能 |
技能引擎 | skill_list, evidence_db | dispatch(), calculate_confidence() | 根据匹配结果调度具体技能,计算置信度 |
医疗技能 | skill_id, evidence, logic | execute(), get_reason() | 执行特定医学逻辑,返回结论与依据 |
证据库 | guide, threshold | get_evidence() | 存储指南、阈值、文献等权威依据 |
可解释报告 | result, reason_chain, confidence, skill_id, evidence | generate_report() | 聚合结论、依据、技能 ID、置信度,生成可审计报告 |
3.3 数据流与依赖关系
依赖方向与数据流方向一致,实现低耦合、高内聚。
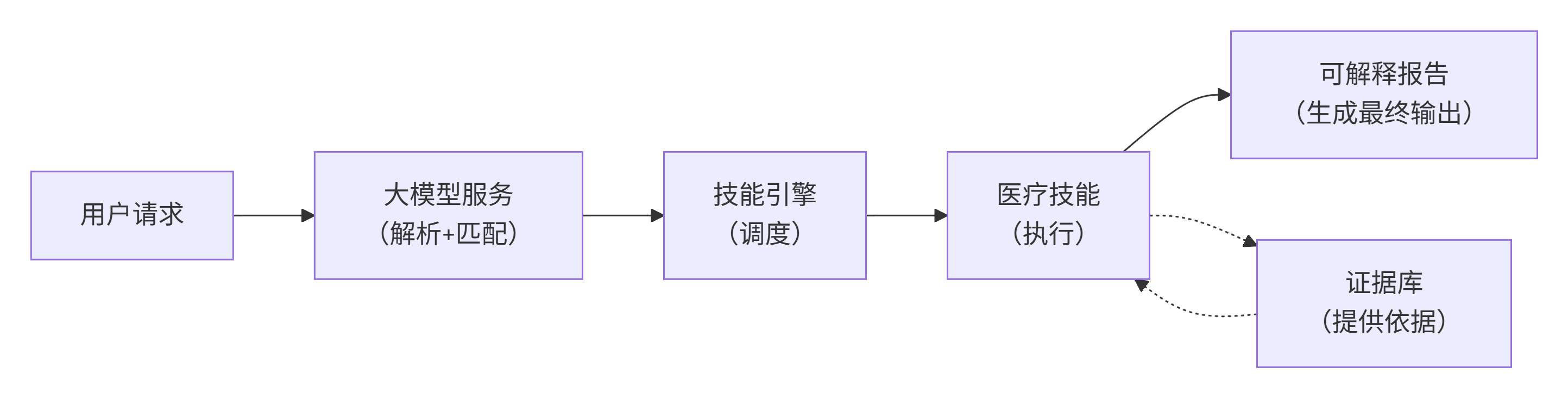
3.4 设计特点
- 解耦:技能逻辑与调度、证据存储分离,便于独立维护。
- 可解释:报告包含 reason_chain 和 evidence,支持审计追溯。
- 可扩展:新增医疗技能只需实现 execute() 接口,并注册到技能引擎。
4. SKILL+XAI整体架构图
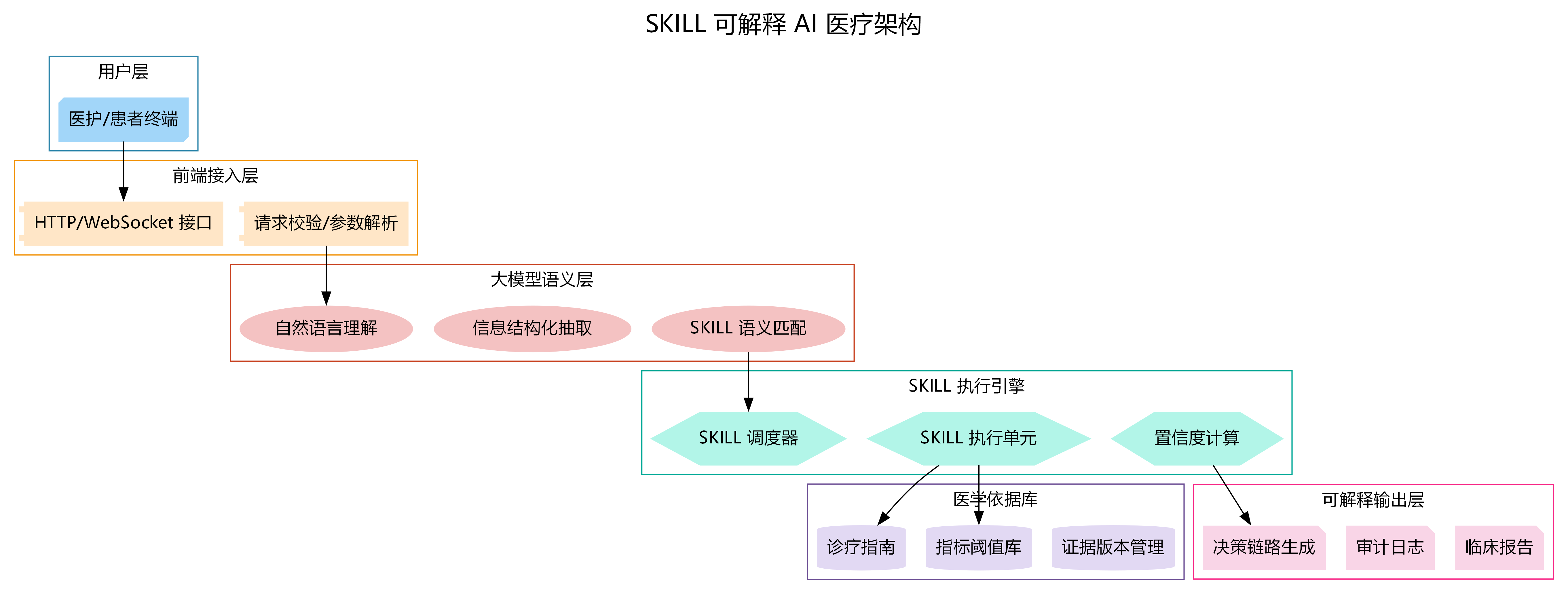
4.1 架构分层与职责
- 用户层:医护/患者终端发起请求。
- 接入层:提供HTTP/WebSocket接口,完成请求校验与参数解析。
- 大模型语义层:进行自然语言理解、信息结构化抽取、SKILL语义匹配,将用户输入转为结构化任务。
- SKILL执行引擎:调度具体SKILL单元执行,并计算置信度。
- 医学依据库:存储诊疗指南、指标阈值、证据版本,为SKILL提供权威支撑。
- 可解释输出层:生成决策链路、审计日志、临床报告,实现结果可追溯、可解释。
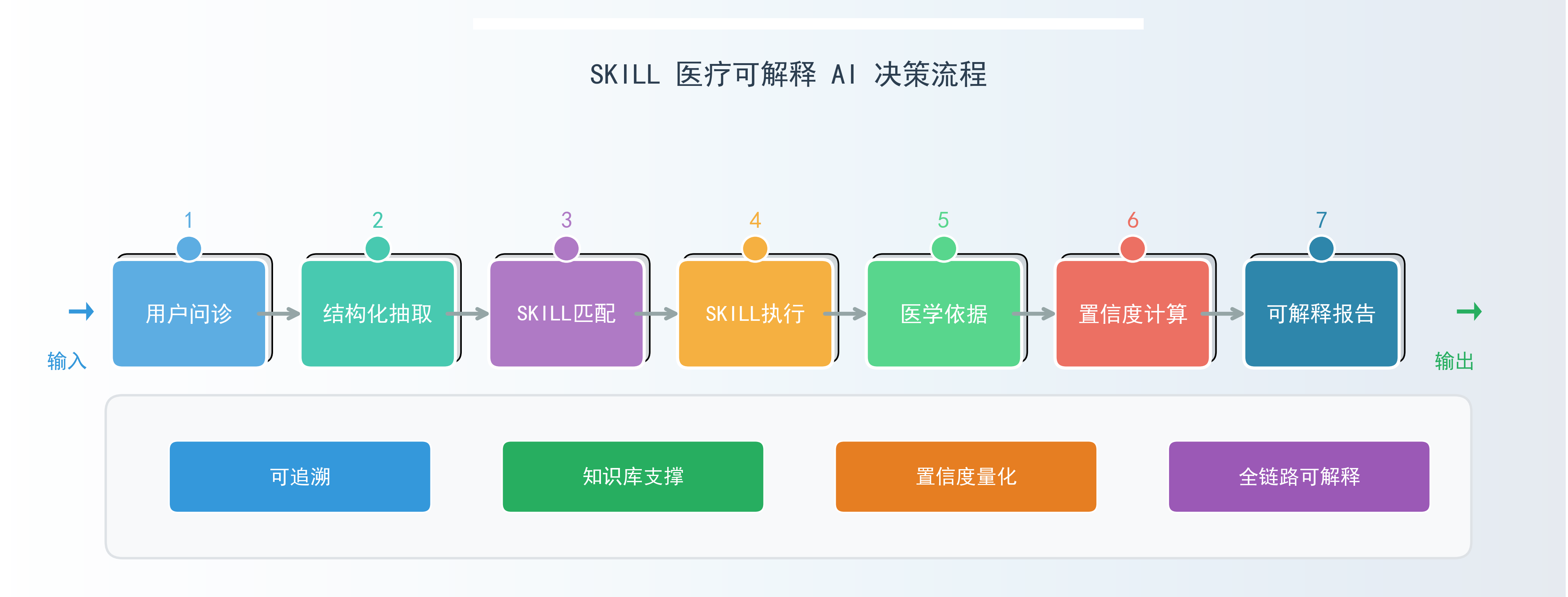
4.2 核心数据流

4.3 设计重点
- 解耦:语义理解、技能执行、证据存储、输出解释各自独立,便于维护扩展。
- 可解释性:输出包含决策链路与依据,满足医疗场景审计要求。
- 权威性:SKILL执行依赖指南与阈值库,避免模型幻觉。
5. 与传统大模型智能体的区别
模式 | 决策方式 | 可解释性 | 医疗合规 | 风险可控性 |
|---|---|---|---|---|
原生大模型 | 端到端生成 | 极差 | 不满足 | 低 |
ReAct 智能体 | 大模型自主规划 | 弱 | 难以监管 | 中 |
SKILL 医疗架构 | 模块化 + 固定医学依据 | 极强 | 满足审计 | 高 |
SKILL不是让大模型自由思考,而是让大模型在严格医学框架内执行标准化技能。
6. SKILL架构对医疗XAI的价值
SKILL是医疗XAI落地的结构性载体,SKILL将抽象的XAI理念具象化,成为可执行、可交付的标准化医疗能力单元:
- 黑盒变白盒:将复杂的端到端推理拆解为透明、可视化的原子步骤,消除算法的不确定性。
- 绑定医学依据:每个逻辑节点都强制关联指南或文献,确保推理链条符合循证医学规范。
- 回溯触发逻辑:完整记录决策路径与参数,支持对任意历史结论进行全链路复盘与验证。
- 直接审计判断:提供无门槛的审查视图,让医护与监管机构能像查病历一样核验AI逻辑。
这让医疗AI从“不可解释的大模型”升级为“合规可追溯的临床辅助系统”。
三、SKILL + XAI完整执行流程
1. 标准执行链路
整个流程从用户医疗问题出发,经大模型语义理解抽取关键信息,匹配SKILL库并独立执行,调用医学依据后输出带置信度的结论与来源,最终生成可审计的可解释报告。
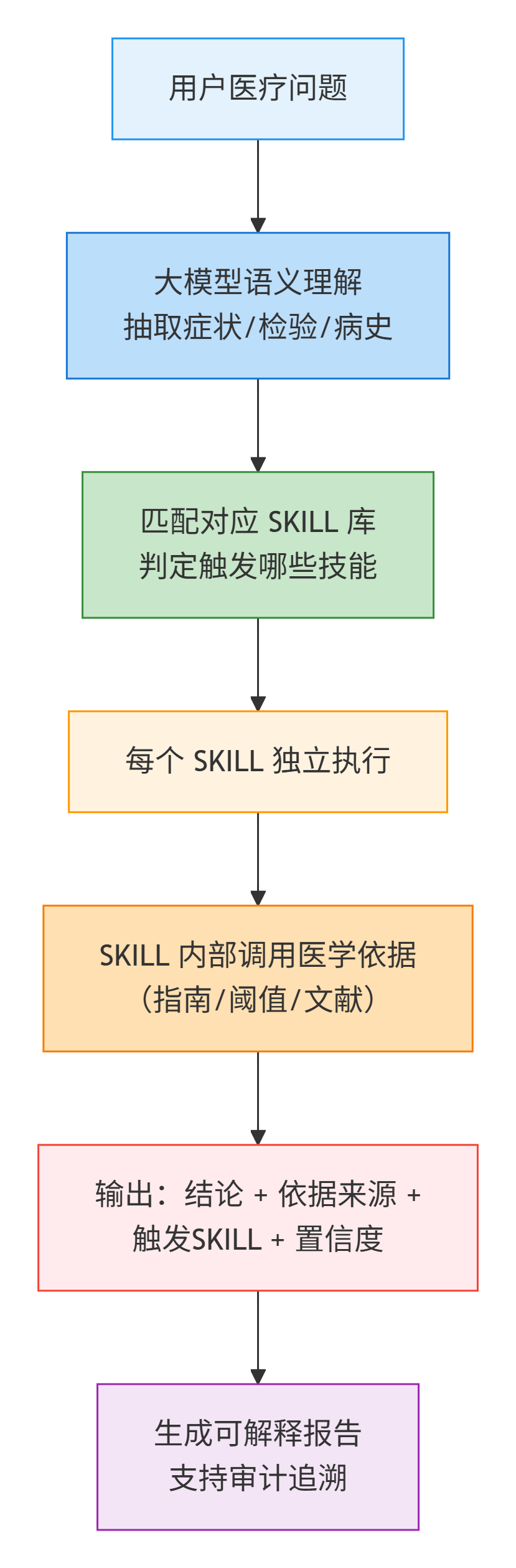
2. 流程执行环节说明
1. 用户问题输入
例如:“患者 62 岁,空腹血糖 8.5 mmol/L,糖化血红蛋白 7.6%,无既往糖尿病史,请问风险等级?”
2. 大模型语义结构化抽取
大模型不直接诊断,只做信息抽取:
- 年龄:62 岁
- 空腹血糖:8.5 mmol/L
- 糖化血红蛋白:7.6%
- 既往史:无糖尿病
3. SKILL 匹配与触发
系统根据结构化信息,自动匹配预定义医疗 SKILL:
- SKILL_DIABETES_RISK 糖尿病风险评估
- SKILL_GLYCEMIC_INTERPRET 血糖指标解读
4. SKILL 内部执行(核心可解释环节)
每个 SKILL 内置固定医学逻辑:
- 空腹血糖 ≥ 7.0 mmol/L → 达到糖尿病诊断阈值
- 糖化血红蛋白 ≥ 6.5% → 达到诊断标准
- 依据:《中国 2 型糖尿病防治指南(2022 年版)》
5. 置信度计算
- 两项指标均达标 + 年龄高危 → 置信度 0.94
- 无既往病史 → 轻微下调 → 最终置信度 0.91
6. 生成可解释结果
结果不再是一句话,而是完整审计链路:
【结论】高度提示糖尿病前期或确诊 2 型糖尿病,建议进一步复查。 【触发SKILL】SKILL_DIABETES_RISK v1.2 【依据来源】中国2型糖尿病防治指南(2022) 【判断逻辑】 1. 空腹血糖 8.5 ≥ 7.0 mmol/L,达到诊断阈值 2. 糖化血红蛋白 7.6 ≥ 6.5%,达到诊断阈值 3. 年龄≥60岁,属于高危人群 【置信度】0.91 【建议】内分泌科就诊,完善OGTT试验
3. 审计与监管核查
整套日志可保存、可检索、可复现,满足:
- 医院质控审查
- 医疗器械监管申报
- 医疗纠纷溯源
- 算法迭代优化
四、XAI可解释性实现原理
1. SKILL 模块化结构定义
一个标准医疗 SKILL 包含 6 个核心部分:
- skill_id:唯一标识,便于追踪
- trigger_condition:触发条件,可由大模型匹配
- medical_evidence:绑定指南、阈值、文献
- inference_logic:推理逻辑,使用规则或轻量模型
- confidence_calculation:置信度计算规则
- explanation_template:解释生成模板
2. XAI核心依据
SKILL 内部不使用大模型自由生成依据,而是采用证据库检索 + 强制绑定:
- 内置结构化指南库(JSON / 知识库)
- 每个判断必须映射到某一条款
- 禁止无依据输出
3. 置信度计算规则
医疗场景置信度不能靠模型隐式输出,必须可解释计算,医生和患者需要知道这个数字是怎么算出来的:
置信度 = 基础分 + 指标匹配分 + 人群风险分 - 干扰因素分
公式的核心逻辑是“白盒化评分”,即把抽象的置信度拆解为医生可理解的累加/扣减项,类似于临床上的评分量表;
- 基础分
- 含义:模型对某类疾病的基准判断。
- 例子:只要患者出现“胸痛”这一主诉,系统给予一个初始的基础置信度(例如0.2分)。
- 指标匹配分
- 含义:关键临床证据的加权累加。
- 例子:心电图显示ST段抬高(+0.3分),肌钙蛋白升高(+0.4分)。匹配的证据越多,分数越高。
- 人群风险分
- 含义:基于患者背景的先验概率调整。
- 例子:患者是65岁男性且有吸烟史,属于高危人群,额外加分(+0.1分);若是20岁运动员,则不加分。
- 干扰因素分
- 含义:降低可信度的扣分项(数据质量或矛盾证据)。
- 例子:影像图片模糊(-0.2分),或者患者正在服用可能引起假阳性的药物(-0.15分)。
例如糖尿病风险:
- 基础分:0.5
- 空腹血糖达标:+0.2
- 糖化达标:+0.2
- 年龄≥60:+0.1
- 无并发症:-0.09
- 最终:0.91
4. 大模型在SKILL中的定位
大模型不负责核心决策,只负责三件事:
- 自然语言理解与信息结构化
- 语义匹配最合适的 SKILL
- 根据 SKILL 输出填充解释文本,使其通顺可读
这种“大模型负责理解,SKILL负责决策与解释”的结构,既保留大模型能力,又实现XAI。
五、SKILL+XAI应用实践
1. 示例:医疗可解释AI诊断
这是一个基于SKILL架构的糖尿病风险评估示例,展示了如何让AI诊断过程可追溯、可解释。
- MedicalSkill:技能基类,封装执行逻辑与输出格式
- diabetes_risk_logic:糖尿病风险推理规则
- generate_xai_report:生成可解释诊断报告
class MedicalSkill:
def __init__(self, skill_id, name, evidence, logic):
self.skill_id = skill_id
self.name = name
self.evidence = evidence # 医学依据
self.logic = logic # 推理规则
def execute(self, data):
# 执行技能并返回可解释结果
result, reason, conf = self.logic(data)
return {
"skill_id": self.skill_id,
"skill_name": self.name,
"evidence": self.evidence,
"result": result,
"reason_chain": reason,
"confidence": conf
}
# 定义糖尿病风险评估 SKILL
def diabetes_risk_logic(data):
fbs = data.get("fbs", 0) # 空腹血糖
hba1c = data.get("hba1c", 0) # 糖化
age = data.get("age", 0)
reason = []
score = 0.5
if fbs >= 7.0:
reason.append(f"空腹血糖 {fbs} ≥ 7.0 mmol/L,达到诊断阈值")
score += 0.2
if hba1c >= 6.5:
reason.append(f"糖化血红蛋白 {hba1c} ≥ 6.5%,达到诊断阈值")
score += 0.2
if age >= 60:
reason.append(f"年龄 {age} ≥ 60 岁,属于高危人群")
score += 0.1
score -= 0.09 # 无既往病史修正
score = round(score, 2)
if score >= 0.8:
result = "高度提示2型糖尿病可能"
elif score >= 0.6:
result = "糖尿病前期风险"
else:
result = "血糖异常风险较低"
return result, reason, score
# 实例化 SKILL
skill_diabetes = MedicalSkill(
skill_id="SKILL_DIABETES_RISK_v1.2",
name="糖尿病风险评估技能",
evidence="《中国2型糖尿病防治指南(2022年版)》",
logic=diabetes_risk_logic
)
# 模拟患者数据
patient = {
"age": 62,
"fbs": 8.5,
"hba1c": 7.6
}
# 执行并输出可解释结果
output = skill_diabetes.execute(patient)
for k, v in output.items():
print(f"{k}: {v}")
def generate_xai_report(output):
print("=" * 50)
print("【医疗AI可解释诊断报告】")
print("=" * 50)
print(f"结论: {output['result']}")
print(f"触发技能: {output['skill_name']}")
print(f"医学依据: {output['evidence']}")
print(f"置信度: {output['confidence']}")
print("\n判断依据链:")
for idx, r in enumerate(output['reason_chain'], 1):
print(f"{idx}. {r}")
generate_xai_report(output)重点说明:
- 可解释输出:每个SKILL返回 evidence(医学依据)、reason_chain(判断链)、confidence(置信度)
- 规则透明:血糖、年龄等指标对应的阈值和权重清晰可见,支持审计
- 置信度量化:基于多因素打分(0-1),结果分级明确
- 医学依据溯源:标注《中国2型糖尿病防治指南》等权威来源
- 模块化设计:技能可独立更新,如更换诊断标准或调整阈值
输出结果:
skill_id: SKILL_DIABETES_RISK_v1.2 skill_name: 糖尿病风险评估技能 evidence: 《中国2型糖尿病防治指南(2022年版)》 result: 高度提示2型糖尿病可能 reason_chain: ['空腹血糖 8.5 ≥ 7.0 mmol/L,达到诊断阈值', '糖化血红蛋白 7.6 ≥ 6.5%,达到诊断阈值', '年龄 62 ≥ 60 岁,属于高危人群'] confidence: 0.91 ================================================== 【医疗AI可解释诊断报告】 ================================================== 结论: 高度提示2型糖尿病可能 触发技能: 糖尿病风险评估技能 医学依据: 《中国2型糖尿病防治指南(2022年版)》 置信度: 0.91 判断依据链: 1. 空腹血糖 8.5 ≥ 7.0 mmol/L,达到诊断阈值 2. 糖化血红蛋白 7.6 ≥ 6.5%,达到诊断阈值 3. 年龄 62 ≥ 60 岁,属于高危人群
2. 示例:完整前后端接口对接
2.1 后端:SKILL 核心引擎 + API 接口
# main.py (后端)
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Dict, Any, List
from fastapi.middleware.cors import CORSMiddleware
import uvicorn
app = FastAPI(title="SKILL-XAI 医疗可解释引擎", version="1.0")
# CORS 中间件
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 医学依据库
EVIDENCE_DB = {
"diabetes": "《中国2型糖尿病防治指南(2022年版)》"
}
# SKILL 基础类
class MedicalSkill:
def __init__(self, skill_id: str, name: str, evidence: str, logic_func):
self.skill_id = skill_id
self.name = name
self.evidence = evidence
self.logic_func = logic_func
def execute(self, data: Dict[str, Any]) -> Dict[str, Any]:
res, reason, conf = self.logic_func(data)
return {
"skill_id": self.skill_id,
"skill_name": self.name,
"evidence": self.evidence,
"result": res,
"reason_chain": reason,
"confidence": round(conf, 2)
}
# 糖尿病风险 SKILL 逻辑
def diabetes_logic(data):
fbs = data.get("fbs", 0)
hba1c = data.get("hba1c", 0)
age = data.get("age", 0)
reason = []
score = 0.5
if fbs >= 7.0:
reason.append(f"空腹血糖 {fbs} ≥ 7.0 mmol/L(诊断阈值)")
score += 0.2
if hba1c >= 6.5:
reason.append(f"糖化血红蛋白 {hba1c} ≥ 6.5%(诊断阈值)")
score += 0.2
if age >= 60:
reason.append(f"年龄 {age} ≥ 60 岁(高危人群)")
score += 0.1
score -= 0.09
if score >= 0.8:
result = "高度提示2型糖尿病"
elif score >= 0.6:
result = "糖尿病前期"
else:
result = "血糖正常或轻度异常"
return result, reason, score
# 注册 SKILL
skill_diabetes = MedicalSkill(
skill_id="SKILL_DIABETES_V1.2",
name="糖尿病风险评估",
evidence=EVIDENCE_DB["diabetes"],
logic_func=diabetes_logic
)
# 请求体模型
class PatientRequest(BaseModel):
age: int
fbs: float
hba1c: float
# 接口
@app.post("/api/skill/diabetes", summary="糖尿病风险 XAI 评估")
async def diabetes_assess(req: PatientRequest):
try:
data = req.dict()
result = skill_diabetes.execute(data)
return {"code": 200, "msg": "success", "data": result}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/api/skill/list", summary="获取SKILL列表")
async def skill_list():
return {
"code": 200,
"data": [
{"skill_id": skill_diabetes.skill_id, "name": skill_diabetes.name}
]
}
if __name__ == "__main__":
uvicorn.run("main:app", host="0.0.0.0", port=8001, reload=True)2.2 前端:Vue3 + Axios
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>SKILL-XAI 医疗可解释系统</title>
<script src="https://cdn.jsdelivr.net/npm/vue@3/dist/vue.global.prod.js"></script>
<script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script>
<style>
.container{max-width:900px;margin:30px auto;padding:20px;font-family:Microsoft YaHei;}
.card{padding:20px;border-radius:12px;background:#f9f9f9;margin:16px 0;box-shadow:0 2px 8px rgba(0,0,0,0.1);}
.btn{padding:10px 20px;background:#2E86AB;color:white;border:none;border-radius:8px;cursor:pointer;}
.input{padding:10px;width:100%;margin:8px 0;border:1px solid #ddd;border-radius:8px;}
.reason{background:#eef;padding:10px;border-radius:8px;margin:8px 0;}
</style>
</head>
<body>
<div id="app" class="container">
<h2>SKILL 可解释医疗 AI 引擎</h2>
<div class="card">
<h3>糖尿病风险评估</h3>
<input v-model.number="age" class="input" placeholder="年龄">
<input v-model.number="fbs" class="input" placeholder="空腹血糖(mmol/L)">
<input v-model.number="hba1c" class="input" placeholder="糖化血红蛋白(%)">
<button @click="runSkill" class="btn">执行评估</button>
</div>
<div v-if="result" class="card">
<h3>可解释报告</h3>
<p><b>结论:</b>{{result.result}}</p>
<p><b>触发SKILL:</b>{{result.skill_name}}</p>
<p><b>医学依据:</b>{{result.evidence}}</p>
<p><b>置信度:</b>{{result.confidence}}</p>
<div class="reason">
<p><b>决策依据链:</b></p>
<p v-for="(item,i) in result.reason_chain" :key="i">{{i+1}}. {{item}}</p>
</div>
</div>
</div>
<script>
const { createApp } = Vue;
createApp({
data() {
return { age: 62, fbs: 8.5, hba1c:7.6, result: null }
},
methods: {
async runSkill() {
try {
const res = await axios.post("http://127.0.0.1:8001/api/skill/diabetes", {
age: this.age, fbs: this.fbs, hba1c: this.hba1c
});
this.result = res.data.data;
} catch(e) {
alert("请求失败:" + e.message);
}
}
}
}).mount('#app');
</script>
</body>
</html>2.3 示例运行输出
2.3.1 服务启动
运行:python main.py 访问:http://127.0.0.1:8001/docs 可查看自动 API 文档
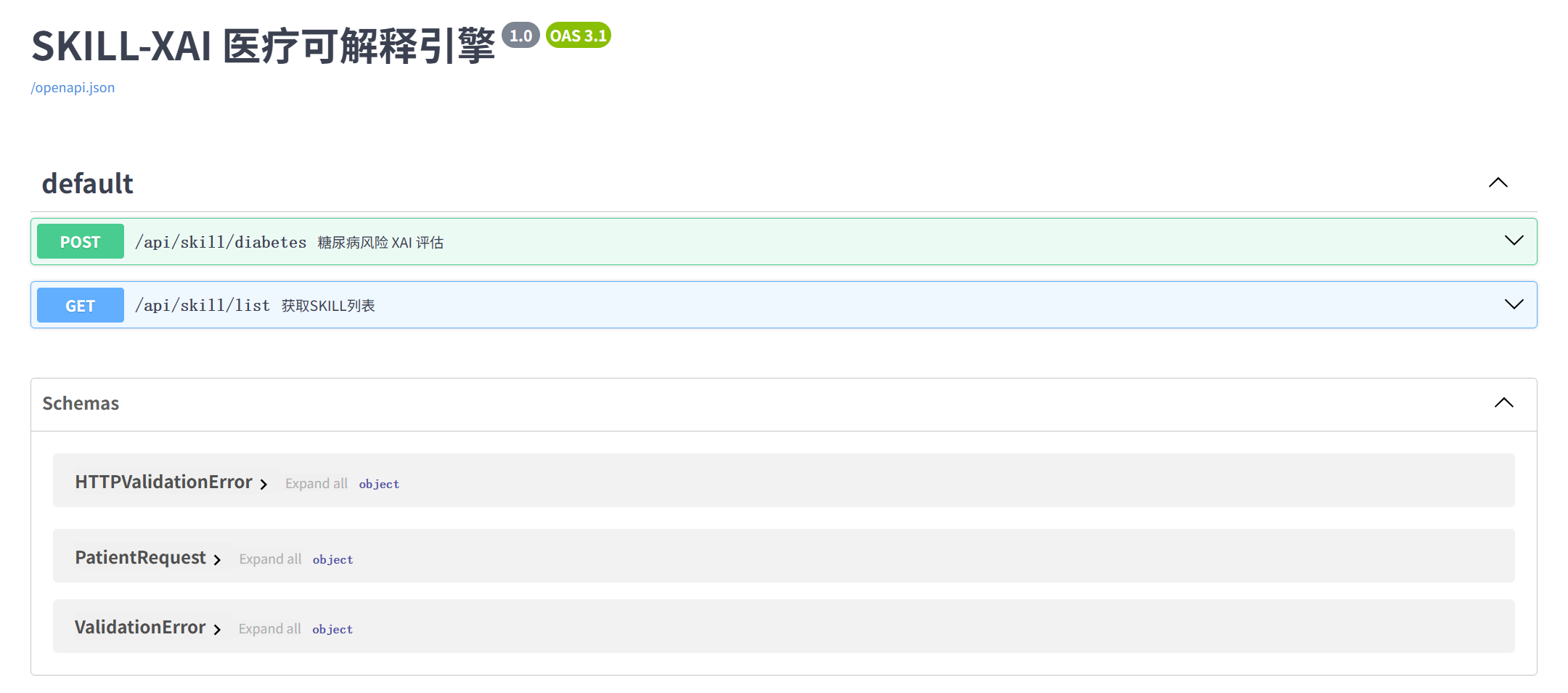
接口API说明文档:
2.3.2 执行糖尿病风险评估案例
直接双击 index.html 输入数据 → 点击执行 → 立即获得 SKILL 可解释结果
2.3.3 糖尿病风险评估解释报告
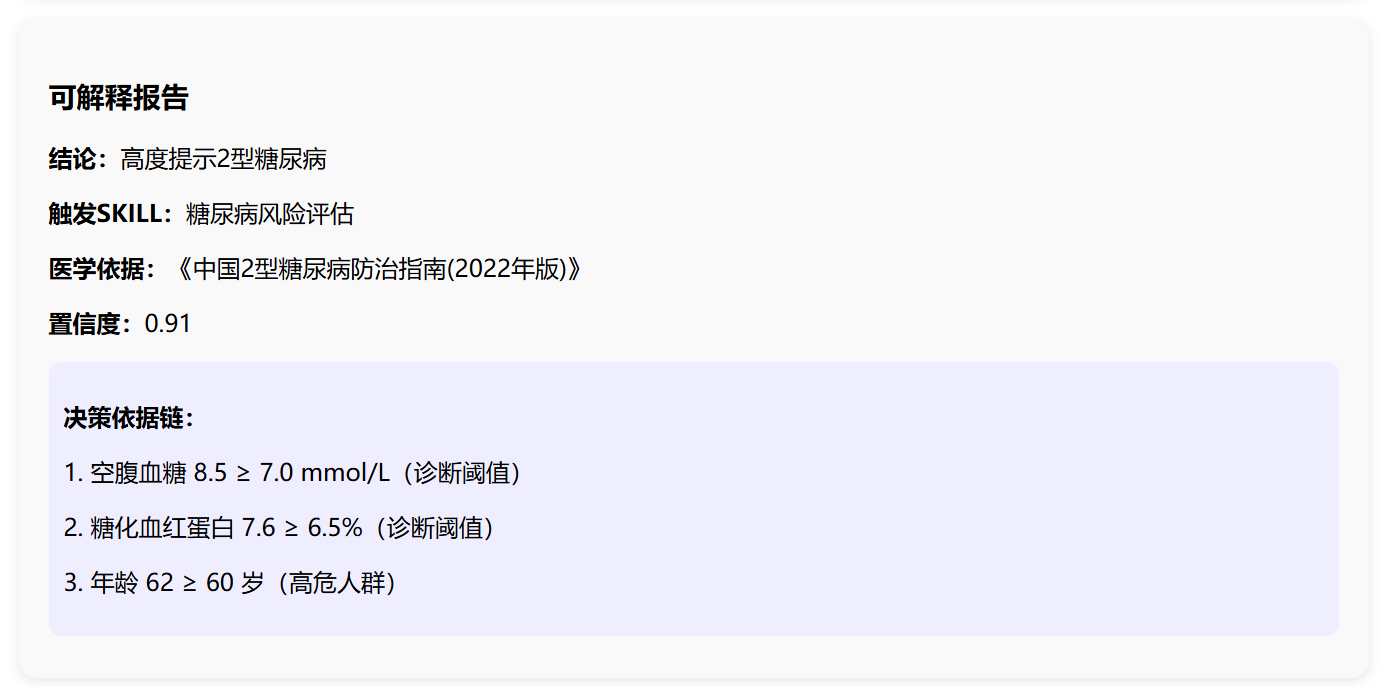
六、总结
通过SKILL架构在医疗可解释AI(XAI)里的落地逻辑说明医疗AI真不是堆大模型参数就行,结构比能力更重要。大模型虽然理解强、对话自然,但天生是黑盒,还容易出医学幻觉,直接用在临床既不安全也不合规。而 SKILL这套模块化设计,刚好补上了这个短板,把复杂诊疗拆成一个个可追溯、可审计的技能单元,每个判断都能对应到指南条文、指标阈值和触发逻辑,形成完整可解释链路。大模型只负责语义理解和信息抽取,SKILL 引擎负责规则执行、依据匹配和置信度计算,最后输出带完整决策链的报告。这种“大模型做理解、SKILL 做决策”的模式,既保留了大模型的易用性,又实现了医疗场景必需的合规、透明与安全。
通过经验也充分了解到端到端大模型效果,医疗场景一定要先把结构化、可解释、强依据这三件事做扎实。未来医疗AI必然走向大模型 + SKILL+XAI的融合路线,这套架构体系,无论是做项目、写论文还是准备申报,都会是非常核心的竞争力。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号