我用蓝耘元生代 + QClaw 搜近三年 LLM Agent 综述论文,整理出一份能直接进入科研阅读的文献综述
原创
我用蓝耘元生代 + QClaw 搜近三年 LLM Agent 综述论文,整理出一份能直接进入科研阅读的文献综述
原创
承渊政道
发布于 2026-06-18 16:34:59
发布于 2026-06-18 16:34:59
如果你最近也在跟 LLM Agent 这个方向,大概率会有同一种感觉:论文很多,概念更新很快,但真正想写一篇靠谱的文献综述时,反而不知道从哪里下手。今天看到的是 Planning、Memory、Tool Use,明天又冒出 Multi-Agent、Agent Safety、Harness Engineering、Externalization。每个词都像是一个入口,但顺着任何一个入口走进去,都会牵出一长串论文、框架和评估方法。
我这次遇到的问题也一样。手动搜当然可以,但很容易陷入两个极端:要么只看了几篇高引用综述,就误以为自己掌握了全貌;要么打开几十个网页和 PDF,最后资料堆了一堆,分类体系却越来越乱。更麻烦的是,LLM Agent 不是一个单点技术,它同时涉及模型推理、任务规划、长期记忆、工具调用、多智能体协作、评估体系和安全边界。如果没有一个能持续整理上下文的工作流,后面写出来的综述很容易变成“论文摘要拼盘”。
所以我这次没有直接让大模型回答“LLM Agent 有哪些综述论文”,而是先搭了一个更可复查的科研辅助流程:用蓝耘元生代 MaaS 接入 GLM-5.1,把模型能力接到 QClaw 里,再让 QClaw 多轮检索近三年 LLM Agent 综述论文,最后生成一份可以继续人工复核和改写的文献综述初稿。
这篇文章记录的就是这条链路。它不是“我有一个朋友用了某平台”的转述,也不是把产品功能重新包装一遍,而是一次完整实操:为什么选这个模型服务、接入过程有没有坑、Agent 实际调用了哪些工具、最后整理出的 LLM Agent 文献脉络是否有参考价值,我都会尽量讲清楚。
一开始我给自己的标准其实很简单:不能写空话。文章里提到的数据必须能落到截图、论文或公开来源;蓝耘元生代如果有帮助,也要说清楚它到底帮在了哪一环,而不是泛泛而谈“高效、稳定、强大”。
一、为什么先做模型服务选型,而不是直接打开 QClaw 开搜
做文献综述这件事,对模型服务的要求和普通问答不太一样。
普通问答可能更看重一句话答得准不准;文献综述则更像一个长链路任务:先理解主题,再拆分检索维度,然后搜索论文、阅读摘要、比较分类体系、去重、归纳趋势,最后还要把结果写成结构化文本。这个过程对模型有几个要求:
- 上下文要足够长。论文题录、摘要、搜索结果和中间笔记会越堆越多,短上下文很容易丢掉前面的判断。
- 工具调用要稳定。QClaw 的价值不只在“对话”,而在能连续调用搜索、文件写入等工具完成任务。
- 输出速度不能太慢。综述整理通常需要多轮检索和长文本生成,如果每次等待太久,工作流会被打断。
- 成本要可控。科研检索不是一次性短问答,长上下文和多轮工具调用都会消耗 token。
基于这个判断,我先在蓝耘元生代 MaaS 平台里看了可用模型和服务商数据。GLM-5.1 这一页给我的第一印象是,它的定位和我这次任务比较贴:支持工具调用、推理和编码能力,适合长任务自主执行。页面摘要里显示 GLM-5.1 的上下文长度约 192K 到 202K,输入和输出价格在不同服务商行里有所差异;我最终关注的是蓝耘元生代这一行的综合表现,而不是只看模型名字。
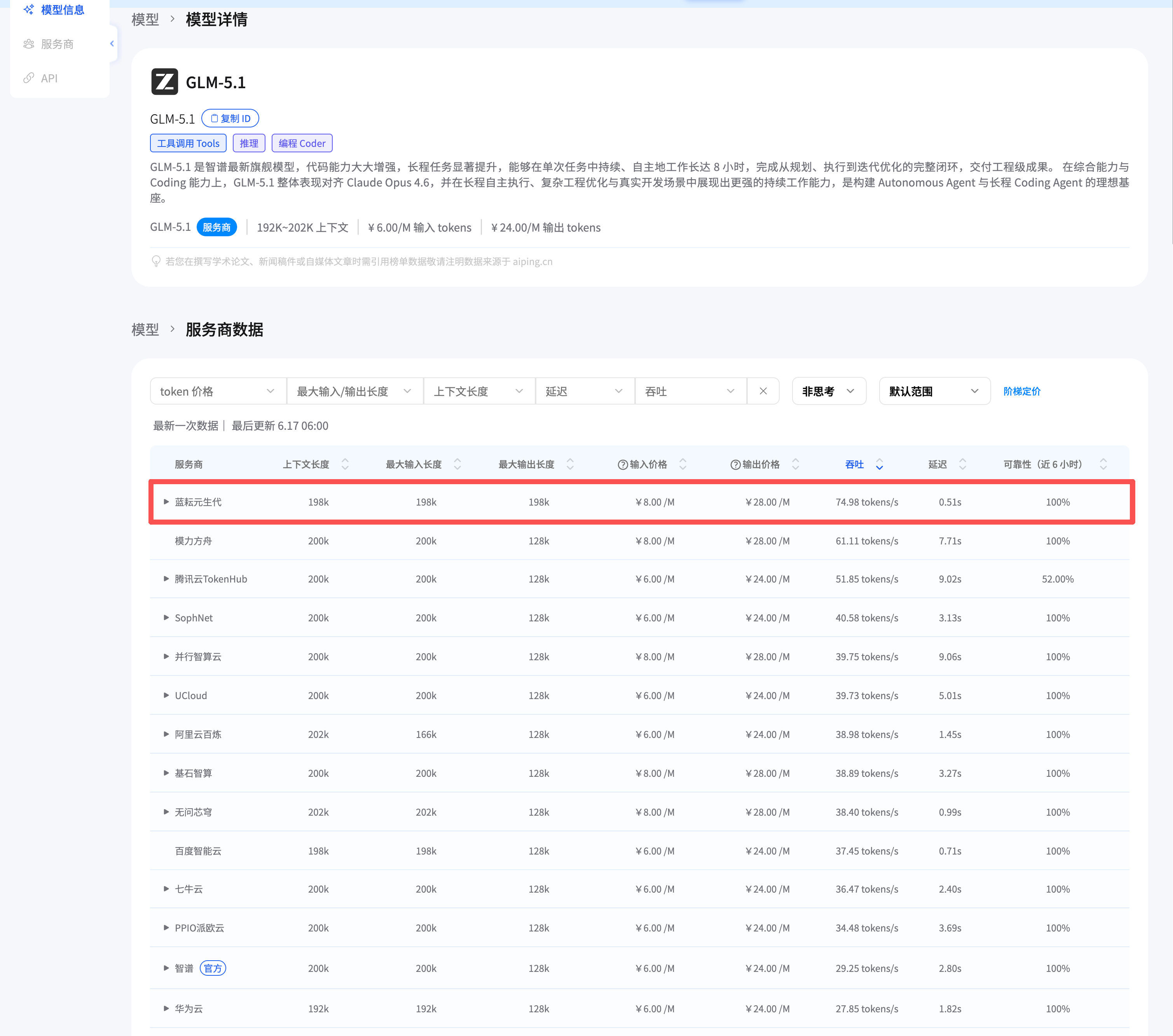
这里有一个容易被忽略的点:同一个模型,不同服务商跑出来的体验可能差很多。模型能力决定上限,服务商的推理链路决定你能不能稳定接近这个上限。对 Agent 场景来说,这个差异会被放大,因为一次任务里可能连续请求十几次甚至几十次。
从截图看,GLM-5.1 在蓝耘元生代这一行的上下文长度为 198K,最大输入长度 198K,最大输出长度 198K,吞吐为 74.98 tokens/s,延迟为 0.51s,近 6 小时可靠性为 100%。价格行显示为输入 8 元/M tokens、输出 28 元/M tokens。页面上方的模型摘要区还显示了另一组起步价格信息,所以我在实际选型时没有只看标题价格,而是以服务商行数据作为接入前的直接参考。
二、性能数据怎么看:吞吐、延迟、可靠性缺一不可
我最先看的是吞吐。因为这次任务不是短问答,而是让 Agent 搜论文、读材料、写综述。输出速度直接影响体验,尤其当模型要生成几千字文献整理时,吞吐低会让整个流程变得很拖。
AI Ping 的近 7 日平均数据显示,在 2026-06-10 06:00 到 2026-06-17 06:00 这个窗口里,蓝耘元生代的 GLM-5.1 平均吞吐为 90.37 tokens/s,最低 68.54 tokens/s,最高 99.00 tokens/s。这个数据对我来说很关键,因为它不是某一次“跑得快”的截图,而是一个连续时间窗口里的表现。
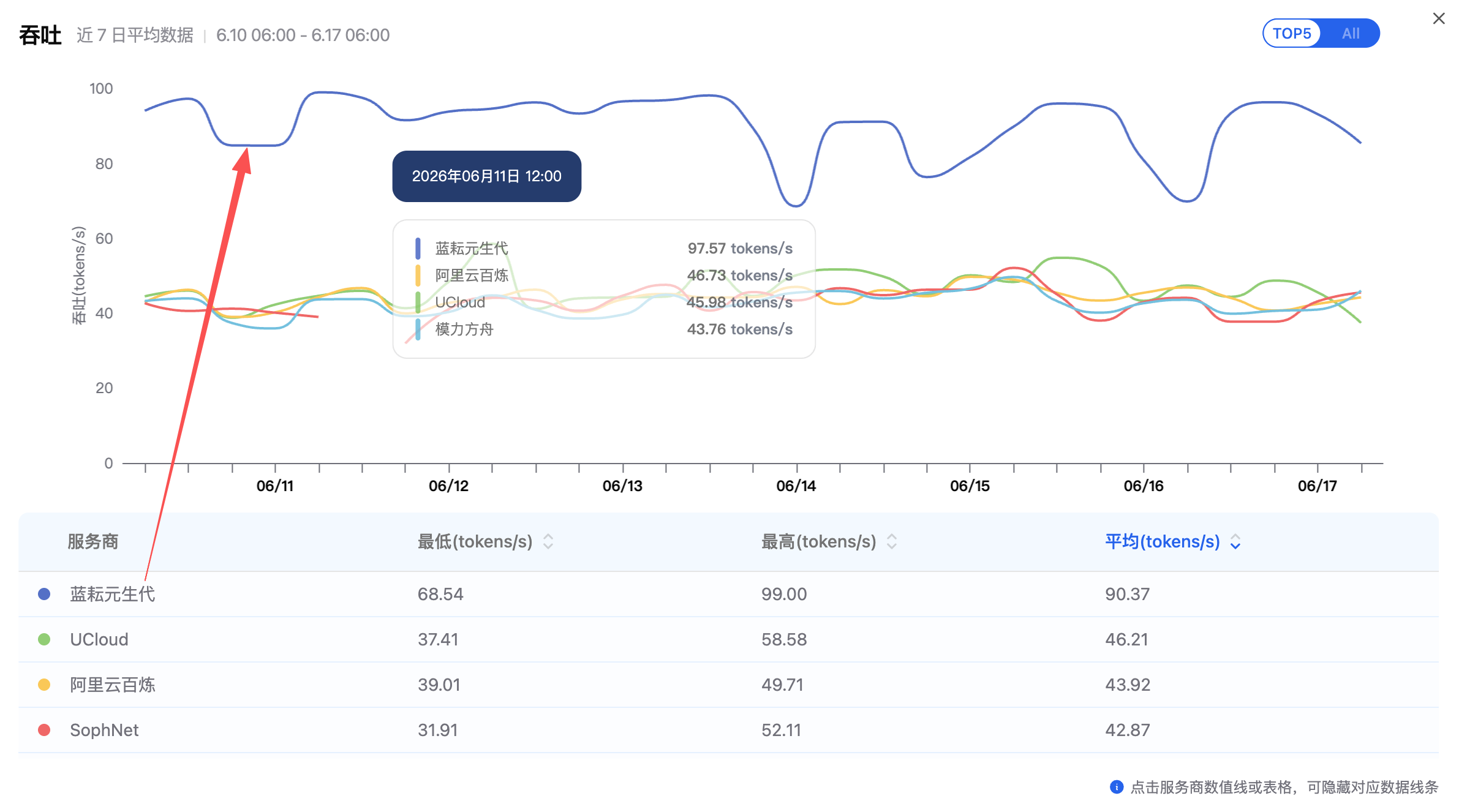
然后看延迟。对 Agent 来说,延迟不是越低越好这么简单,而是要看 P90 之类的分位数。因为多轮工具调用里,只要某几次请求卡住,整个任务都会被拉慢。
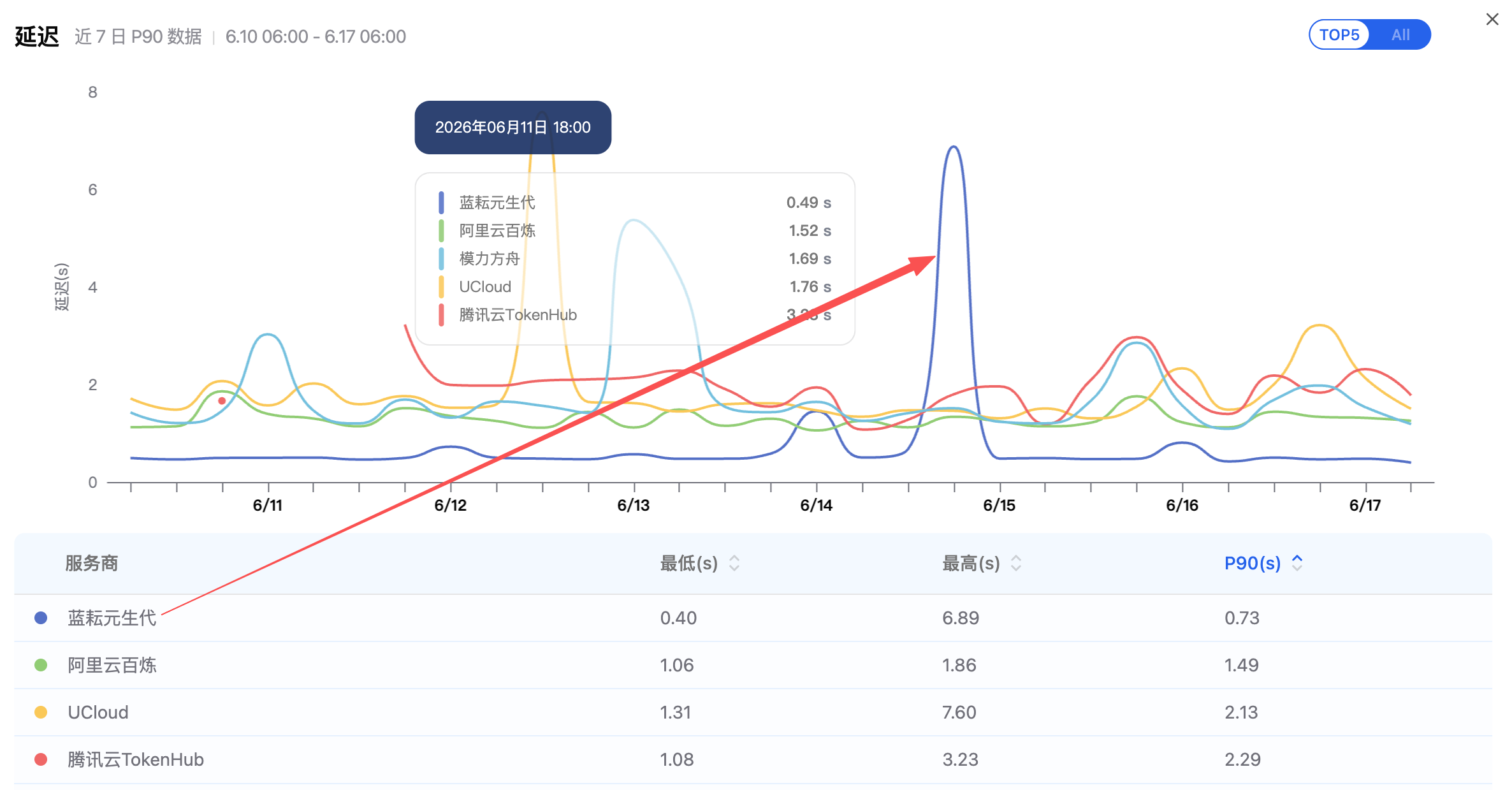
同一时间窗口下,蓝耘元生代 GLM-5.1 的 P90 延迟为 0.73s,最低 0.40s,最高 6.89s。图中能看到 6 月 14 日附近有一次明显尖峰,但 P90 仍然保持在 1 秒以内。这个结果让我更放心:它不是完全没有波动,但大多数请求的体验是稳定的。
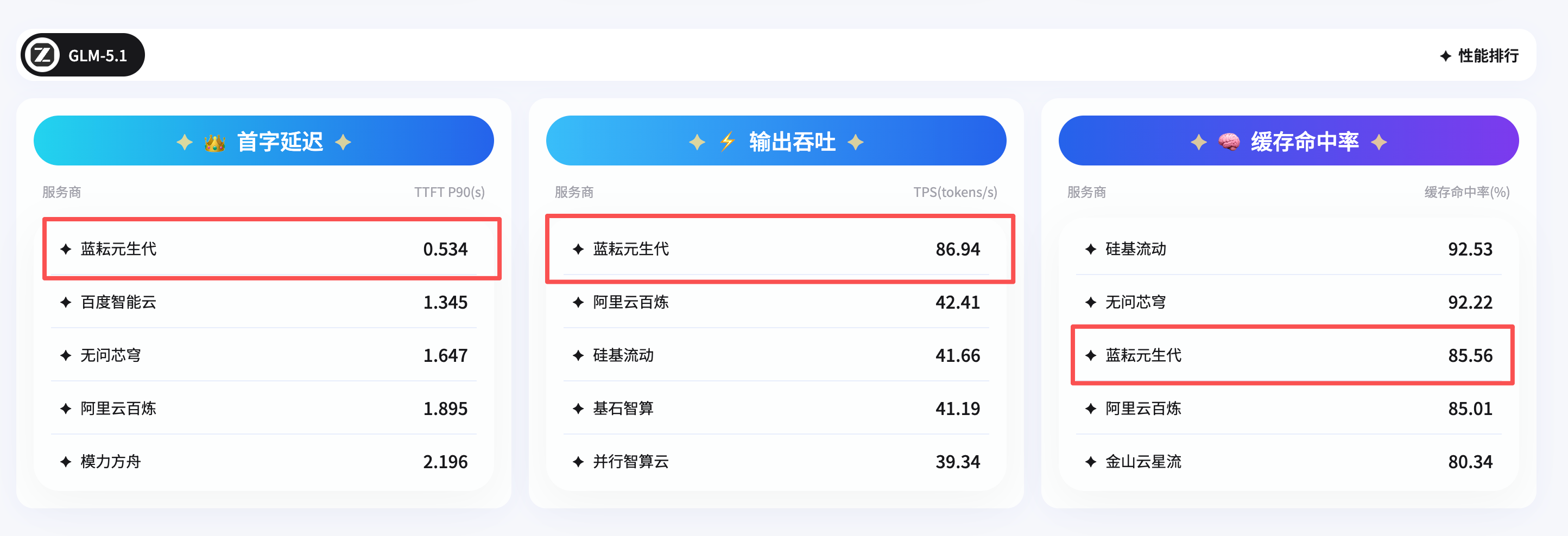
第三个指标是排行榜页。截图里 GLM-5.1 的三个核心指标分别是:首字延迟 TTFT P90 为 0.534s,输出吞吐 TPS 为 86.94 tokens/s,缓存命中率为 85.56%。我会把这类数据理解为“交互体感”的补充:TTFT 影响第一段响应什么时候出来,TPS 影响长文本生成速度,缓存命中率则可能影响重复或相似请求的效率。
我还顺手看了 Qwen3-235B-A22B。这个模型本身也很强,尤其在通用能力和推理场景里值得考虑。截图里,Qwen3-235B-A22B 在蓝耘元生代的吞吐为 68.13 tokens/s,延迟 0.26s,近 6 小时可靠性 100%;价格显示为输入 4 元/M、输出 12 元/M。
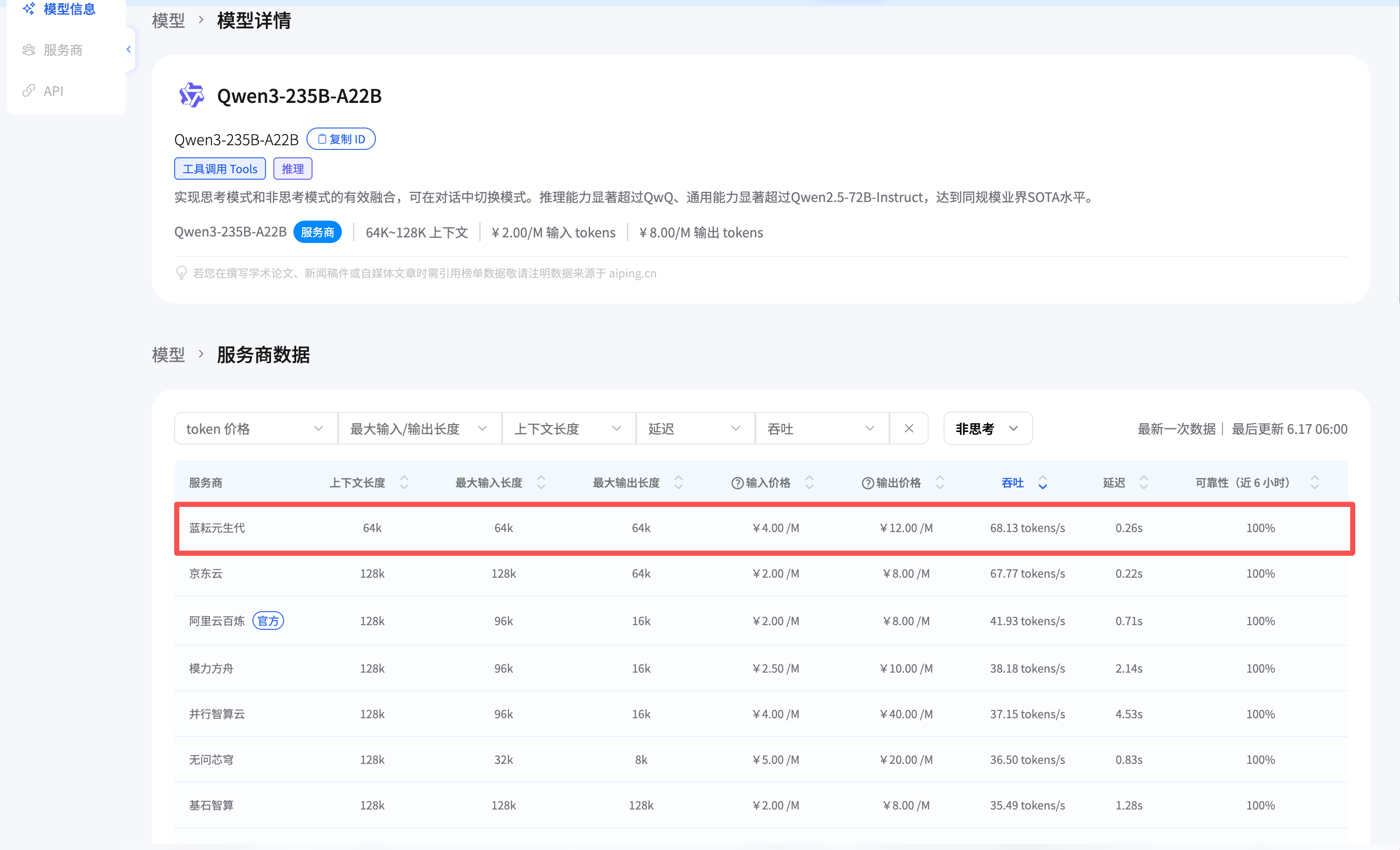
最后我还是选了 GLM-5.1。原因不是 Qwen3 不好,而是这次任务更偏“长链路 Agent + 文献整理 + 代码/工具能力”。GLM-5.1 页面明确标注了工具调用、推理和编程 Coder,并且模型介绍强调长程任务自主执行能力。对我这次的 QClaw 工作流来说,这个匹配度更高。
三、把蓝耘元生代接进 QClaw:关键是 OpenAI 兼容协议
选好模型之后,我打开 QClaw。QClaw 的界面很适合做这类“让 Agent 干活”的任务:左侧是 Agent 列表,中间是对话入口,底部可以选择模型和连接方式。我先进入连接配置,准备把蓝耘元生代 MaaS 的 API 接进去。
在蓝耘元生代 MaaS 平台侧,我进入 API KEY 管理页,点击“创建 API KEY”。这里必须提醒一句:API Key 是安全凭证,正式写博客时千万不要把完整 key 截出来。我的截图里 key 已经被遮挡,只保留了操作路径和状态信息。
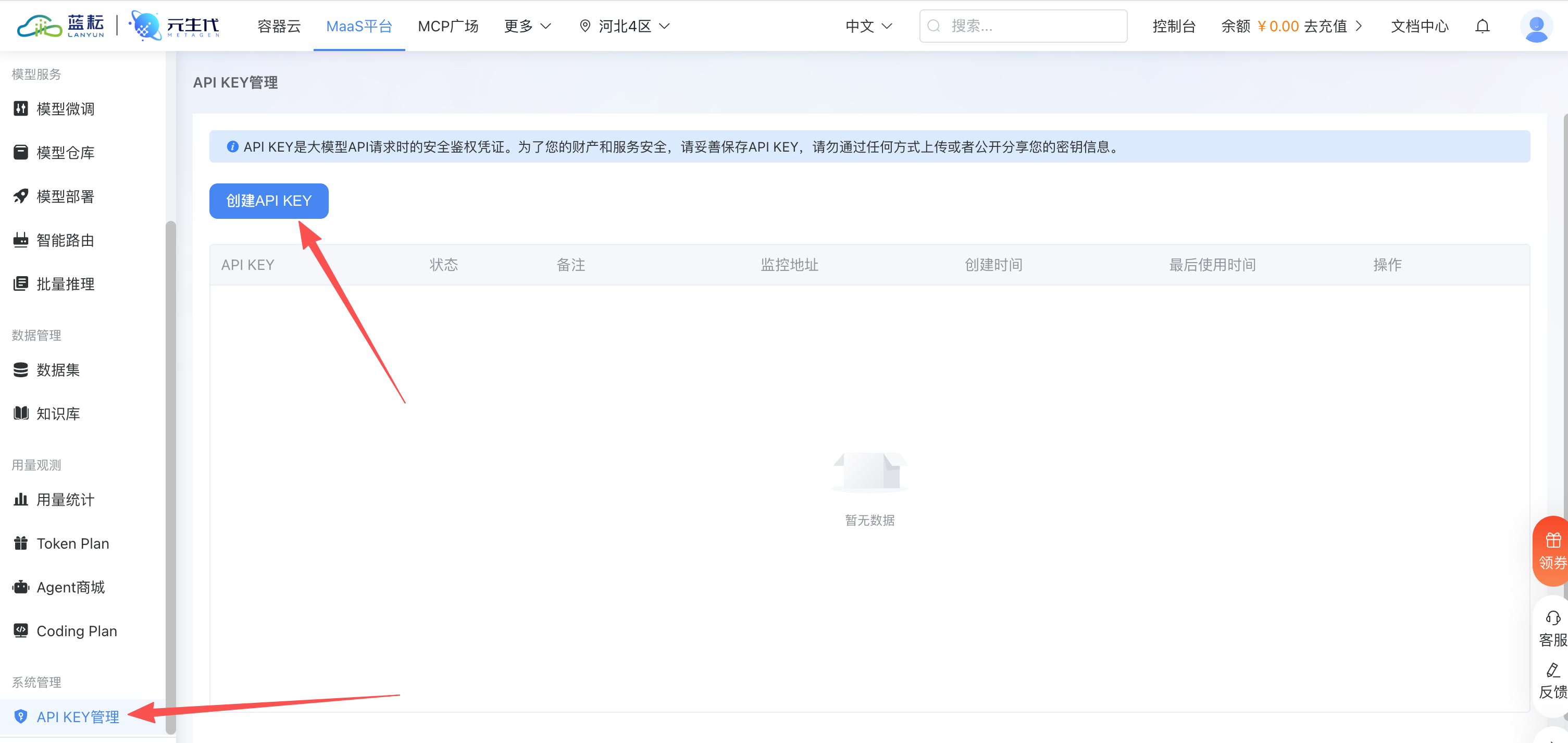
创建完成后,API Key 管理页会展示 key 的状态、备注、监控地址、创建时间和最后使用时间。我的这次备注写的是 QClaw,方便后续排查用量来源。截图里也能看到 key 处于“使用中”状态。

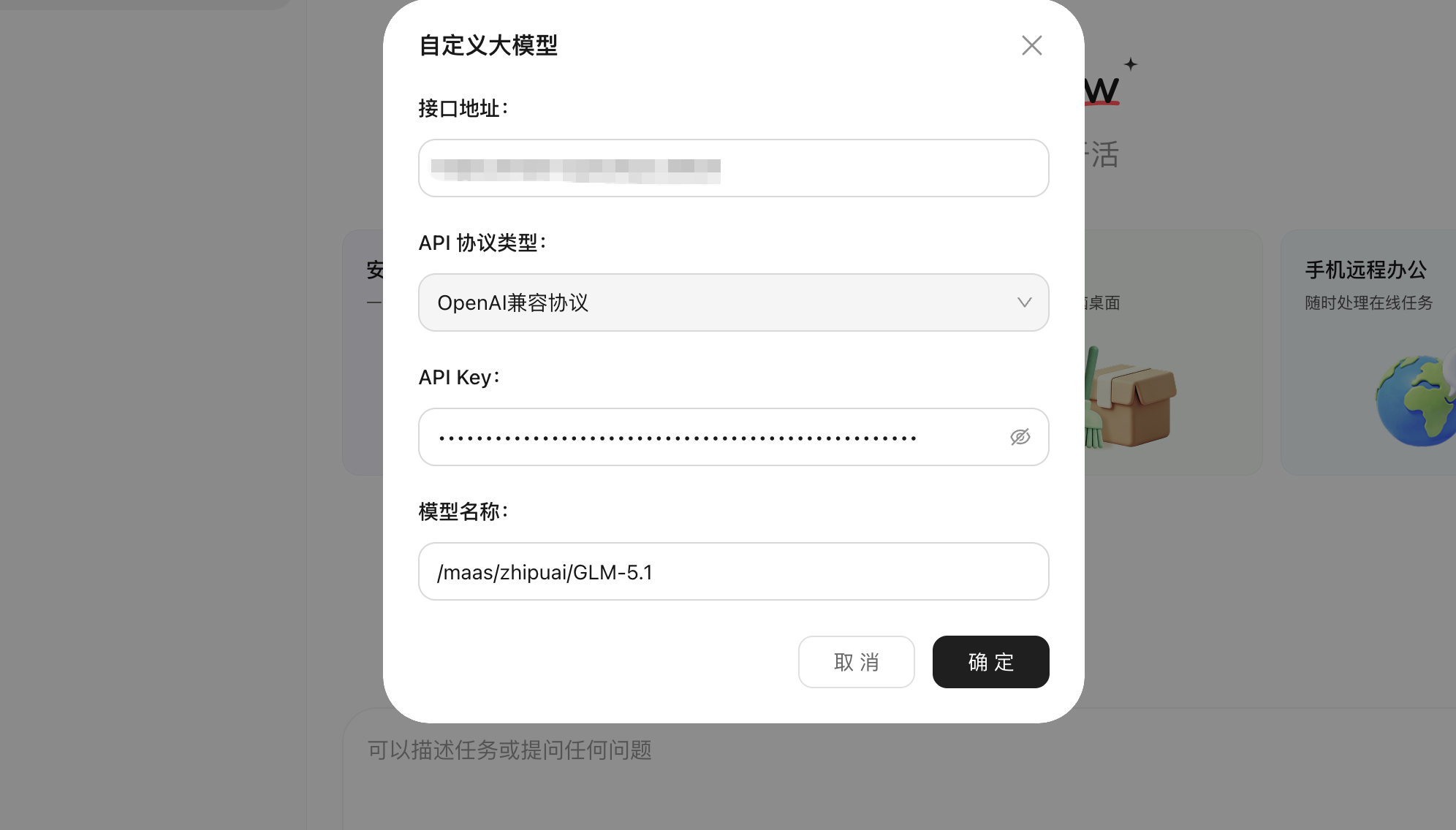
回到 QClaw 后,我在“自定义大模型”弹窗里填入接口地址、协议类型、API Key 和模型名称。协议类型选择 OpenAI 兼容协议,模型名称填写 /maas/zhipuai/GLM-5.1。
这一步的工程价值很直接:如果平台支持 OpenAI 兼容协议,很多桌面 Agent、开发框架和已有 SDK 都可以低成本迁移。蓝耘官网对 MaaS 平台的描述也提到,它是企业级大模型统一网关与调度平台,支持多模型统一接入;蓝耘官网产品介绍里还提到其大模型服务平台提供智能路由、统一鉴权与成本管控能力(来源:蓝耘元生代 MaaS、蓝耘科技官网)。
到这里,基础链路就通了:QClaw 负责 Agent 工作流,蓝耘元生代负责模型推理服务,GLM-5.1 负责长上下文推理和工具调用。
四、给 QClaw 的任务提示词:别只说“帮我搜”
真正开始检索前,我没有只写“帮我搜论文”。因为这类提示词太宽,模型容易给出一堆没有边界的结果。我给 QClaw 的任务是:
帮我搜近3年 LLM Agent 综述论文,整理成文献综述给我

这个提示词看起来短,但里面有三个限制:
- 时间范围:近 3 年,也就是 2023 到 2026。
- 文献类型:综述论文,不是普通方法论文。
- 产出形式:整理成文献综述,而不是只列链接。
QClaw 随后开始多轮调用工具。从过程截图看,它先读取 skill 规则,再多角度搜索 LLM Agent 综述论文,接着补充英文论文、特定方向综述,最后写入 Markdown 文件和任务 artifact。整个过程调用了 18 次工具。

这一步让我比较满意的地方是,它没有停留在“找到几篇论文”的层面,而是把结果按维度整理出来。QClaw 输出的文档概览里,将近三年 LLM Agent 综述归纳为 9 个方向:通用综述、规划、记忆、工具调用、多智能体、效率与上下文压缩、评估、安全、应用领域。
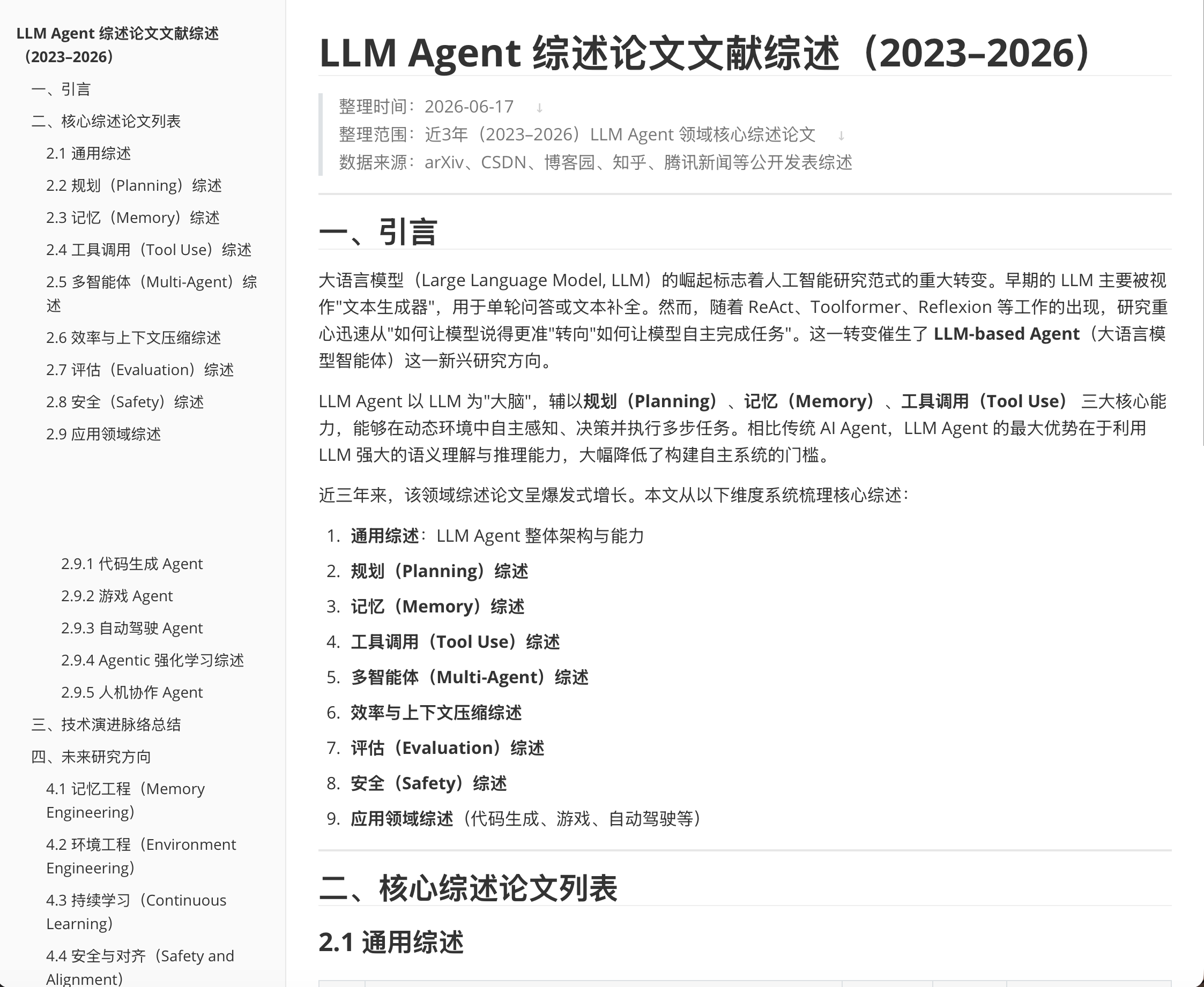
五、QClaw 整理出的文献脉络:LLM Agent 已经从“模型能力”走向“系统工程”
结合 QClaw 的初稿和我后续复核的公开论文来源,我把近三年 LLM Agent 综述的主线概括为一句话:
LLM Agent 的研究重点,正在从“模型能不能自己完成任务”,转向“如何把模型、记忆、工具、协议、评估和安全机制组织成一个可靠系统”。
下面这几类综述,是我认为最值得先读的骨架文献。
方向 | 代表综述 | 对我这次综述写作的价值 |
|---|---|---|
通用框架 | 给出了 LLM-based Autonomous Agents 的整体框架,适合作为入门综述的主轴。 | |
规划 Planning | 将规划方法拆成任务分解、计划选择、外部模块、反思和记忆,适合写“Agent 如何做多步任务”。 | |
记忆 Memory | 系统讨论 Agent 为什么需要记忆,以及记忆模块如何设计和评估。 | |
多智能体 | 将单 Agent 扩展到多 Agent 协作、角色设定、通信和能力演化。 | |
工具学习 | Springer 上的 LLM-Based Agents for Tool Learning: A Survey | 适合理解工具调用不只是函数调用,还包括工具选择、工具学习和工具库组织。 |
评估 | 将 Agent 评估拆到规划、工具使用、自反思、记忆,以及 Web、软件工程、科学 Agent 等应用场景。 | |
安全 | 从数据、训练、对齐、部署到商业化全生命周期讨论安全问题,适合补足 Agent 落地风险。 | |
外化与运行时工程 | Zhou 等人的 Externalization in LLM Agents | 这篇很新,也很值得读。它把记忆、技能、协议和 harness 看作外化的认知基础设施,解释了为什么 Agent 进步不只依赖更大的模型。 |
我会把这些综述分成三层来读。
第一层是“Agent 是什么”。Wang 等人的通用综述非常适合作为起点,它把 LLM Agent 的构成、应用和评估放在一个统一视角下。读完这类文章,至少能明确 Agent 不只是聊天,而是一个围绕目标、环境、行动和反馈构建的系统。
第二层是“Agent 如何干活”。这里重点看 planning、memory 和 tool use。Planning 负责把任务拆开,memory 负责跨轮次保存状态,tool use 负责把模型能力扩展到外部世界。Huang 的规划综述和 Zhang 的记忆综述可以配套看:前者回答“怎么规划”,后者回答“怎么不忘”。
第三层是“Agent 如何可靠落地”。这部分包括 evaluation、safety、multi-agent 和 externalization。尤其是 2025 到 2026 的综述,明显不再满足于讨论一个模型会不会调用工具,而是开始追问:Agent 的可靠性由什么决定?评估集能不能覆盖真实任务?多 Agent 为什么会协作失败?系统外部的记忆、技能、协议和 harness 是不是比模型本体更重要?
这个变化很有意思。早期大家会问“模型会不会推理”;现在更真实的问题是“在一个长任务里,模型、工具、记忆和环境如何不互相拖后腿”。这也是我认为 LLM Agent 研究正在工程化的原因。
六、我的文献综述初稿结构
根据这次检索结果,我会把最终文献综述写成下面这个结构:
- 引言:从 LLM 到 LLM Agent 的研究范式变化。
- LLM Agent 基础框架:角色、目标、环境、规划、行动、反馈。
- Planning 综述:任务分解、计划选择、反思、外部规划器。
- Memory 综述:短期记忆、长期记忆、经验沉淀、记忆评估。
- Tool Use 综述:工具调用、工具学习、工具选择、工具安全。
- Multi-Agent 综述:角色分工、通信机制、协作失败与治理。
- Evaluation 综述:能力评估、过程评估、应用评估、通用 Agent benchmark。
- Safety 综述:提示注入、越权调用、数据泄露、自治风险。
- Externalization 与 Harness 工程:为什么 Agent 的能力越来越依赖外部基础设施。
- 未来方向:记忆工程、环境工程、持续学习、安全对齐、科研 Agent。
如果要写成论文式综述,我会把第 3 到第 8 节作为主体;如果要写成技术博客,我会把第 9 节展开,因为它和实际开发者最相关。
七、蓝耘元生代在这次流程里到底帮了什么
这次我最直观的感受是,蓝耘元生代没有直接替我“写综述”,它提供的是底层模型服务能力。真正的工作链路可以拆成这样:
- 蓝耘元生代 MaaS 提供 GLM-5.1 的统一 API 接入。
- QClaw 通过 OpenAI 兼容协议接入模型。
- QClaw 使用工具完成搜索、读取、整理和写入。
- GLM-5.1 在长上下文、多轮工具调用和长文本输出中负责推理与生成。
- 我再对 QClaw 产出的文献维度和论文来源做复核。
这里面最容易被低估的是第 1 步。如果模型服务不稳定,Agent 的工具链会被频繁打断;如果上下文不够长,文献整理会碎片化;如果成本不可控,长任务就不敢多试几轮。蓝耘元生代对我这次任务的实际帮助,主要体现在三点:
第一,模型接入成本低。OpenAI 兼容协议让 QClaw 接入过程很短,不需要单独改 SDK。
第二,性能数据可参考。模型页和 AI Ping 页能看到吞吐、延迟、可靠性、缓存命中率等指标,选型时不只靠感觉。
第三,长任务体验比较顺。QClaw 这次连续调用 18 次工具,并最终写出 Markdown 文档,整个过程没有因为模型服务中断而失败。
我不想把这写成绝对结论。不同任务、不同时间窗口、不同并发条件下,体验一定会变化。但至少在 2026-06-17 这次实操里,蓝耘元生代 + GLM-5.1 + QClaw 这套组合确实把“搜论文并整理综述”从手工活变成了半自动科研工作流。
八、这次实践给我的三个科研启发
第一个启发是,科研 Agent 的关键不是“让模型替我思考”,而是“让模型帮我维护过程”。
文献综述最麻烦的地方不只是读论文,而是持续维护搜索范围、分类体系、文献去重和中间判断。QClaw 这类 Agent 工具适合做的,正是这些过程性工作。它可以帮我把“搜到什么、按什么维度分、写到哪个文件”连续推进。
第二个启发是,近三年 LLM Agent 综述的关键词已经变了。
2023 年前后,大家更关注 Agent 的统一框架,以及 planning、memory、tool use 三大模块。2024 年之后,多智能体、评估和安全开始变得重要。到 2026 年,externalization、harness、protocol 这样的词开始频繁出现,说明研究者已经意识到:Agent 不是一个模型,而是一套运行时系统。
第三个启发是,选模型不能只看排行榜。
排行榜能提供参考,但科研工作流更看重“模型能力 + 服务商稳定性 + 接入协议 + 成本 + 工具链适配”。这次我选择 GLM-5.1,不是因为它在所有维度都必然最优,而是因为它在这个任务上比较均衡:长上下文、工具调用、推理能力、输出速度和 QClaw 接入成本都满足要求。
九、复盘:如果下次继续优化,我会做什么
如果后续要把这套流程用到更正式的科研项目里,我会加三层验证。
第一层是文献来源验证。QClaw 给出的论文列表需要逐条打开 arXiv、DOI 或出版社页面,确认标题、年份、作者和版本。尤其是 2025 到 2026 的预印本,版本变化很快,不能只看一次搜索结果。
第二层是检索覆盖验证。除了 “LLM Agent survey”,还要补充 “autonomous agents survey”“tool learning agents”“memory mechanism LLM agents”“LLM agent evaluation”“LLM agent safety”“multi-agent LLM survey”等关键词,避免被单一检索词限制。
第三层是综述质量验证。Agent 写出的综述可以作为初稿,但最终一定要人工重写判断部分。比如“Externalization 是否会成为下一阶段主线”这种判断,就不能只引用一篇新论文,而要结合多个方向的趋势一起看。
十、结论
这次实践让我更确信一件事:对科研来说,Agent 最有价值的地方不是替代研究者,而是把研究者从重复检索、格式整理和初稿拼接里解放出来,让人把精力放回判断、取舍和论证。
蓝耘元生代在这里扮演的是模型基础设施角色,QClaw 扮演的是任务执行入口,GLM-5.1 则承担长上下文推理和工具调用。三者组合起来之后,我得到了一条比较完整的科研辅助链路:
选模型服务商 → 接入 Agent 工具 → 多轮搜索论文 → 生成结构化综述 → 人工复核与再写作
这条链路并不复杂,但它有一个优点:每一步都能留下证据。模型服务有性能截图,API 接入有配置截图,检索过程有工具调用记录,最终文档有可继续修改的 Markdown。对我来说,这比一段“看起来很聪明”的模型回答更有价值。
如果要用一句话总结这次体验,我会这样说:
蓝耘元生代 + QClaw 没有替我完成科研,但它把“找资料、搭框架、出初稿”这段最耗时间的前置工作,压缩成了一次可复查、可继续迭代的 Agent 工作流。
参考资料
- Lei Wang et al., A Survey on Large Language Model based Autonomous Agents, arXiv, 2023.
- Xu Huang et al., Understanding the planning of LLM agents: A survey, arXiv, 2024.
- Zeyu Zhang et al., A Survey on the Memory Mechanism of Large Language Model based Agents, arXiv, 2024.
- Taicheng Guo et al., Large Language Model based Multi-Agents: A Survey of Progress and Challenges, arXiv, 2024.
- LLM-Based Agents for Tool Learning: A Survey, Springer, 2025.
- A Survey on Evaluation of LLM-based Agents, arXiv, 2025.
- Evaluation and Benchmarking of LLM Agents: A Survey, arXiv, 2025.
- A Comprehensive Survey in LLM(-Agent) Full Stack Safety, arXiv, 2025.
- Chenyu Zhou et al., Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering, arXiv, 2026.
- 蓝耘元生代 MaaS 平台:https://maas.lanyun.net/
- 蓝耘科技官网产品介绍:https://www.lanyun.net/
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号