OFC 2026深度:Scale Across重构AI数据中心网络,千兆瓦级集群的光互联革命

OFC 2026深度:Scale Across重构AI数据中心网络,千兆瓦级集群的光互联革命

光芯
发布于 2026-06-17 19:56:50
发布于 2026-06-17 19:56:50
◆ Meta:千兆瓦级集群驱动骨干网重构,光技术的通用性优先

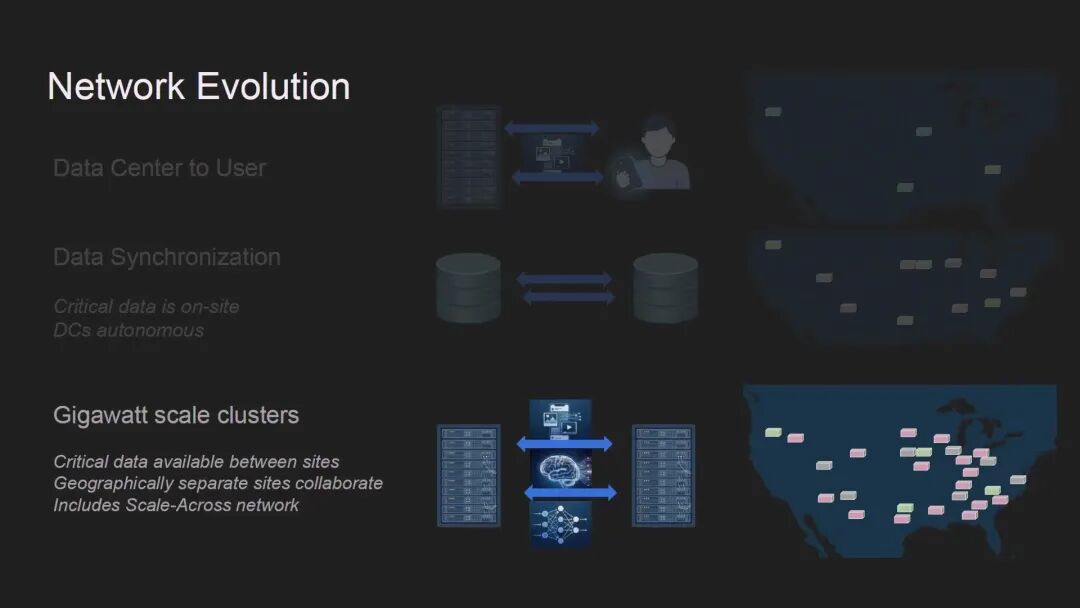
Meta骨干网架构团队的Jeff Rahn首先分享了Meta全球基础设施的演进逻辑。Meta目前在全球拥有数十个数据中心,覆盖北美、欧洲、新加坡等地区,其全球骨干网最初的核心使命是连接数据中心与终端用户,随后逐步承担起数据中心间的数据同步任务——确保各站点的关键数据本地可用,实现数据中心的自治运行。
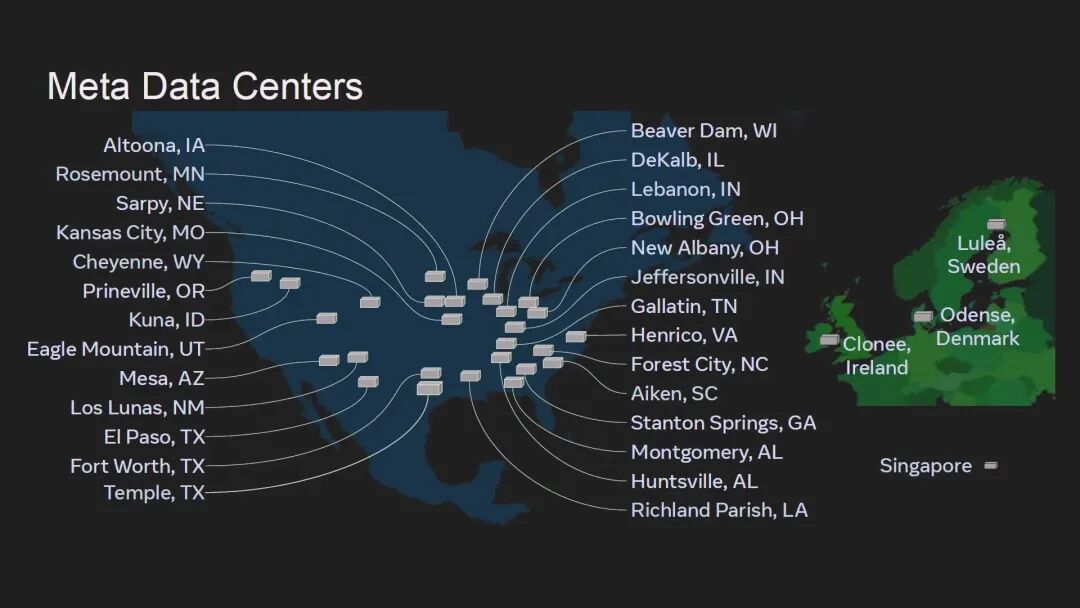
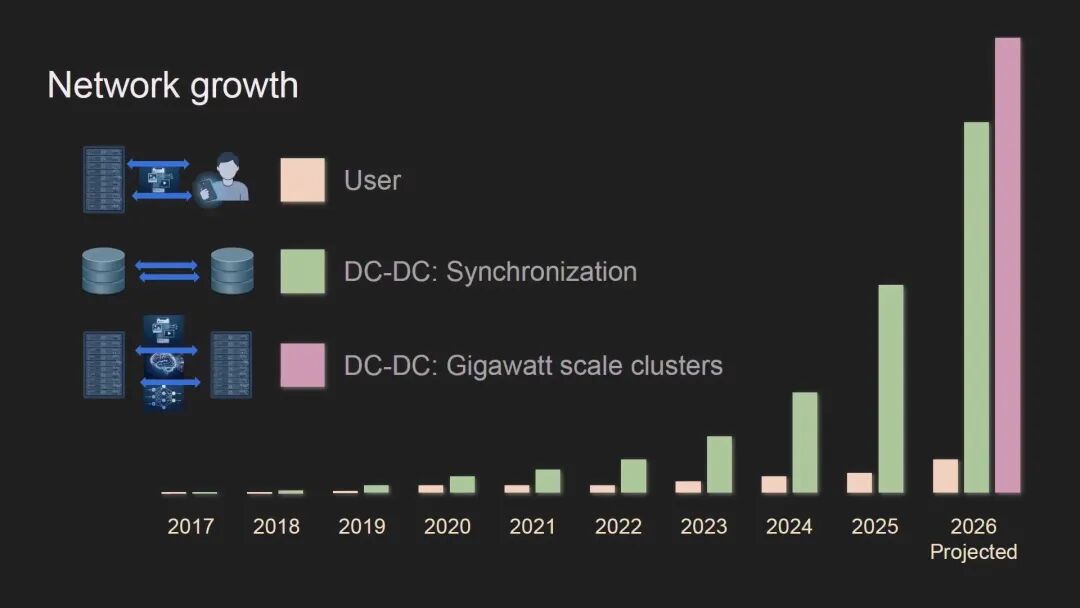
而AI训练的爆发彻底改变了这一格局。为支撑千兆瓦级AI集群,Meta的网络正在新增第三重使命:实现跨站点的非本地数据访问,让地理上分离的多个集群能够协同工作,这正是Meta定义的"Scale Across"网络,其所需的网络容量已经超过了传统的全球骨干网。
在光技术选择上,Meta遵循"距离优先+通用性优先"的原则:

- 3公里以内的建筑间互联,采用成本最低的IMDD光模块;
- 3-10公里范围,继续使用灰光模块,但这一方案需要部署大量光纤,面临巨大的土建工程挑战;
- 10公里以上的互联,全面转向800ZR+与DWDM技术,通过波分复用大幅降低光纤需求。

Jeff Rahn特别强调了支撑Scale Across的五大光生态核心要求:一是标准化、可互操作的接口,Meta在800G世代放弃了私有bookend方案,全面转向开放标准;二是开放线路系统,实现不同厂商光模块的无缝对接;三是代际互操作性,支持分站点逐步升级,目前Meta正在从400G向800G升级,未来800G向1600G升级时无需重新布线;四是C+L波段的满配利用,在部署首日就填满所有可用信道,最大化光纤效率;五是光模块的跨应用通用性,Meta统一采用800ZR+作为标准,避免因项目波动导致的供应链管理混乱。此外,Meta还大规模部署光保护机制,通过光交换实现光纤故障的快速重路由,避免在IP层过度冗余带来的成本与功耗问题。

对于未来,Jeff Rahn明确提出,Meta的长期目标是在未来3-5年内,构建大陆级别的统一计算集群,这需要光互联技术在距离、能效和成本上实现进一步突破。
◆微软:分布式AI的四大核心挑战与技术破局方向
OFC 2026 Workshop:分布式AI训练长距互联边界——多远才算太远?(二)
微软Azure网络与AI团队的Yin随后分享了微软对Scale Across的思考。他指出,AI带来的带宽增长已经远超疫情时期的峰值,而摩尔定律的放缓使得单芯片算力无法满足大模型训练需求,必须通过分布式系统将数万乃至数十万颗XPU连接在一起,这正是Scale Across的核心驱动力。同时,能源分布的不均衡进一步加剧了这一需求:传统云数据中心的功率通常为50-300兆瓦,而新一代AI集群需要1-5吉瓦的电力,单一地区的电网容量无法支撑如此大规模的算力集中,必须将算力分散部署在能源丰富的地区。
Yin重点分析了实现Scale Across面临的四大核心挑战:
第一是可靠性问题。外部光纤面临着枪击、鼠咬、施工挖掘、山体滑坡等各种不可控风险,传统长距离光纤的可用性仅为97.7%,远低于AI训练所需的标准。而同步训练任务对故障极其敏感,任何链路中断都会导致整个训练任务回滚到检查点,造成巨大的算力浪费。
第二是能效问题。传输距离越远,单位比特的能耗越高,长距离相干传输的能效比数据中心内部传输低3个数量级,超过1000皮焦每比特,这成为跨大陆Scale Across的主要瓶颈。
第三是延迟与抖动问题。延迟意味着XPU在等待数据时空转耗电,而All-Reduce、All-Gather等同步操作对抖动极其敏感,任何节点的延迟都会拖慢整个集群的进度。
第四是带宽缺口问题。计算能力的增长速度远超网络带宽的增长速度,两者之间存在三个数量级的差距,这一"内存墙"与"网络墙"问题亟待解决。
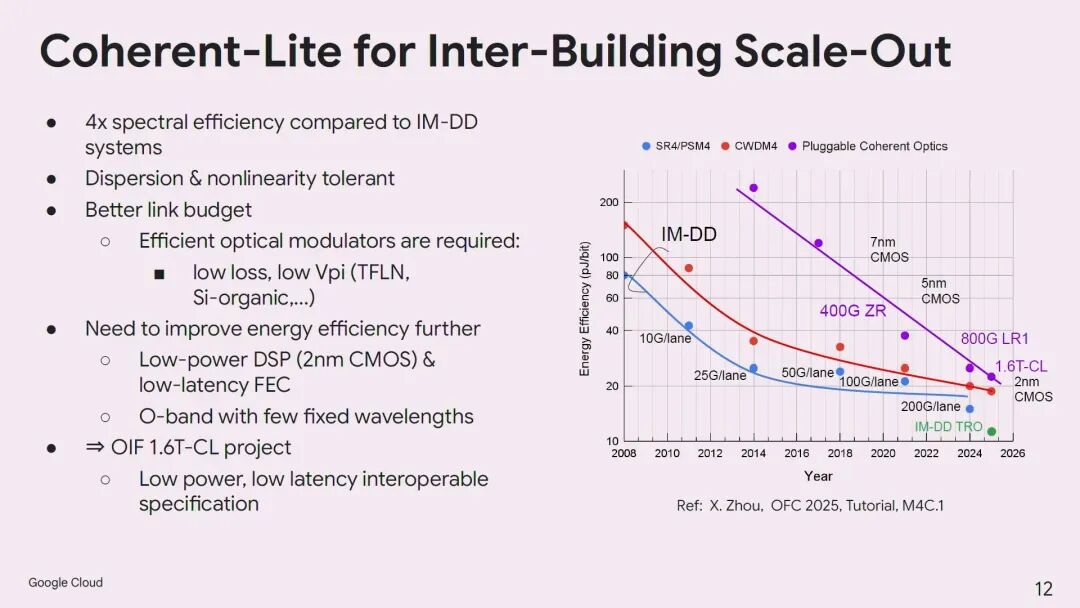
针对这些挑战,微软提出了四大技术方向:一是媒介转换器架构,将相干DSP与IMDD DSP集成在一起,省去高功耗的retimer芯片,提升长距离传输的能效;二是空芯光纤技术,其光在空气中传输的特性可降低33%的延迟,同时拥有更宽的低损耗窗口,支持O波段、C波段、L波段乃至T波段的传输,且不存在光纤非线性效应;三是光交换(OCS)技术,用于扩展交换容量,解决电交换芯片带宽增长不足的问题;四是共封装光学(CPO)技术,微软研究团队的microLED方案有望将能效提升至亚皮焦每比特级别。Yin同时强调,行业标准的统一是实现这些技术大规模落地的关键,包括400ZR、1.6T CL以及新兴的XPO、OCI等MSA联盟都在推动这一进程。
◆ 谷歌:园区内Scale Across的特殊需求与1.6T Coherent-Lite技术

谷歌平台基础设施工程团队的Tad Hofmeister分享了谷歌在AI集群互联上的实践与思考。他首先区分了谷歌两类AI集群的Scale-Up架构:基于英伟达GPU的集群采用NVLink交换机实现Scale-Up,目前单个Scale-Up域可支持72个节点,未来将向144、288节点演进;而谷歌自研的TPU集群则采用3D Torus拓扑,以64节点为一个立方体单元,通过光交换连接144个立方体,单个Ironwood TPU Superpod可支持9216个节点。
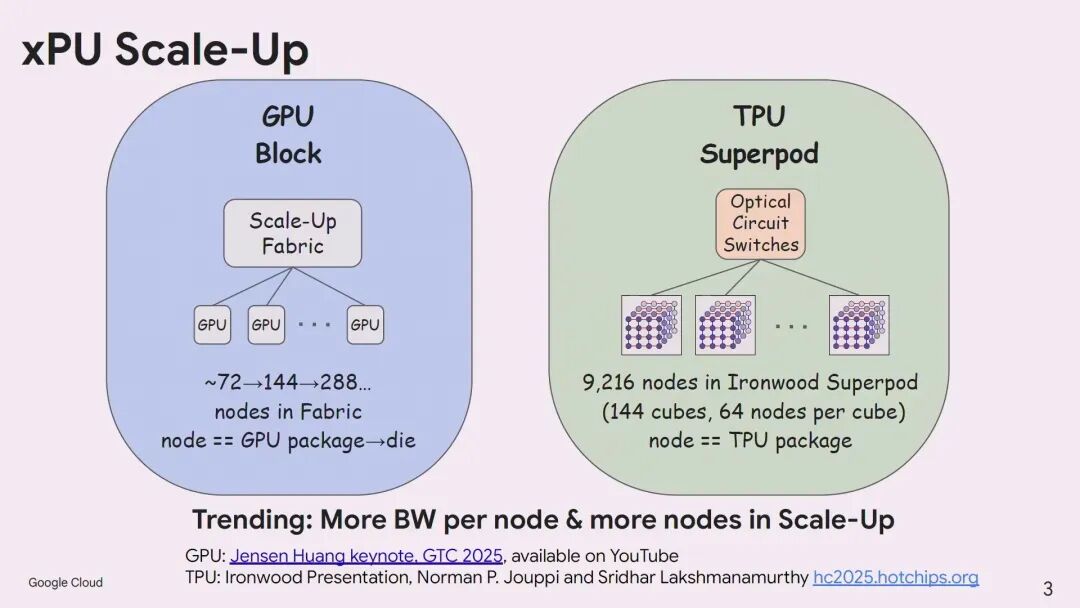
无论是GPU还是TPU集群,都呈现出"单节点带宽提升+集群节点数增加"的双重趋势,这驱动了Scale-Out网络的需求。而单栋数据中心建筑的电力与空间容量存在物理极限,因此必须将大型AI集群分散部署在同一园区的多栋建筑中,这就产生了谷歌定义的"园区内Scale Across"——即跨楼的点对点Scale-Out互联。
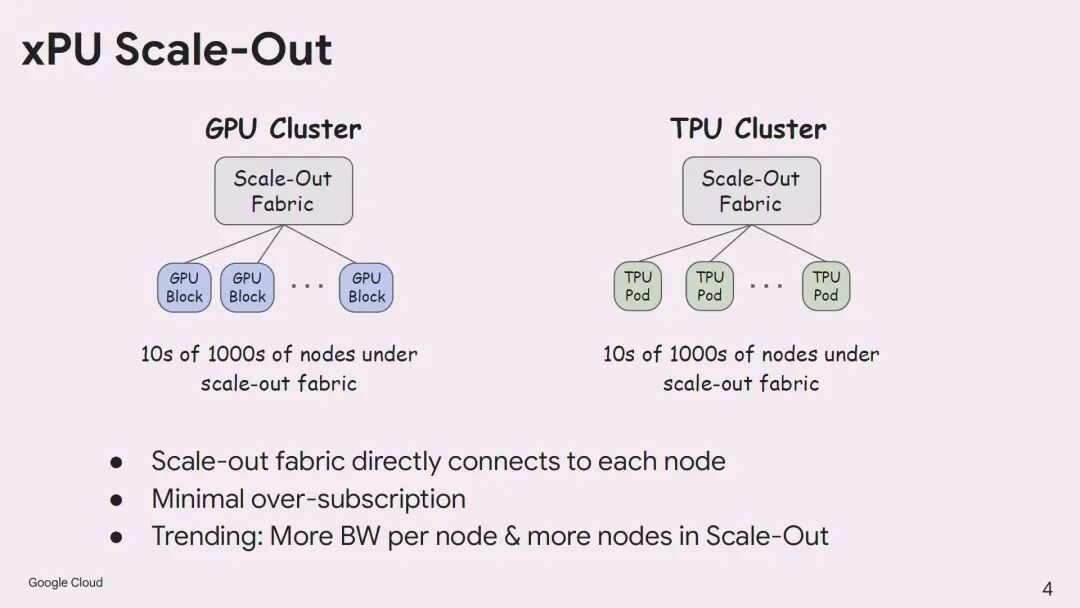

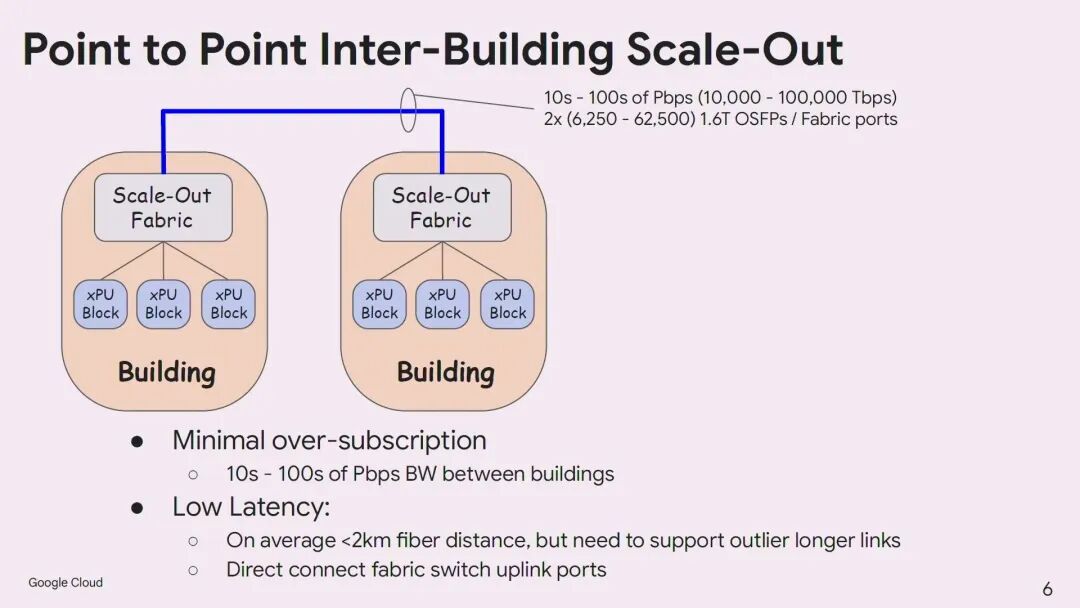
这种互联有着极其严苛的要求:跨楼带宽需要达到数十到数百Pbps级别,对应数万乃至数十万个1.6T光模块端口;平均光纤距离小于2公里,但需要支持部分更长的链路;必须尽可能减少中间交换层,以降低延迟、功耗和成本。传统的IMDD技术在400G以上速率时传输距离受限,无法满足需求;而标准的ZR/ZR+光模块功耗过高,无法满配在Scale-Out交换机端口上,且其高增益FEC会引入额外延迟。
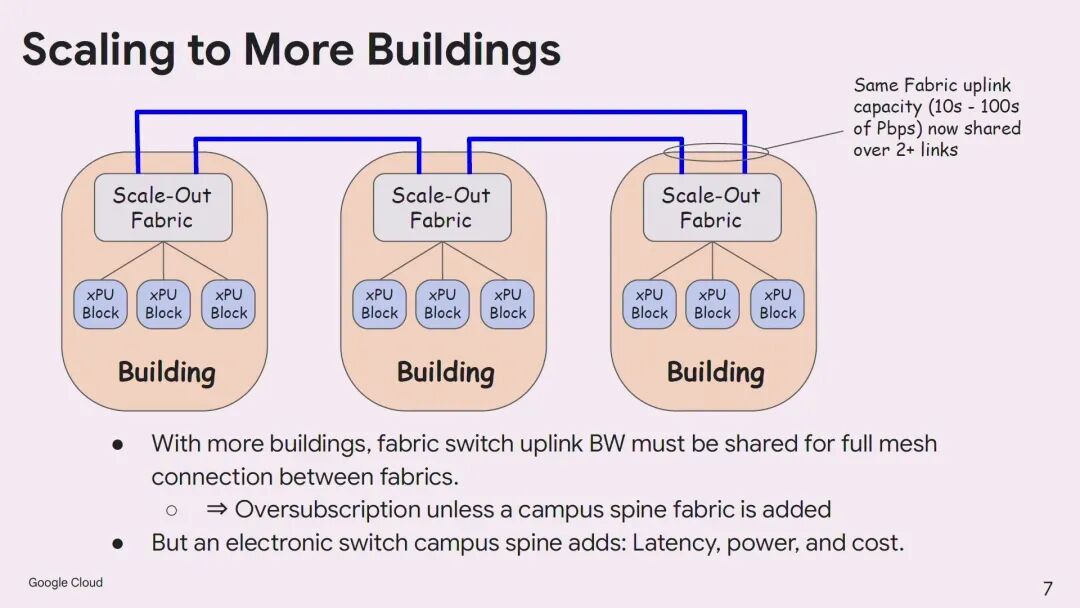
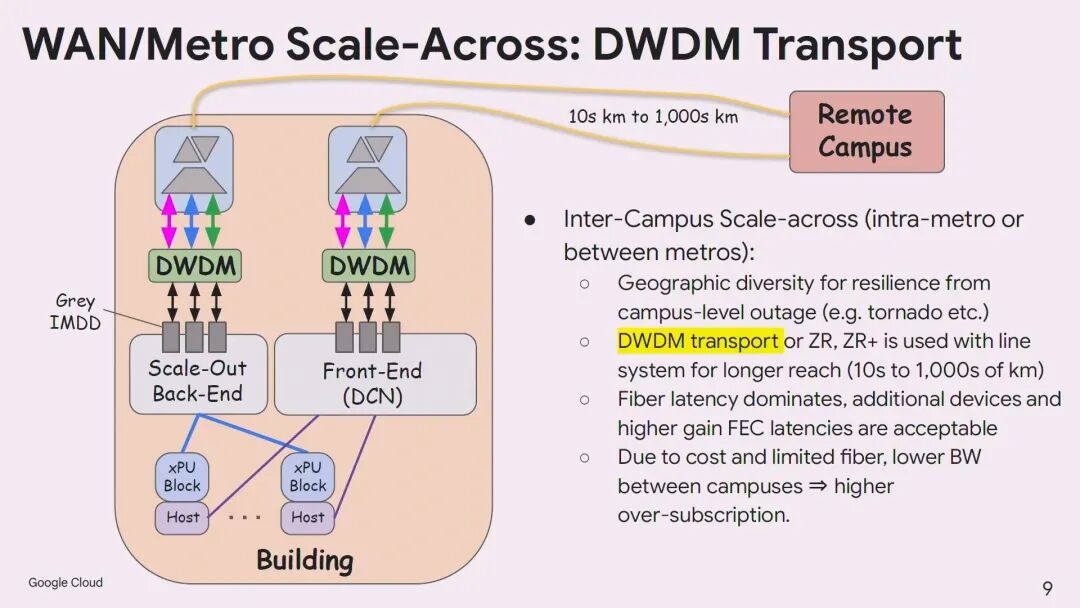
为此,谷歌提出1.6T Coherent-Lite(CL)技术作为园区内Scale Across的理想解决方案。与标准相干技术相比,1.6T CL采用低延迟FEC,O波段传输以降低色散,功耗大幅降低,可实现Scale-Out交换机端口的满配;同时其频谱效率是IMDD的4倍,可通过无源复用器实现8、16乃至更多信道的复用,大幅减少光纤和OCS端口的数量。
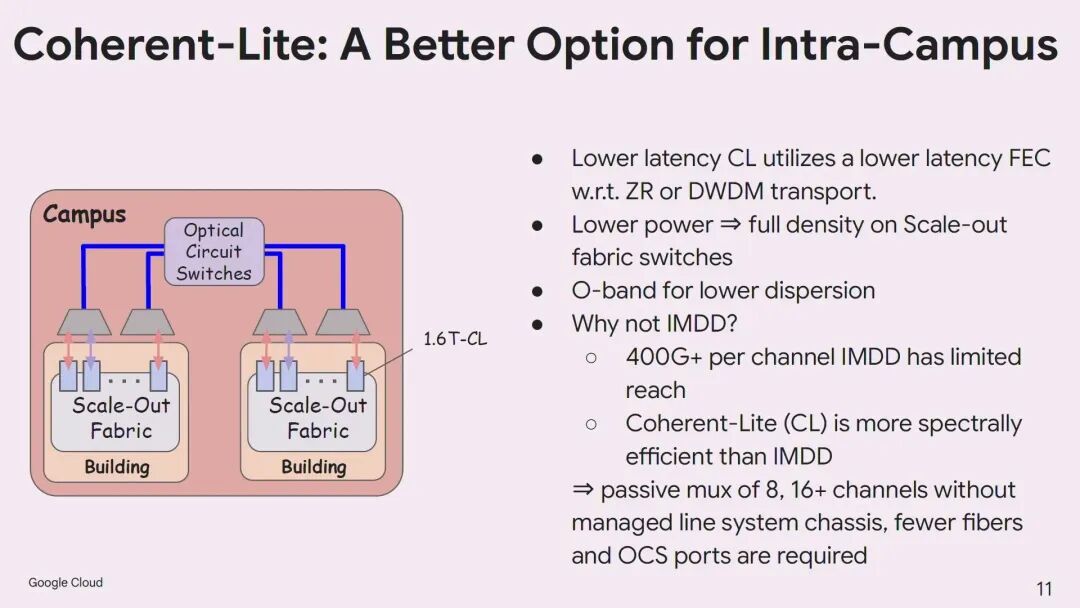
Tad Hofmeister指出,2nm CMOS工艺的低功耗DSP以及薄膜铌酸锂(TFLN)、硅有机聚合物等低损耗、低驱动电压的新型调制器,是实现1.6T CL的关键技术基础。此外,光交换(OCS)在多楼互联中也发挥着重要作用,可实现动态带宽分配,支持园区的分阶段建设与扩容。

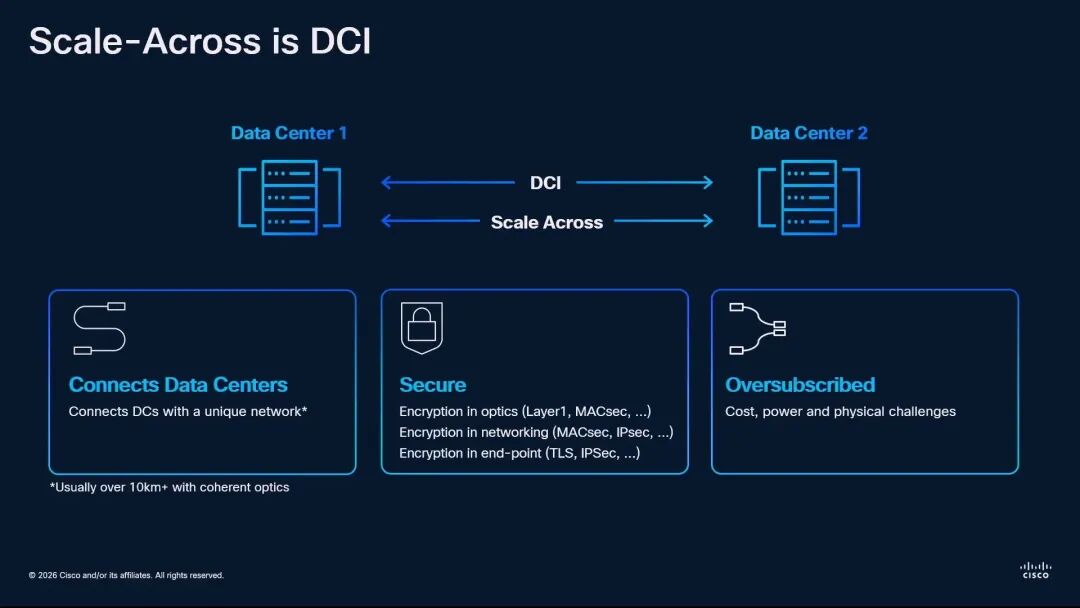
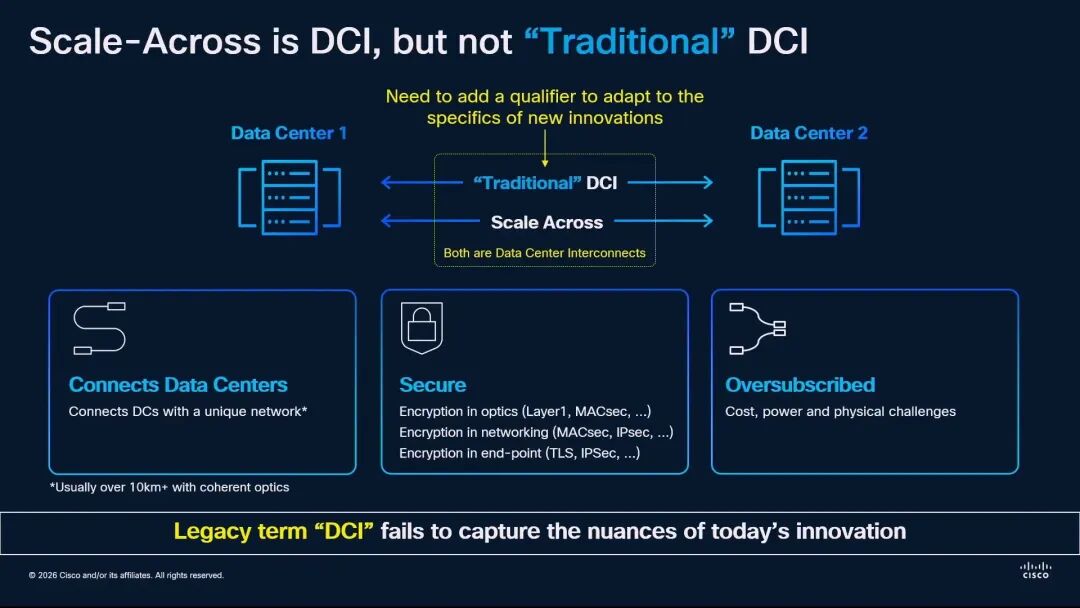
◆ 思科:重新定义Scale Across,与传统DCI的本质区别

思科硬件架构高级副总裁兼院士Rakesh Chopra从系统架构的角度,首次清晰界定了Scale Across与传统数据中心互联(DCI)的区别。他首先量化了AI时代的网络带宽层级:传统DCI的带宽基准为1,前端网络是其7倍,Scale-Up网络是其504倍,Scale-Out网络是其56倍,而Scale-Across网络是其14倍。
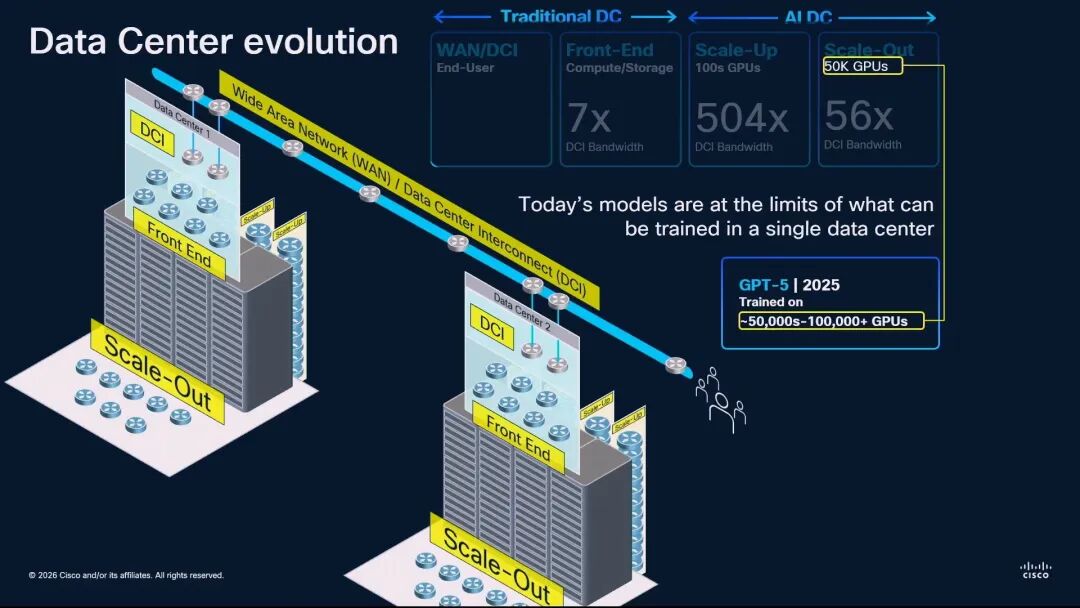
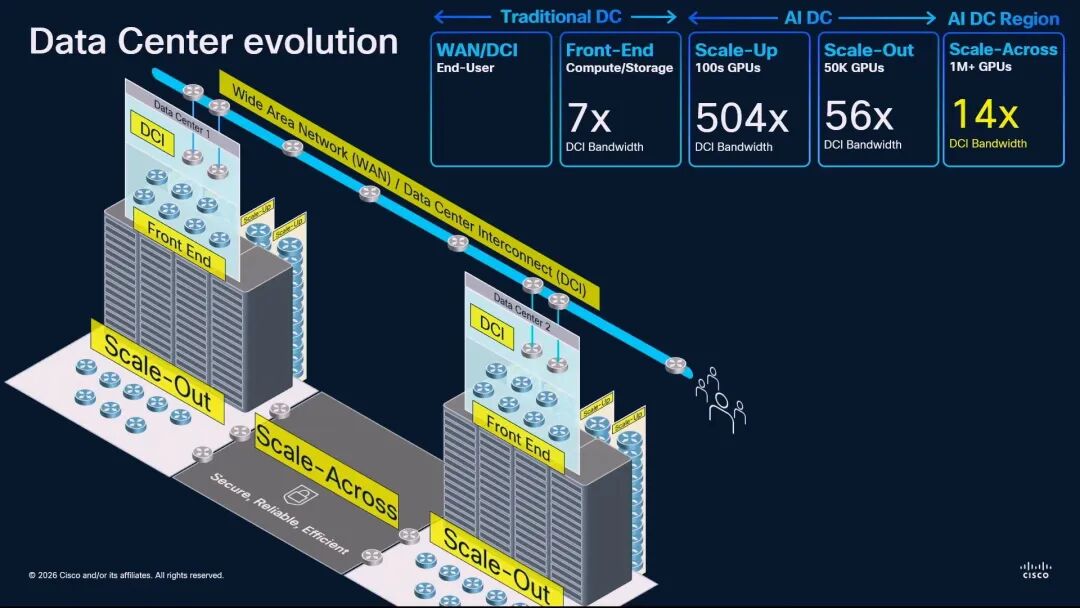
Rakesh Chopra指出,传统DCI与Scale Across虽然都用于连接数据中心,且通常采用10公里以上的相干光技术,但两者在本质上是完全不同的网络:
- 连接对象不同:传统DCI连接的是前端网络中的CPU、存储和终端用户,而Scale Across连接的是后端Scale-Out网络中的GPU/XPU;
- 流量特征不同:传统DCI承载大量低带宽、异步、对丢包相对容忍的流量,而Scale Across承载少量高带宽、同步、对丢包极其敏感的长生命周期流量;
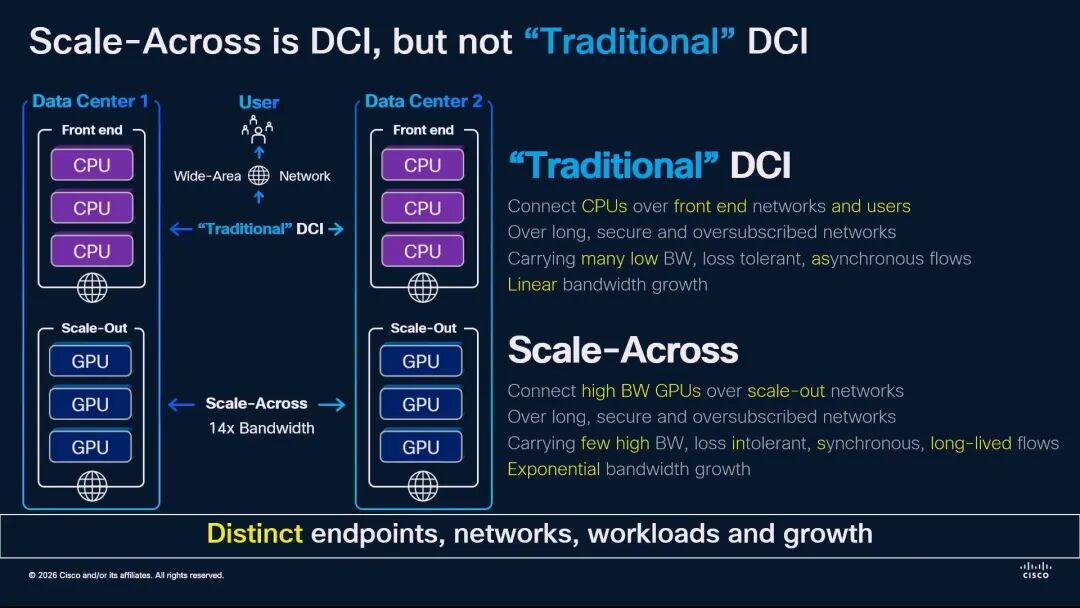
- 增长模式不同:传统DCI的带宽呈线性增长,而Scale Across的带宽呈指数级增长。
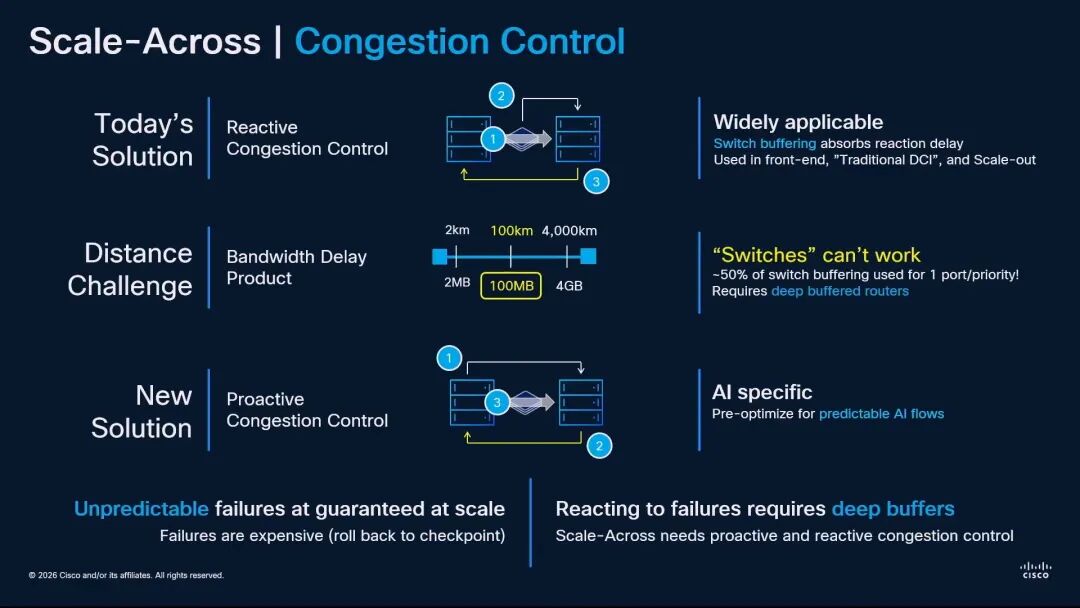
基于这些差异,Scale Across面临着传统DCI从未遇到过的技术挑战。首先是拥塞控制问题:长距离传输的带宽延迟积使得传统的反应式拥塞控制完全失效,100公里链路的在途流量约为100MB,相当于现代交换机单个端口一半的缓冲容量。因此,Scale Across需要采用针对AI工作负载优化的主动式拥塞控制,在流量发送前就预判并规避拥塞;同时必须配备深度缓冲路由器,以应对不可避免的链路故障,避免训练任务大规模回滚。

其次是带宽与端口密度问题。传统DCI每个数据中心的出口端口数约为1000-2000个,而Scale Across需要12000-32000个端口,这将带来相干光模块的爆发式需求。同时,为了降低功耗和成本,Scale Across网络不能采用传统的大型模块化机箱,而应采用与数据中心内部类似的分布式固定盒架构。

最后,Rakesh Chopra特别强调了可靠性的极端重要性。Meta的数据显示,单个GPU或网络链路的故障,可能导致整个集群的性能下降40%。因此,光模块和网络设备的可靠性必须从设计阶段就作为核心指标,而非事后考虑的因素。

◆ Arista:XPO超密度光模块,Scale Across的硬件基石
Arista负责超大规模客户工程的VJ Vusriala最后分享了Arista对Scale Across网络的系统设计思考,并重点介绍了论坛前刚刚发布的XPO(eXtra-Dense Pluggable)超密度可插拔光模块标准。
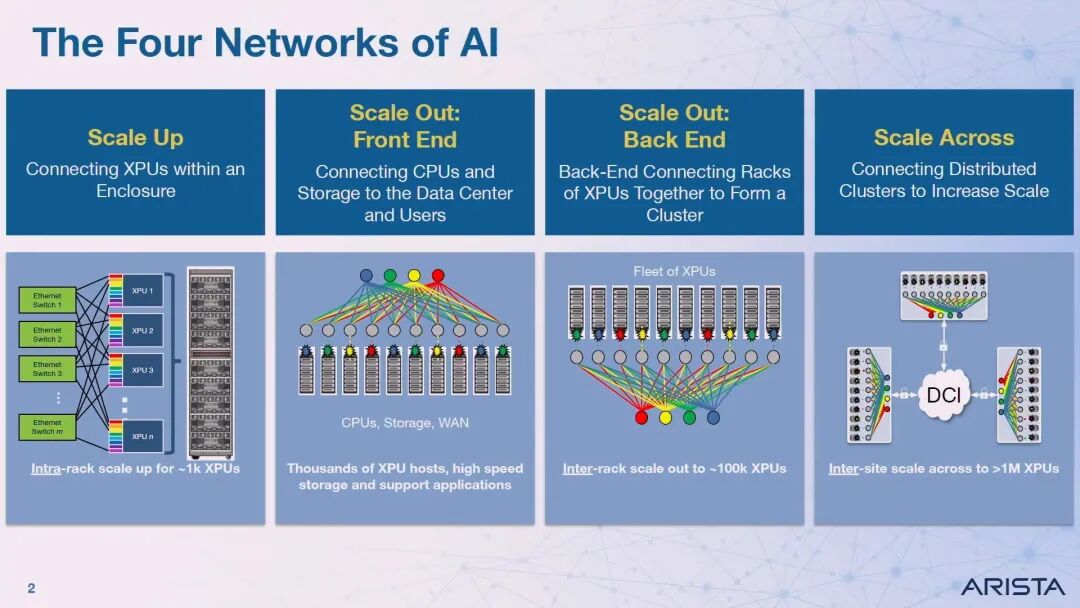
VJ Vusriala首先提出了AI时代的四大网络层级:第一层级是Scale-Up,实现机箱内约1000颗XPU的互联;第二层级是前端Scale-Out,连接CPU、存储和终端用户;第三层级是后端Scale-Out,实现机架间约10万颗XPU的互联;第四层级就是Scale-Across,实现跨站点超过100万颗XPU的互联。

他进一步对比了Scale Across与传统DCI的核心差异:Scale Across的端口需求量是传统DCI的10倍,因此对成本和部署效率的要求更高;由于功耗密度极高,Scale Across将比传统DCI更早采用液冷技术;对系统级可靠性的要求大幅提升,因为它本质上是GPU集群的互联 fabric;光技术覆盖范围更广,包括园区内的Coherent-Lite、城域的ZR以及长距离的ZR+;同时采用多轨架构,光纤成为新的"波长"资源。
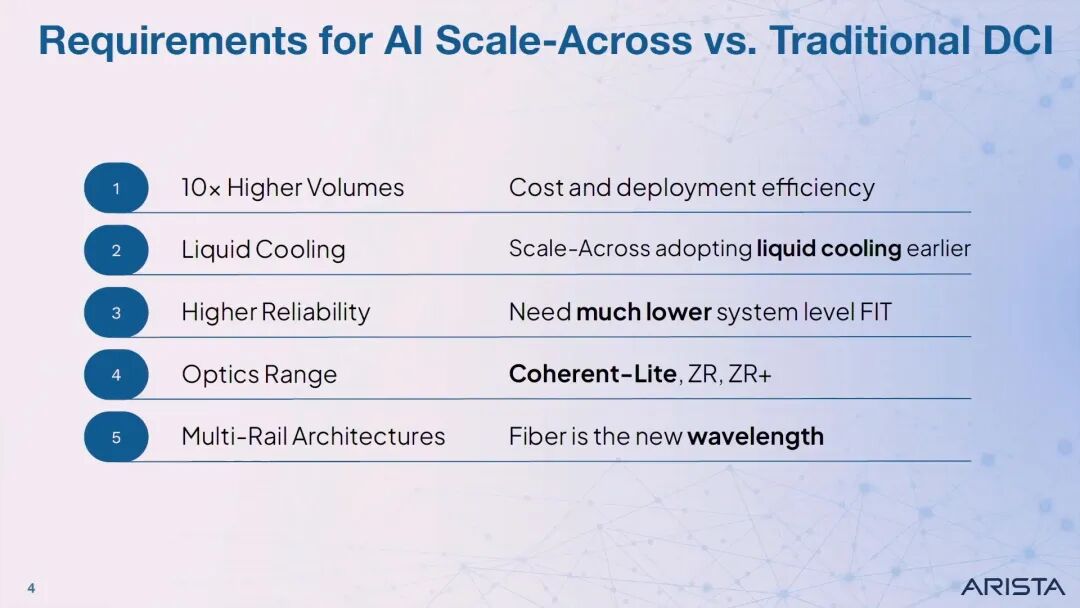
为了满足这些需求,Arista联合行业伙伴推出了XPO MSA标准。XPO光模块拥有64个通道,每个通道支持200G速率,总容量达到12.8T,是当前主流OSFP模块的8倍。在面板密度上,XPO实现了4倍的提升:原来需要40U机架空间部署的128个1.6T OSFP端口,现在仅需10U即可实现,单个ORv3机架可支持32个1U AI交换机,总容量达到6.4Pbps。

XPO最核心的优势在于其原生液冷设计,可支持最高400W的热功耗,能够无妥协地承载任何相干光模块。同时,液冷带来的20-25℃工作温度降低,加上组件数量的大幅减少,使得XPO模块的可靠性比OSFP提升了6-8倍。此外,XPO的大尺寸设计支持多通道集成,可实现固定激光的半带转发器,仅需2个SKU即可覆盖整个C波段,4个SKU覆盖C+L波段,大幅降低了供应链复杂度和成本。VJ Vusriala展示了Ciena的12.8T Coherent-Lite XPO和12.8T ZR/ZR+ XPO概念设计,证明了XPO作为统一光模块平台的可行性。



◆ 论坛Q&A:行业共识与未来展望
在随后的问答环节,五位嘉宾就行业关心的问题进行了深入讨论,达成了多项重要共识:
1. 术语定义:行业正在逐步形成统一认知,Scale Across本质上是跨地理区域的Scale-Out网络互联,用于连接多个分布式AI集群,突破单数据中心的算力极限。
2. 未来架构:不会出现完全统一的全局互联架构,而是会继续保持分层优化的模式,不同层级的网络根据距离、带宽、延迟和成本的需求,采用不同的技术路线。
3. 技术路线:光交换(OCS)将在Scale Across中发挥重要作用,用于扩展交换容量和实现动态带宽分配,但不会完全取代电交换,两者将长期共存互补。
4. 供应链与标准:统一的行业标准是Scale Across大规模落地的前提,XPO、1.6T CL等新兴标准需要产业链上下游的共同参与和推动,才能实现成本的快速下降。
本次论坛清晰地展现了AI算力从单数据中心向分布式集群演进的必然趋势,而Scale Across网络正是这一演进的核心支撑。光互联技术作为Scale Across的基石,正在经历从速率提升到架构创新的全面变革,Coherent-Lite、XPO、空芯光纤等新技术的成熟,将推动人类向百万级GPU的超大规模AI训练时代迈进。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号