面向 DeepSeek-V4 的 FlashMemory:长上下文 KV Cache 如何压到约十分之一
原创
面向 DeepSeek-V4 的 FlashMemory:长上下文 KV Cache 如何压到约十分之一
原创
七牛开发者
发布于 2026-06-15 14:02:01
发布于 2026-06-15 14:02:01
长上下文模型的能力越来越强,能读的内容也越来越长。但一到真实推理服务里,问题很快就会落到显存上。更准确地说,是 KV Cache。
在大模型自回归生成过程中,模型每生成一个 token,都需要参考此前已经读过的上下文。为了避免每一步都重新计算历史内容,推理系统会把历史 token 对应的 Key 和 Value 缓存下来。上下文越长,这部分缓存就越大。到了 128K、500K 甚至更长的上下文,KV Cache 往往会成为长上下文服务里最沉重的一笔显存开销。
「FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention」这篇论文讨论的,就是如何继续压缩这笔显存账。
结果先行:KV Cache 压到约 1/10
论文提出了一个面向 DeepSeek-V4 的方案:FlashMemory-DeepSeek-V4。它的核心机制叫 Lookahead Sparse Attention,简称 LSA。它想让模型在生成过程中学会“提前判断”:接下来到底需要回忆哪一部分历史上下文,然后只把真正可能用到的 KV chunk 拉回 GPU。
论文给出的结果很抓眼:在 LongBench-v2、LongMemEval、RULER 等长上下文评测上,FlashMemory 把平均物理 KV Cache 占用压到了 full-context baseline 的 13.5%。换句话说,平均来看,它把 KV Cache 压到了原来的约 1/7;而在 256K、512K 这类更长上下文下,KV Cache 开销已经接近压到原来的 1/10。
同时,论文也报告称,FlashMemory 在整体平均准确率上比 DeepSeek-V4-Flash 高了 0.6 个百分点。
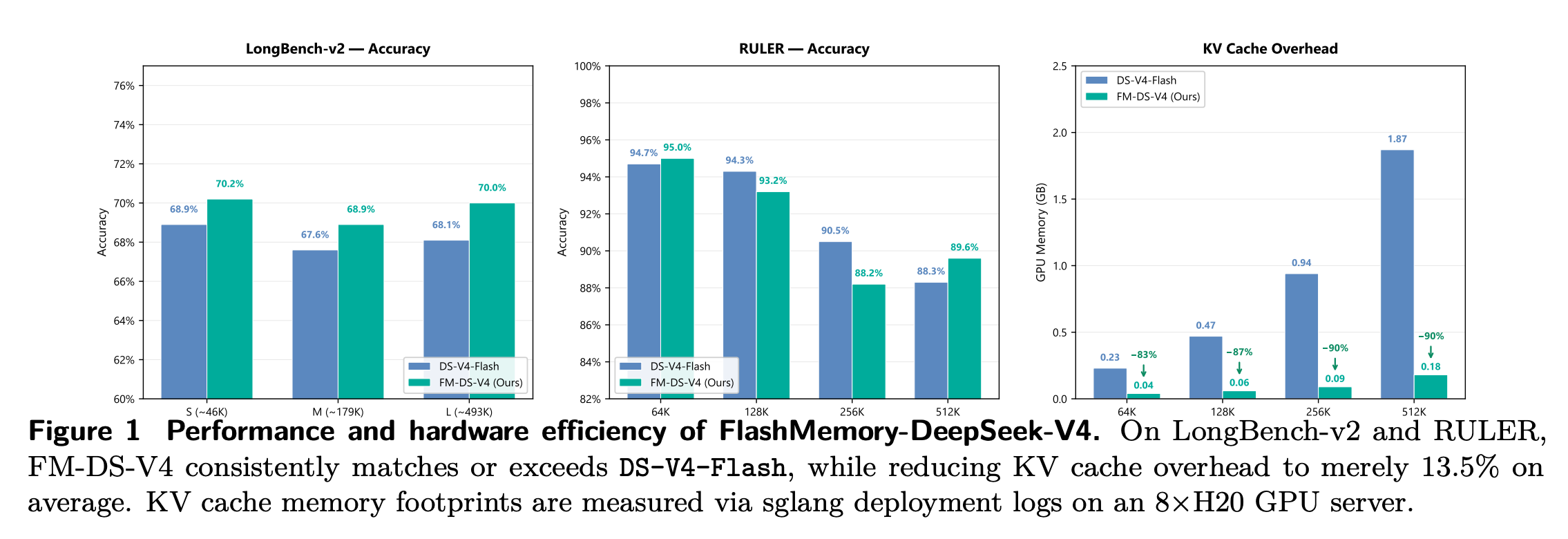
图注:FlashMemory-DeepSeek-V4 的性能与硬件效率总览
上图是论文最核心的结果图。左侧是 LongBench-v2 的表现,FlashMemory 在 S、M、L 三个长度档位上都优于 DeepSeek-V4-Flash。尤其是在接近 493K 的 LongBench-v2-L 上,准确率从 68.1% 提升到 70.0%。中间是 RULER 的结果,这里可以看到 FlashMemory 并没有在每个长度上都全面领先:在 128K、256K 上,它会略低一些;但在 64K 和 512K 上,它又分别达到 95.0% 和 89.6%,都高于 DeepSeek-V4-Flash。
右侧是最关键的 KV Cache Overhead。在 64K / 128K / 256K / 512K 四个长度上,FlashMemory 的显存开销大约是 0.04GB / 0.06GB / 0.09GB / 0.18GB,而 DeepSeek-V4-Flash 对应大约是 0.23GB / 0.47GB / 0.94GB / 1.87GB。这个对比非常直观:上下文越长,FlashMemory 省下的显存越明显。到了 512K,它的 KV Cache 开销只有 baseline 的约 9.6%,也就是下降了约 90%。
长上下文的昂贵点
长上下文能力听起来很直接:模型能读更多 token,就能处理更长的文档、更大的代码仓库、更复杂的 Agent 轨迹。但工程上,问题会很快变得现实。模型读过的上下文不会凭空消失。推理时,系统要把历史 token 的 Key / Value 保存下来,后续每生成一个新 token,都可能继续用到这部分历史信息。
这就是 KV Cache。
对于 8K、32K 上下文,KV Cache 已经是显存成本里很重要的一部分。到了 128K、500K,甚至更高长度时,它会变成长上下文服务里最难绕开的成本。DeepSeek-V4 这类模型已经做了很多注意力层面的压缩设计,例如通过分层、稀疏和压缩机制减少计算量。但论文指出,即使注意力计算已经被优化,KV Cache 的显存开销依然会随着上下文长度增长。
换句话说,模型已经变得更会“省着算”,但还需要进一步学会“省着存”。
FlashMemory 的出发点就来自这里。论文作者观察到,在大量长上下文请求里,很多时候模型并不真的需要调用完整历史。超过 90% 的 64K 以上上下文请求,仅靠最后 8K token 就能完成。这说明很多历史 KV 在当前生成步骤里,其实只是占着显存,并没有真正参与预测。
当然,历史信息也不能简单丢掉。有些任务确实依赖远距离上下文,比如从很长的文档里找前后分散的证据、处理跨越几十万 token 的记忆检索,或者在长代码库里追踪某个接口的定义和调用。对于这些任务,只看最近窗口会明显不够。
所以 FlashMemory 面对的问题很明确:能不能把大部分历史 KV 放在更便宜的位置,只在需要的时候,把真正关键的部分提前取回 GPU?
LSA 让模型预判 KV chunk
FlashMemory-DeepSeek-V4 的核心机制叫 Lookahead Sparse Attention。这里最重要的词是 Lookahead。它并不等到模型生成到某一步才临时发现需要历史信息,而是提前预测:在接下来一小段 decoding window 里,哪些历史 KV chunk 可能会被用到。
整个机制可以拆成三个环节。首先,大量历史 KV 不再默认长期留在 GPU 上。FlashMemory 会把历史 KV 放到 CPU 侧的 Cold Pool 里,GPU 主要保留最近窗口、本地必要 KV,以及被判定为当前生成真正需要的历史 KV。其次,系统引入一个 Neural Memory Indexer。这个 Indexer 会根据当前 token 的 hidden state,预测未来一段生成可能会用到哪些历史 chunk。最后,只有被判定为重要的 chunk,才会被召回 GPU。这些被召回的 KV 会参与后续 attention 计算,其余暂时无关的历史信息继续留在 CPU 侧。
这样一来,KV Cache 的管理方式就发生了变化。过去是完整历史常驻 GPU,FlashMemory 则变成了关键历史按需召回。
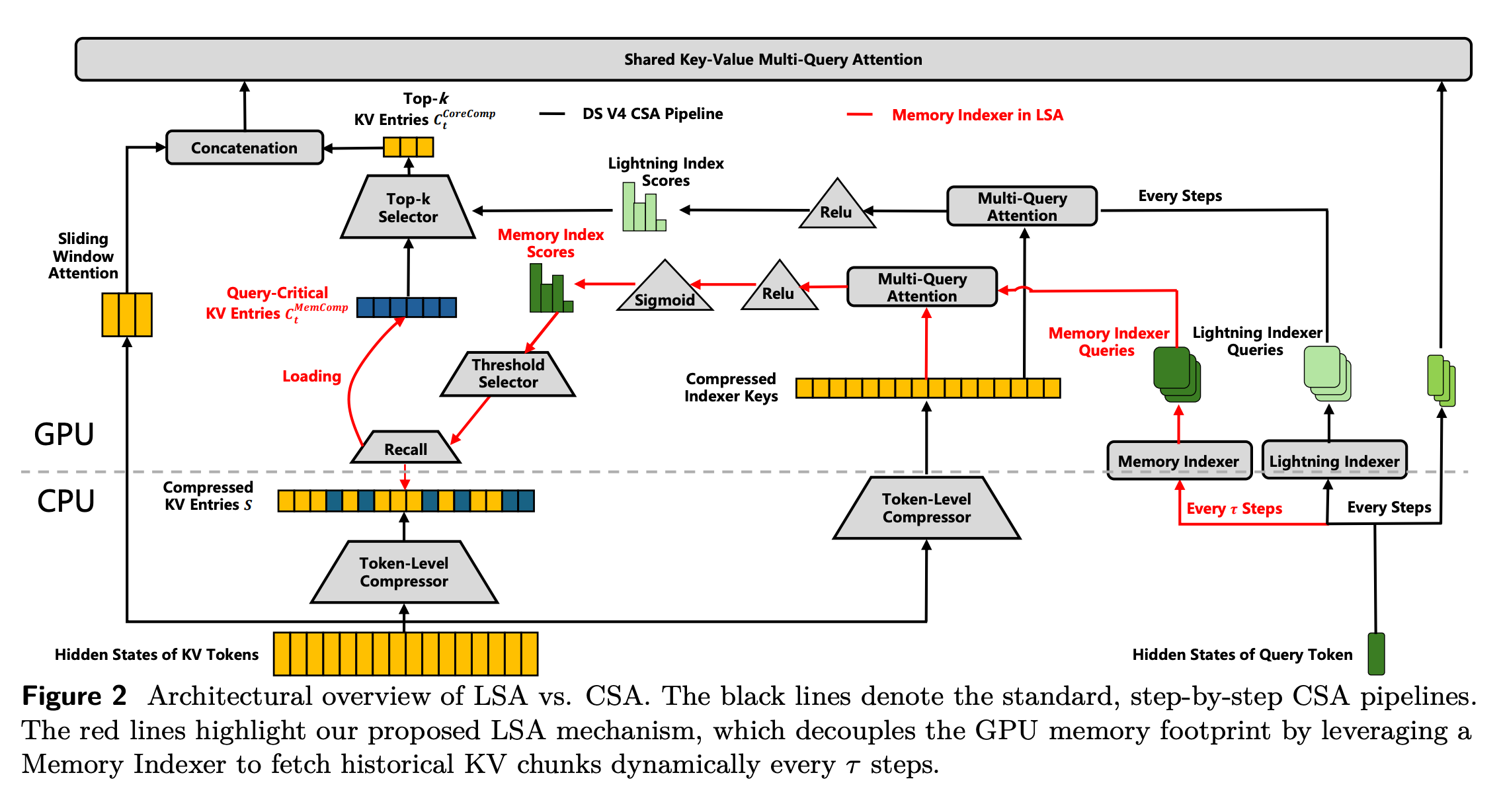
图注:LSA 与原始 CSA 的架构对比
上图为整篇论文最重要的机制图。黑色路径对应 DeepSeek-V4 原本的 CSA pipeline,红色路径对应 FlashMemory 新增的 LSA / Memory Indexer 机制。
这张图最关键的地方,是画出了 CPU 和 GPU 的分层。历史压缩 KV entries 可以存放在 CPU 侧,GPU 侧只保留 sliding window attention、本地窗口 KV,以及被召回的 query-critical KV entries。右侧的 Memory Indexer 会周期性触发,它根据 query token 的 hidden state 生成 Memory Indexer Queries,再去匹配 compressed indexer keys。左侧的 Recall / Threshold Selector 负责决定哪些历史 entries 应该被拉回 GPU。
这里有一个值得注意的设计:FlashMemory 没有简单使用固定 Top-k,而是通过 Sigmoid 分数和阈值判断,把超过阈值的历史 KV entries 召回。这样召回数量就可以更灵活。如果某一段生成确实需要更多历史,系统可以多取一点;如果当前生成只依赖最近上下文,系统就可以少取很多。
可检索的 KV Cache
FlashMemory 这篇论文有意思的地方,不只在于显存压缩数字。它真正有启发的地方,是把 KV Cache 管理做成了一个检索问题。
在直觉上,如果想让模型学会判断“哪些历史上下文重要”,很容易想到端到端训练:把整个大模型连同 Indexer 一起训练,让它自己学会保留和召回。但这样做的成本非常高,工程负担也很重。
FlashMemory 选择了一个更轻量的方案:把 Memory Indexer 做成一个独立的 dual-encoder 检索器。具体来说,历史侧的 compressed indexer keys 会提前离线抽取并冻结。训练时主要学习 query 这一侧的 encoder,让它根据当前 hidden state,去预测未来窗口里需要哪些历史 chunk。
这样做的好处很明显:训练 Memory Indexer 时,不需要把完整的大模型 backbone 加载进 GPU。论文里提到,Memory Indexer 可以在单张 H20 GPU 上约 1 小时内收敛。作者还使用 8 张 H20 GPU,在一周内完成了大约 500 次训练,用来搜索更合适的结构和训练策略。
这是一条很工程化的路线。它没有把所有东西都压到一次巨大的端到端训练里,而是把长上下文推理里的“记忆调度”拆了出来,做成一个可以独立训练、独立迭代的模块。
训练标签的选择
Memory Indexer 要训练,就需要知道:某个生成时刻,未来真正需要哪些历史 chunk?
最直接的办法,是去看原始 Lightning Indexer 或 CSA 层在未来窗口里选择了哪些 Top-k 历史条目。但论文发现,这种做法会产生大量噪声。原因也很简单:固定 Top-k 会强行选满。即使某些历史 chunk 相关性并不强,它们也可能因为排名靠前而被当成正样本。
论文里提到,朴素做法会让每个 token window 产生接近 10,000 个正样本。经过过滤之后,数量会下降到大约 100 到 1,000 个。作者使用的办法叫 Cross-Layer Majority Voting。
可以把它理解成三步。第一步,对不同 CSA 层的原始 indexer logit 做归一化,让不同层的分数更可比较。第二步,使用类似 nucleus threshold 的方法,只保留高置信度条目。第三步,看多个 layer 是否共同选择了同一个历史 entry。只有获得足够多层共识的 entry,才会被标记为 golden entry。
这一步很关键。FlashMemory 的目标并不是随便删掉 90% 的历史 KV,而是尽可能找出真正有价值的那一小部分历史记忆。换句话说,重点在于“看对”。
Memory Indexer 放哪里
论文还讨论了一个很重要的工程取舍:Memory Indexer 应该放在哪些层?
作者没有把 Indexer 塞进所有层里。浅层表示通常更偏向低级 token 统计,对于长距离语义依赖的判断并不理想;如果 Indexer 放得太多,又会导致召回结果过松,拉回 GPU 的历史 chunk 变多,显存节省效果被削弱。
最终,论文选择在 第 10、12、20 层 放置 Memory Indexer。推理时,这 3 个 Indexer 使用 OR-mode routing 聚合结果。只要其中一个 Indexer 判断某个历史 chunk 重要,这个 chunk 就会被召回。
这是一个偏稳妥的选择。它会牺牲一点极致压缩率,但可以降低漏掉关键上下文的风险。对于长上下文任务来说,漏召回往往比多召回更危险。
实验结果
论文主要比较了四种方案:标准 DeepSeek-V4-Flash,也就是全量 KV Cache baseline;加入 Memory Indexer 的 FlashMemory 版本 FM-DS-V4;只保留最近 8K 和解码窗口的 Recency Only;以及随机保留 10% 全局历史 CSA chunks 的 Random 10%。
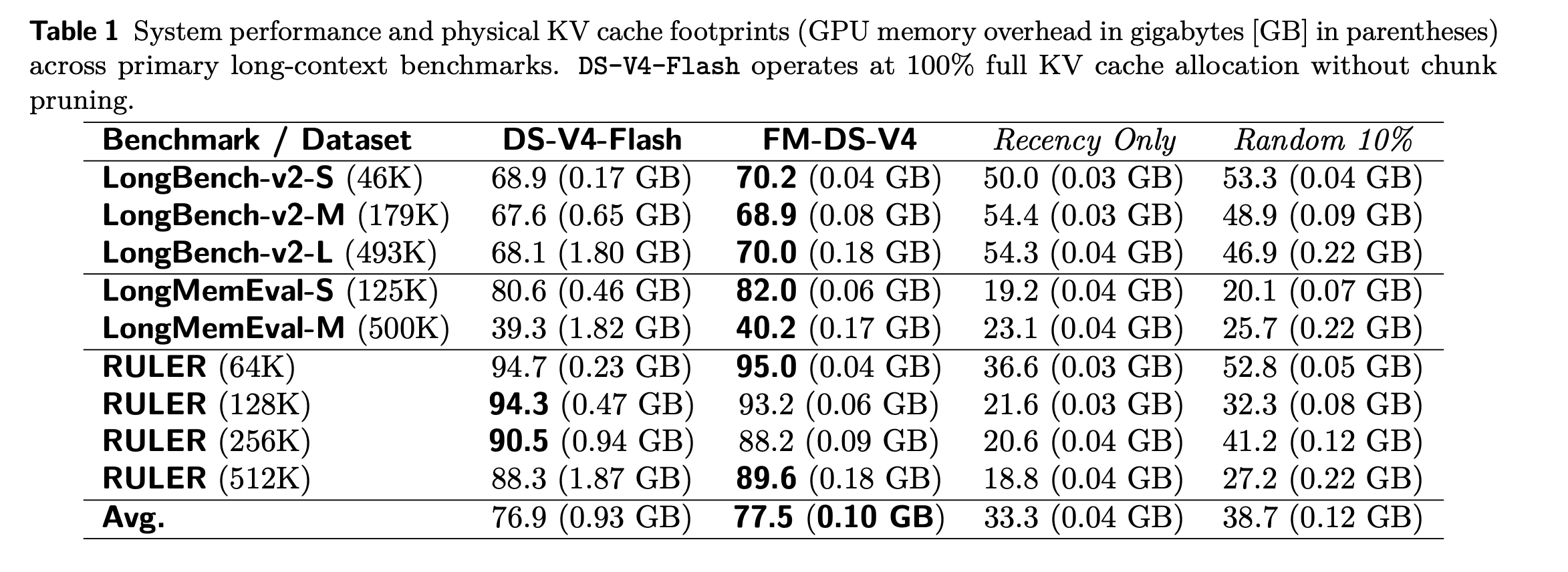
表 1:不同方案在主要长上下文评测中的系统性能与物理 KV Cache 占用
实验覆盖 LongBench-v2、LongMemEval 和 RULER。从表 1 可以看到,FM-DS-V4 的平均准确率是 77.5,略高于 DS-V4-Flash 的 76.9;同时,平均 GPU memory overhead 从 0.93GB 降到了 0.10GB。
这个结果可以拆成两层来看。第一,FlashMemory 确实把显存开销降下来了。从 0.93GB 到 0.10GB,平均 KV Cache 开销大约只有 baseline 的 10.8%,这也是“压到约 1/10”的核心依据。第二,它没有用明显性能损失来换显存节省。平均准确率反而略高 0.6 个百分点。
对比另外两个 baseline,更能看出 Memory Indexer 的价值。Recency Only 的平均准确率只有 33.3,说明只保留最近窗口完全不够,很多长上下文任务确实需要远距离历史信息。Random 10% 的平均准确率是 38.7,说明随机保留一部分历史 KV 也不够。关键在于,系统必须知道哪些历史 KV 真正可能在后续生成中被用到。
FlashMemory 的优势就在这里。它并不是单纯减少缓存,而是让模型提前预测:接下来真正可能用到哪些历史 KV。
更少上下文带来的准确率提升
这篇论文里还有一个挺有意思的现象:FlashMemory 在部分任务上不仅更省显存,准确率还更高。比如 LongBench-v2-L,DeepSeek-V4-Flash 的准确率是 68.1%,FlashMemory 提升到了 70.0%。
这个现象有点反直觉。按常规理解,模型能看到的历史越完整,信息应该越充分。但长上下文里有大量无关内容,它们进入 attention 之后,可能会稀释真正重要的信息,甚至干扰模型判断。
论文作者把 FlashMemory 的这种效果称为 attention denoiser。也就是说,Memory Indexer 在召回历史 KV 的同时,也起到了一层过滤噪声的作用。模型少看了一些无关历史,反而更容易聚焦到真正相关的上下文上。
这也是 FlashMemory 比较有意思的地方。它带来的收益不只是节省显存,也可能改善长上下文 attention 的质量。
局限性:密集记忆任务与长度泛化
FlashMemory 的结果很亮眼,但它的边界也比较清楚。论文里主要暴露出两类限制:一类来自任务本身,另一类来自上下文长度泛化。
MRCR:密集全局记忆下的失败案例
论文在 MRCR(Multi-Range Context Retrieval) 上记录了一个明显失败案例:FM-DS-V4 的准确率从 baseline 的 76.0% 掉到了 48.0%。
为了判断问题出在哪里,作者又做了一组 oracle simulation。他们先用 DS-V4-Flash 的完整解码路径,为每个样本预先计算全局 golden attention weights;然后按照累计 attention density 对历史 blocks 排序,只加载 Top 50%、25% 或 10% 的高权重 chunks 到核心 MQA 层里。
结果显示,在 LongBench-v2、LongMemEval 和 RULER 上,只保留 10% 或 25% 的 golden CSA chunks,再配合全局 HCA layers,就足以维持 baseline 的完整准确率。但 MRCR 不一样,即使提供 50% 由 oracle 预先确认的高权重 chunks,准确率仍然比 full-context cache 低约 2%。
这说明 MRCR 对全局、密集、分散的历史记忆依赖更强。它需要更高覆盖率的全局记忆。对于这种任务,只靠轻量的 dual-encoder Memory Indexer,很难把所有关键上下文召回完整。
论文也总结了几个限制。第一,历史 key 表示是冻结的,当前主要训练 query 这一侧,历史侧表示没有一起联动优化。第二,检索交互能力还比较有限,现有方案主要依赖粗粒度点积相似度,未来可能需要更强的 late interaction 结构,例如类似 ColBERT 的方式。第三,Memory Indexer 和 backbone 是解耦训练的,这种方式训练成本更低、工程上更灵活,但它也缺少端到端联合优化,对自回归生成过程中的动态分布适应还不够完整。
512K 训练长度之外的泛化问题
论文里还有一个很重要的观察:Memory Indexer 的长度泛化并没有想象中那么自然。
作者最初希望,既然 Indexer 做的是 point-wise chunk matching,那么在较短上下文上训练后,也许可以扩展到更长上下文。但实验结果并不乐观。论文发现,Indexer 基本只能安全泛化到训练长度范围内。一旦明显超过训练时见过的上下文长度,选择质量会退化,甚至接近随机。
作者认为,这和位置编码在超长范围下的分布外问题有关。所以,FlashMemory 的结果需要放在它的实验范围内理解。更准确地说,它是在论文覆盖的 benchmark 和 512K 量级上下文 中,把平均物理 KV Cache 压到了 13.5%,并在 500K 规模附近把 KV Cache 开销降低超过 90%。
这已经是一个很强的结果,但它并不自动意味着同样方法可以无损扩展到 1M、2M 或更长上下文。
整体来看,FlashMemory 已经证明了 LSA 在长上下文 KV Cache 压缩上的潜力。但在更密集、更复杂的全局记忆任务上,以及超过训练长度的上下文场景里,它还需要更强的召回机制和更完整的训练方式。
论文小结
FlashMemory-DeepSeek-V4 最值得关注的地方,是它把长上下文推理里的 KV Cache 管理,从“尽量塞进显存”推进到了“按需调度记忆”。
这条路线的意义在于,长上下文能力继续往前走,瓶颈不会只来自模型能读多长,也会来自系统能不能便宜、稳定地保存和调用这些历史信息。窗口变大只是第一步,真正难的是让模型知道哪些内容值得保留、什么时候该被召回。
从这个角度看,FlashMemory 更像是一次关于“模型记忆系统”的工程实验。它还有边界,但方向很清楚:未来的超长上下文模型,可能需要的不只是更大的 context window,还需要更聪明的记忆调度能力。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号