字节Java一面50题:考官真正想听到的答法


去年我在帮一个朋友做面试 mock,他已经背了三遍八股文,把 ThreadLocal 的原理、G1 的 Region 划分、MySQL MVCC 的版本链说得滚瓜烂熟。结果字节一面还是挂了。
面试官的反馈只有一句话:「基础知识点背得挺熟,但说不清楚为什么这样设计,也没有自己的判断。」
这就是字节一面和其他公司一面的本质差别。字节一面不是考你「背了多少」,考的是你「有没有想过为什么」。
这 50 道题是我整理了 2025-2026 年字节后端一面的真实面经,按六个知识域分类。每道题除了给答题要点,还会标注「考官想听到什么角度」——把问题放进这个框架里回答,命中率远高于背书式作答。

字节跳动Java后端一面六大模块考察全景
Java 并发:字节考得最深的模块
大多数公司并发考到「synchronized 和 ReentrantLock 的区别」就结束了。字节会追问锁升级的具体条件、AQS 的等待队列实现、以及 ThreadLocal 在线程池场景下的内存泄漏是怎么发生的。
这个模块出现在超过 80% 的字节 Java 一面中,丢分也最多。
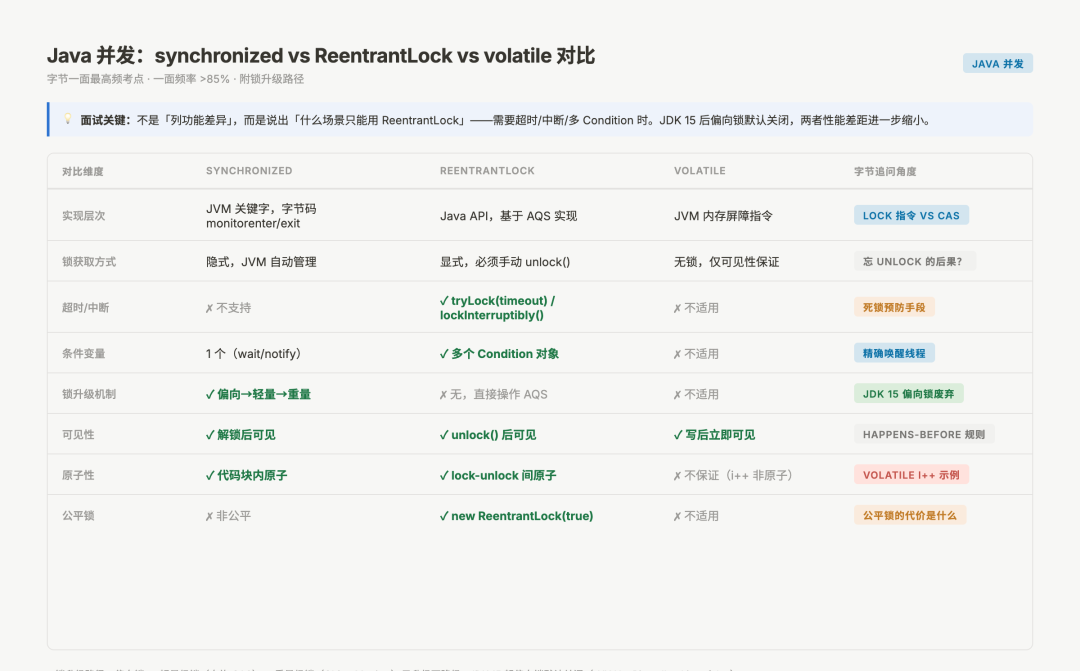
Java并发synchronized vs ReentrantLock vs volatile对比
Q1. synchronized 和 ReentrantLock 的核心区别是什么?
考官想听的角度:别只列功能差异,说出「什么场景下只能用 ReentrantLock」。
答题要点:
- synchronized 是 JVM 层的关键字,锁的获取/释放由 JVM 自动管理,不可中断、不支持超时、不能绑定多个条件变量
- ReentrantLock 是 AQS 的实现,支持
tryLock(timeout)超时等待、lockInterruptibly()响应中断,以及多个 Condition 对象(替代 Object 的 wait/notify 组,精确唤醒特定线程) - 锁升级是 synchronized 独有的:偏向锁 → 轻量级锁 → 重量级锁,竞争不激烈时性能不差,甚至优于 ReentrantLock
- 必须手动 unlock 的场景下用 ReentrantLock,放在 finally 块
加分项:「JDK 15 之后偏向锁被默认关闭,因为维护成本高且现代程序竞争普遍,这时两者的性能差距进一步缩小。」
Q2. synchronized 的锁升级过程是怎样的?
考官想听的角度:说出偏向锁到重量级锁的条件,不是只说「三种状态」。
答题要点:
- 偏向锁:对象头 Mark Word 记录偏向线程 ID,同一线程再次进入无需 CAS,几乎零开销。但一旦有第二个线程竞争,就触发偏向撤销(STW),成本不低
- 轻量级锁:多线程交替执行(无真实竞争)时,用栈帧中的锁记录 + Mark Word CAS 替换,避免进内核态。CAS 失败一定次数(自旋)后升级
- 重量级锁:对应 ObjectMonitor,进入等待队列,涉及线程上下文切换,OS 层调度,开销最大
- 锁只能升级不能降级(偏向锁撤销后不会退回)
Q3. volatile 的作用,以及它为什么不能保证原子性?
考官想听的角度:把可见性和有序性分开说,并给出一个 i++ 不安全的具体例子。
答题要点:
- 可见性:每次读从主内存读,每次写立即刷到主内存,禁止工作内存缓存
- 有序性:禁止指令重排,底层是内存屏障(LoadLoad/StoreStore/LoadStore/StoreLoad)
- 不保证原子性:
i++实际是三条字节码指令(getstatic、iadd、putstatic),volatile 只能保证每条指令读写的可见性,但三条指令之间仍可能被其他线程插入 - 典型用法:状态标志位(
volatile boolean running)、双重检查锁中防止半初始化对象的指令重排
Q4. ThreadLocal 内存泄漏是怎么发生的?怎么避免?
考官想听的角度:这是字节的高频追问题,必须说到 WeakReference 和线程池的关系。
答题要点:
ThreadLocalMap的 key 是WeakReference<ThreadLocal>,value 是强引用- 当 ThreadLocal 实例没有外部强引用时,key 被 GC 回收变为 null,但 value 仍然存活在 Entry 中
- 普通线程用完销毁问题不大;线程池里线程不销毁,这些 null-key 的 Entry 越积越多,最终 OOM
- 解法:每次用完调
threadLocal.remove(),放在 finally 块
加分项:「Spring 框架的 TransactionSynchronizationManager 用的就是 ThreadLocal,它在 cleanupTransactionInfo() 里有 remove,这是规范做法。」
Q5. AQS 的核心实现原理是什么?
考官想听的角度:说出 state 变量 + CLH 等待队列 + tryAcquire 模板方法的三角关系。
答题要点:
- AQS 内部有三个核心:
volatile int state(表示锁/资源状态)、当前持锁线程、FIFO 等待队列(CLH 变体) - 加锁失败时,线程被封装为 Node 进入队列,通过
LockSupport.park挂起 - 解锁时,修改 state 并唤醒队头节点的后继线程(
LockSupport.unpark) ReentrantLock、Semaphore、CountDownLatch都是 AQS 的子类,只需实现tryAcquire/tryRelease(独占)或tryAcquireShared/tryReleaseShared(共享)
Q6. ConcurrentHashMap 的线程安全是怎么实现的?JDK 7 和 JDK 8 的差异?
答题要点:
- JDK 7:分段锁(Segment),每个 Segment 继承 ReentrantLock,锁粒度是整个桶数组段
- JDK 8:彻底重写。用
Node[] table代替 Segment,锁粒度细化到每个桶的头节点(synchronized+ CAS)。空桶写入用 CAS,发生碰撞才加 synchronized - 扩容:引入 ForwardingNode 标记已迁移的桶,多线程协同迁移
size()方法用CounterCell分散计数,避免计数器本身成为竞争瓶颈
Q7. 线程池的核心参数,以及任务提交的完整流程?
考官想听的角度:必须说出拒绝策略触发的具体条件,很多人在这里答错。
答题要点:
- 7 个核心参数:
corePoolSize、maximumPoolSize、keepAliveTime、unit、workQueue、threadFactory、handler - 提交流程:线程数 < corePoolSize → 创建核心线程;>= corePoolSize → 入队;队列满且线程数 < maximumPoolSize → 创建非核心线程;队列满且线程数 = maximumPoolSize → 触发拒绝策略
- 注意:队列满才会创建非核心线程,不是先拉满线程数再入队
- 4 种拒绝策略:
AbortPolicy(抛异常,默认)、CallerRunsPolicy(调用者线程执行)、DiscardPolicy(静默丢弃)、DiscardOldestPolicy(丢队头最老的任务)
加分项:「生产里要用 CallerRunsPolicy 做反压,避免任务被静默丢掉。」
Q8. happens-before 原则是什么?
答题要点:
- JMM 对内存可见性的保证规则,不需要每次都用 synchronized,只要满足 happens-before 关系,前一个操作的结果对后一个操作可见
- 常用的:程序顺序规则、监视器锁规则(unlock happens-before 随后的 lock)、volatile 变量规则、线程启动规则、线程终止规则
- 核心意义:happens-before 是程序员和 JMM 之间的契约,JMM 承诺在满足这些规则时保证可见性
Q9. 什么是伪共享(False Sharing)?如何解决?
答题要点:
- CPU 以 Cache Line(通常 64 字节)为单位读写缓存,两个变量如果在同一 Cache Line,一个线程修改变量 A,另一个线程的变量 B 所在缓存行也会失效,即使 B 没被修改
- 解决方案:字节填充(Padding),让两个热点变量分别独占一个 Cache Line
- Java 7+ 的
@Contended注解(需-XX:-RestrictContended)自动填充,LongAdder、ConcurrentHashMap.CounterCell都用了这个技术
Q10. CompletableFuture 和 Future 的区别?
答题要点:
Future.get()是阻塞调用,没法链式组合多个异步任务CompletableFuture实现了CompletionStage,支持thenApply(同步转换)、thenCompose(异步链式)、thenCombine(合并两个结果)、exceptionally(异常处理)- 默认用
ForkJoinPool.commonPool()执行,也可以传入自定义线程池(推荐,避免公共池被占满) - 适合场景:多个 RPC 并行调用后合并结果,取代
CountDownLatch+Future.get()的组合
JVM:字节偏爱追问 GC 细节
JVM 模块字节通常不问「堆结构是什么」这种入门题,而是问「你们线上 Full GC 怎么排查」「G1 什么时候会退化为 Full GC」「类加载什么情况下会破坏双亲委派」。
Q11. G1 GC 的工作原理,以及它相比 CMS 的优势?
考官想听的角度:说出 Region 设计的核心动机——可预测的停顿时间。
答题要点:
- G1 把堆划分为大小相等的 Region(默认 2MB),不固定每个 Region 的角色(Eden/Survivor/Old 可以动态变化)
- 优先回收「垃圾占比高的 Region」(Garbage First),在用户设定的停顿时间目标内尽量多回收
- 混合回收(Mixed GC):年轻代 + 部分老年代 Region 一起回收,避免 CMS 的全老年代回收
- CMS 的问题:碎片化(标记-清除)、无法应对浮动垃圾时会退化为 Serial Old;G1 使用标记-整理,无碎片
加分项:「Region 内部对象跨 Region 引用靠 Remembered Set 维护,这是 G1 写屏障的代价,内存占用通常比 CMS 多 10-20%。」
Q12. Minor GC、Major GC、Full GC 的触发条件分别是什么?
答题要点:
- Minor GC:Eden 区满时触发,回收年轻代(Eden + Survivor),速度快
- Major GC:通常指老年代 GC,G1 里叫 Mixed GC,CMS 叫 Old GC
- Full GC:回收整个堆(年轻代 + 老年代 + 方法区),触发条件:调用
System.gc();老年代空间不足;方法区空间不足;Minor GC 后晋升到老年代的对象超过老年代剩余空间(晋升担保失败) - G1 退化为 Full GC:并发标记跟不上分配速度,或 Evacuation Failure(疏散失败,Region 不够用)
Q13. 类加载的双亲委派机制,哪些情况下会破坏它?
考官想听的角度:给出真实场景,不是背定义。
答题要点:
- 双亲委派:加载类先委派父类加载器,父类找不到才自己加载,保证核心类库不被覆盖
- 破坏场景一:JDBC。
DriverManager在 Bootstrap ClassLoader 里,但需要加载各厂商的 Driver 实现(在应用 classpath),因此用了线程上下文类加载器(Thread.getContextClassLoader())反向委派 - 破坏场景二:Tomcat。每个 Web App 有独立 ClassLoader,可以加载同名但不同版本的类(如 Spring 3 和 Spring 4 并存),故意打破隔离
- 破坏场景三:OSGi、热部署场景,需要动态替换类
Q14. JVM 的内存区域划分,哪些区域可能 OOM?
答题要点:
- 线程私有:程序计数器(唯一不会 OOM)、虚拟机栈(StackOverflowError / OOM)、本地方法栈
- 线程共享:堆(Java 对象,最常见的 OOM)、方法区/元空间(存类元信息,元空间 OOM 通常因为动态生成大量类,如 CGLib)
- 直接内存:NIO ByteBuffer 直接内存不受堆管理,Unsafe 分配,OOM 表现为「OutOfMemoryError: Direct buffer memory」
Q15. 如何定位一次生产 Full GC 频繁的问题?
考官想听的角度:说出排查工具链,而不只是说「看 GC 日志」。
答题要点:
- 开启 GC 日志:
-Xlog:gc*:file=gc.log:time(JDK 9+),观察 Full GC 频率和每次停顿时间 - 用
jmap -histo:live <pid>看存活对象分布,找排名靠前的大对象 jmap -dump:format=b,file=heap.hprof <pid>dump 堆,MAT 分析 Retention Heap,找引用链- 常见根因:内存泄漏(缓存 Map 没有过期策略)、大对象直接进老年代(-XX:PretenureSizeThreshold)、元空间不足(动态代理 + 类卸载问题)
Q16. ZGC 的核心特点是什么?适合什么场景?
答题要点:
- 目标:停顿时间不超过 10ms,且与堆大小无关(G1 的停顿随堆大小增长)
- 核心技术:着色指针(Colored Pointers)+ 读屏障,在并发阶段完成对象移动,不需要 STW
- JDK 15 正式生产可用,JDK 21 引入分代 ZGC,进一步降低内存占用
- 适合场景:大堆(>32GB)+ 延迟敏感(金融交易、实时推荐),代价是 CPU 开销高于 G1 约 5-10%
Q17. 什么情况下对象会直接进入老年代?
答题要点:
- 大对象(
-XX:PretenureSizeThreshold,默认关闭,设置阈值后超过该大小直接进老年代) - 长期存活对象(默认 15 次 Minor GC 后,年龄阈值
-XX:MaxTenuringThreshold) - 动态年龄判断:Survivor 区同龄对象占 Survivor 空间 50% 以上,直接晋升(不需要等到 15 次)
- 晋升担保失败:Minor GC 前检查老年代连续空间是否足以容纳最近几次平均晋升量,不够则 Full GC
Q18. 什么是 TLAB?为什么需要它?
答题要点:
- Thread Local Allocation Buffer,每个线程在 Eden 区独占的一小块内存用于对象分配
- 避免多线程分配对象时在 Eden 上 CAS 竞争(虽然 CAS 单次快,但高频分配下竞争明显)
- TLAB 用完了再申请一块新的,申请时需要全局锁,但频率低
- 大对象直接在 Eden 上 CAS 分配(绕过 TLAB)
MySQL:索引和事务必考,InnoDB 内部机制看运气
字节 MySQL 模块通常先问索引,再追问事务和锁,最后看情况聊 binlog/redo log。最近两年出现了「分库分表的跨库查询怎么做」的场景题,需要有具体方案。
Q19. MySQL 为什么用 B+ 树做索引,而不是 B 树或哈希表?
考官想听的角度:从磁盘 I/O 的视角解释,而不只是说「B+ 树叶子节点有链表」。
答题要点:
- B 树 vs B+ 树:B 树的非叶节点也存数据,导致每个节点能存的 key 数变少,树高更高,磁盘 I/O 次数更多;B+ 树非叶节点只存 key,4KB 页面能存更多 key,树高通常只有 3-4 层(10 亿行数据树高约 4)
- B+ 树叶节点用链表相连,支持高效的范围查询(
BETWEEN、ORDER BY),B 树做不到 - 哈希表不支持范围查询,只适合等值查询,且哈希冲突下退化为链表
- InnoDB 页面大小默认 16KB,B+ 树每层能存约 1170 个指针,三层可寻址约 1170² × 16 = 2000 万行
Q20. 聚簇索引和非聚簇索引的区别?回表是什么?
答题要点:
- 聚簇索引:叶节点直接存行数据,InnoDB 的主键索引就是聚簇索引,数据按主键顺序存储
- 非聚簇索引(二级索引):叶节点存的是主键值,而非行数据
- 回表:通过二级索引找到主键后,再用主键查聚簇索引获取完整行数据,两次 B+ 树查找
- 覆盖索引:查询列全部在索引中,不需要回表。
EXPLAIN中Extra: Using index表明覆盖索引命中
Q21. 最左匹配原则,什么情况下联合索引会失效?
答题要点:
- 联合索引
(a, b, c)实际按 a → b → c 排序。查询必须从最左列开始,且不能跳列 - 失效场景:跳过最左列(
WHERE b=1,不用 a);最左列使用范围查询后,后续列不走索引(WHERE a > 1 AND b = 2,b 不走索引);对索引列使用函数(WHERE YEAR(create_time) = 2024);隐式类型转换(字符串列用数字匹配);LIKE '%前缀'(通配符在开头)
Q22. EXPLAIN 执行计划怎么看?重点关注哪些字段?
答题要点:
type:访问类型,性能从好到差:system > const > eq_ref > ref > range > index > ALL。ALL 就是全表扫描,需要优化key:实际使用的索引,NULL 表示未命中索引rows:估算扫描行数,越小越好Extra:Using index(覆盖索引)、Using where(需要再过滤)、Using filesort(文件排序,可能需要加索引)、Using temporary(用了临时表,需要优化)possible_keys和key不一致时,说明优化器选了另一个索引或放弃索引
Q23. MySQL 的事务隔离级别,以及 InnoDB 默认使用哪种?
答题要点:
- 4 种隔离级别:Read Uncommitted(读脏数据)、Read Committed(不可重复读)、Repeatable Read(幻读可能)、Serializable(串行化)
- InnoDB 默认:Repeatable Read,且通过 Next-Key Lock(行锁 + 间隙锁)在大多数场景下防止幻读,比标准 SQL 定义更严格
- MVCC(多版本并发控制):通过 undo log 维护版本链,读操作读快照(历史版本),写操作不阻塞读,实现「读读不互斥、读写不互斥」
- Read View:事务开始时创建,决定哪个版本对当前事务可见
Q24. InnoDB 的行锁类型有哪些?间隙锁的作用?
答题要点:
- 记录锁(Record Lock):锁定单行
- 间隙锁(Gap Lock):锁定索引记录之间的间隙,防止其他事务插入,RR 级别下用于防幻读
- Next-Key Lock = 记录锁 + 间隙锁,InnoDB RR 下默认使用
- 临键锁降级场景:等值查询命中唯一索引时,退化为记录锁(无间隙锁);等值查询不存在的记录时,退化为间隙锁
- 死锁排查:
SHOW ENGINE INNODB STATUS查看最近一次死锁信息
Q25. redo log 和 binlog 的区别?两阶段提交是怎么回事?
考官想听的角度:说出「为什么需要两阶段提交」,而不只是描述格式差异。
答题要点:
- redo log 是 InnoDB 层的物理日志(页的修改),用于崩溃恢复,循环写覆盖
- binlog 是 MySQL Server 层的逻辑日志(SQL 或行变更),用于主从复制、时间点恢复,追加写
- 两阶段提交:先写 redo log(prepare 状态)→ 写 binlog → redo log 提交。目的是保证 redo log 和 binlog 的一致性——如果只写一个然后崩溃,会出现「binlog 有但 redo log 没有」或反向不一致的情况,导致主从数据不同步
Q26. 什么是慢查询?如何定位和优化?
答题要点:
- 慢查询日志:
slow_query_log=ON,long_query_time=1(默认 1 秒),记录超时查询 - 分析工具:
pt-query-digest按执行频率 × 耗时排序,找出最值得优化的 SQL - 优化思路:加索引(先 EXPLAIN 确认)→ 改写 SQL(避免
SELECT *、避免函数计算索引列)→ 分页优化(大 offset 用WHERE id > last_id)→ 分表(数据量超过 5000 万考虑)
Q27. MVCC 的 Read View 和版本链是怎么工作的?
答题要点:
- 每行数据有两个隐藏字段:
trx_id(最后修改该行的事务 ID)和roll_pointer(指向 undo log 的版本链) - Read View 包含:
m_ids(当前活跃事务列表)、min_trx_id、max_trx_id、creator_trx_id - 可见性判断:trx_id < min_trx_id → 可见(已提交);trx_id > max_trx_id → 不可见(后开始);在 m_ids 里 → 不可见(未提交);不在 m_ids 里且在范围内 → 可见(已提交)
- RC 每次读都创建新 Read View(所以可以读到其他事务新提交的数据),RR 只在事务开始时创建一次
Redis:缓存策略 + 数据结构 + 持久化三件套
字节 Redis 模块的特点是不只考「说一下缓存穿透」,会追问「你们用的哪种布隆过滤器实现、误判率是多少」这类需要实际操作经验的问题。
Q28. Redis 为什么快?单线程不是应该慢吗?
考官想听的角度:这是字节高频问法,有反直觉的味道,要说出「单线程避免了什么」。
答题要点:
- 基于内存操作(无磁盘 I/O):内存访问速度是磁盘的 10 万倍
- 单线程模型:避免了多线程的上下文切换开销和锁竞争,CPU 时间都花在处理命令上
- IO 多路复用:用 epoll(Linux)监听多个连接的 I/O 事件,单线程处理多个连接,不阻塞
- 高效数据结构:ziplist/listpack 压缩存储小对象,跳表做有序集合,相比 B 树减少内存分配
- 注意:6.0 之后引入了 IO 多线程(读写网络数据用多线程,命令执行仍然单线程)
Q29. 缓存穿透、缓存击穿、缓存雪崩,分别怎么解决?
答题要点:
缓存穿透(查询不存在的数据,每次都打到 DB):
- 布隆过滤器:请求前先问过滤器,不存在的直接拦截
- 缓存空值:DB 没有时也缓存一个 null(短 TTL,如 60 秒),防止恶意重复请求
缓存击穿(热 key 过期,大量请求同时穿透到 DB):
- 互斥锁:第一个请求加锁去 DB 查,其余等待,锁释放后从缓存读
- 热 key 不过期(逻辑过期):key 永不过期,value 里存过期时间,后台异步刷新
缓存雪崩(大量 key 同时过期或 Redis 宕机,请求全打到 DB):
- TTL 加随机值,避免同时过期
- Redis 集群,避免单点故障
- 熔断降级,DB 压力过大时直接返回降级结果
Q30. Redis 持久化:RDB 和 AOF 怎么选?
考官想听的角度:说出各自的数据丢失量和性能代价,而不是只列格式差异。
答题要点:
- RDB:BGSAVE 子进程 fork + 写时复制,不影响主线程。恢复快(直接加载快照),但最多丢失上次 RDB 到崩溃时间段的数据(生产里通常 5-15 分钟)
- AOF:每条写命令追加到文件,
appendfsync always(每次刷盘,最安全,性能最差)、everysec(每秒刷,最多丢 1 秒)、no(OS 决定,性能最好但不可控) - AOF 重写(BGREWRITEAOF):压缩日志,合并冗余命令,4.0+ 支持混合持久化(先写 RDB 快照,再追加 AOF 增量),兼顾恢复速度和数据安全
- 生产常见选择:AOF
everysec+ 每天 RDB 备份,平衡数据安全和恢复速度
Q31. Redis 的数据类型及其底层实现?
答题要点:
- String:SDS(Simple Dynamic String),O(1) 获取长度,预分配空间,二进制安全
- List:ziplist(小列表,<128 元素且元素 <64 字节)或 quicklist(大列表,多个 ziplist 节点组成的双向链表)。7.0 之后 ziplist 被 listpack 替代
- Hash:ziplist(小哈希)或 hashtable(大哈希)
- Set:intset(全整数的小集合)或 hashtable
- ZSet:ziplist(小有序集合)或 skiplist + hashtable(大有序集合)
Q32. Redis 的过期删除策略和内存淘汰策略?
答题要点:
- 过期删除:惰性删除(访问时检查是否过期,过期则删)+ 定期删除(周期性随机检查部分 key,删过期的),两者结合
- 内存淘汰(maxmemory 触发):8 种策略,常用的有
allkeys-lru(全部 key 中 LRU 淘汰,缓存场景推荐)、volatile-lru(只淘汰设了 TTL 的 key)、allkeys-random、noeviction(拒绝写) - 生产建议:缓存场景用
allkeys-lru,避免没设 TTL 的 key 永不淘汰撑满内存
Q33. Redis 分布式锁的实现,以及 Redlock 的问题?
答题要点:
- 基础实现:
SET key value NX PX 30000(原子操作,NX 不存在才设,PX 设毫秒过期) - 释放锁必须验证 value(随机值),防止误释放其他线程的锁:用 Lua 脚本保证「判断 + 删除」原子性
- 锁续期:Redisson 的 WatchDog 机制,持锁线程还在就自动续期(每 10 秒检查,TTL/3 时续期)
- Redlock:Antirez 提出的多节点(5 个独立 Redis)方案,在大多数节点加锁成功才算加锁成功。但 Martin Kleppmann 指出 GC Stop-the-World 或网络分区时仍有安全漏洞,争议持续至今
- 生产建议:单 Redis + WatchDog 已经够用,Redlock 引入的复杂度通常不值得
网络与操作系统:考深度不考广度
字节网络模块不考「OSI 七层模型是什么」,考的是「TIME_WAIT 为什么等 2MSL」「epoll 和 select 的性能差距从哪来」这类需要理解底层的问题。
Q34. TCP 三次握手的过程,为什么不能是两次?
考官想听的角度:说出「两次握手的具体问题是什么」,而不只是复述流程。
答题要点:
- 流程:SYN → SYN-ACK → ACK,双方分别确认对方的发送和接收能力
- 为什么两次不够:服务端发 SYN-ACK 后不知道客户端能否收到,若客户端之前的 SYN 在网络中延迟到达,服务端会开启一个无效连接等待,两次握手会浪费服务端资源
- 三次握手的本质:让双方都确认「我的 seq 对方收到了,对方的 seq 我也确认了」,保证 ISN 同步
Q35. TIME_WAIT 状态为什么等 2MSL?大量 TIME_WAIT 怎么处理?
答题要点:
- 2MSL(最大报文段生存时间 × 2,通常 60-120 秒)的目的:确保最后一个 ACK 能到达对端;等待网络中残余分组消失(如果立刻重用端口,旧连接的延迟数据可能干扰新连接)
- 大量 TIME_WAIT 的常见场景:HTTP 短连接,服务端主动关闭(四次挥手的主动方进入 TIME_WAIT)
- 解决方案:启用
SO_REUSEADDR+tcp_tw_reuse(允许 TIME_WAIT 端口用于新连接,需配合时间戳 PAWS);启用 HTTP Keep-Alive 减少连接创建/销毁次数
Q36. epoll 相比 select/poll 的优势在哪里?
考官想听的角度:从「每次调用的开销」和「事件通知机制」两个维度说,而不只说「epoll 没有数量限制」。
答题要点:
- select/poll 每次调用都把 fd 集合从用户空间拷贝到内核,内核遍历所有 fd 检查状态,O(n) 开销
- epoll 注册 fd 只拷贝一次(
epoll_ctl),内核用红黑树维护监听 fd,事件发生时通过回调加入就绪链表(epoll_wait只返回就绪的 fd),O(1) 复杂度 - ET(边缘触发)vs LT(水平触发):ET 只在状态变化时通知一次,要求单次 read 读完,否则丢事件;LT 只要缓冲区有数据就持续通知,编程更简单
- Redis 用 epoll(Linux),Mac 上用 kqueue
Q37. TCP 如何保证可靠传输?
答题要点:
- 序号 + 确认应答(ACK):丢包重传
- 超时重传:RTO 自适应计算(基于 RTT 采样)
- 滑动窗口:流量控制,接收方通告窗口大小限制发送速率
- 拥塞控制:慢启动 → 拥塞避免 → 快速重传 → 快速恢复(CUBIC 等算法)
- 校验和:验证数据完整性
Q38. HTTP/1.1、HTTP/2、HTTP/3 的主要差异?
答题要点:
- HTTP/1.1:keep-alive 复用连接,但 HOL 阻塞(同一连接后续请求必须等前一个响应)
- HTTP/2:二进制分帧,多路复用(一个 TCP 连接并行多个请求/响应流),Header 压缩(HPACK),服务器推送。但 TCP 层 HOL 阻塞仍存在(丢包时整个连接阻塞)
- HTTP/3:基于 QUIC(UDP),每个 Stream 独立,丢包只影响该 Stream;0-RTT 连接建立;内置 TLS 1.3
- 生产里 HTTP/3 需要 CDN 支持,后端服务间通信更多用 gRPC(HTTP/2)
Q39. 进程和线程的区别,什么是协程?
答题要点:
- 进程是资源分配单位(地址空间、文件描述符),线程是调度单位,共享进程资源
- 上下文切换代价:进程切换要切换地址空间(TLB 刷新),代价大;线程共享地址空间,代价小
- 协程(Coroutine):用户态的调度,协程切换不经过内核,代价极小(保存/恢复寄存器 + 栈帧)。Java 21 的虚拟线程(Virtual Thread)本质是协程,100 万个并发写法和普通线程一样
- Go 的 goroutine 就是协程,M:N 调度模型
Q40. 什么是用户态和内核态?系统调用的开销在哪里?
答题要点:
- 用户态(Ring 3):受限权限,不能直接操作硬件
- 内核态(Ring 0):全权限,可以操作硬件、管理内存
- 切换开销:保存用户态寄存器 → 切换到内核栈 → 执行系统调用 → 恢复用户态,一次约 200-500ns
- 减少系统调用的思路:批量处理(
writev一次写多块)、零拷贝(sendfile 避免用户态拷贝)、mmap 映射内存
算法:字节一面必手撕,没有例外
字节一面几乎 100% 会有算法题,通常 1-2 道。难度在 LeetCode Medium 左右,但要求代码不出错,有时现场 debug。以下是出现频率最高的题型,考的不只是解法,还有「你在写之前有没有说思路」。
Q41. 手撕 LRU Cache
字节出现频率最高的算法题,要求 O(1) 的 get 和 put。
核心思路:HashMap(key → 双向链表节点)+ 双向链表(维护访问顺序)
- get:从 map 取节点,移到链表头部(表示最近使用),返回值
- put:key 存在则更新并移到头部;不存在则创建节点插头部,同时 map 记录。如果超容量,删链表尾节点同时删 map 记录
class LRUCache {
privatefinalint capacity;
privatefinal Map<Integer, Node> map;
privatefinal Node head, tail; // 哨兵节点
class Node {
int key, val;
Node prev, next;
Node(int k, int v) { key = k; val = v; }
}
public LRUCache(int capacity) {
this.capacity = capacity;
map = new HashMap<>();
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
}
public int get(int key) {
if (!map.containsKey(key)) return -1;
Node node = map.get(key);
moveToHead(node);
return node.val;
}
public void put(int key, int value) {
if (map.containsKey(key)) {
Node node = map.get(key);
node.val = value;
moveToHead(node);
} else {
Node node = new Node(key, value);
map.put(key, node);
addToHead(node);
if (map.size() > capacity) {
Node tail = removeTail();
map.remove(tail.key);
}
}
}
private void moveToHead(Node node) {
removeNode(node);
addToHead(node);
}
private void removeNode(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void addToHead(Node node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
private Node removeTail() {
Node node = tail.prev;
removeNode(node);
return node;
}
}
Q42. 最长无重复子串(滑动窗口)
字节真实出现,要求 O(n) 时间复杂度。
核心思路:双指针(left, right)+ HashMap 记录字符的最新位置。right 遍历字符串,若当前字符在窗口内已出现,left 跳到该字符上次位置的下一位。
public int lengthOfLongestSubstring(String s) {
Map<Character, Integer> map = new HashMap<>();
int left = 0, maxLen = 0;
for (int right = 0; right < s.length(); right++) {
char c = s.charAt(right);
if (map.containsKey(c) && map.get(c) >= left) {
left = map.get(c) + 1; // 收缩左边界
}
map.put(c, right);
maxLen = Math.max(maxLen, right - left + 1);
}
return maxLen;
}
Q43. 反转链表(以及区间反转 [m, n])
考官版本通常是「反转区间 [m, n] 的链表」,而不是简单的全链表反转。
核心思路:用 dummy 节点,找到第 m-1 个节点,然后在区间内用头插法逐个移动节点到区间起始位置。
Q44. 二叉树的层序遍历
BFS + 队列,每层单独收集。这道题在字节一面里会进一步追问:「之字形遍历」「只打印叶子节点」。
Q45. 合并两个有序链表
递归或迭代均可。递归写法更优雅但面试时要注意栈深度问题:
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
if (l1 == null) return l2;
if (l2 == null) return l1;
if (l1.val <= l2.val) {
l1.next = mergeTwoLists(l1.next, l2);
return l1;
} else {
l2.next = mergeTwoLists(l1, l2.next);
return l2;
}
}
Q46. 找到数组中第 k 大的元素(QuickSelect)
TopK 问题,字节喜欢考。O(n) 期望时间的 QuickSelect,而不是 O(n log n) 的排序。
核心思路:类似快排的分区,但只递归「k 所在的那半边」:
public int findKthLargest(int[] nums, int k) {
return quickSelect(nums, 0, nums.length - 1, nums.length - k);
}
private int quickSelect(int[] nums, int left, int right, int target) {
int pivot = partition(nums, left, right);
if (pivot == target) return nums[pivot];
return pivot < target
? quickSelect(nums, pivot + 1, right, target)
: quickSelect(nums, left, pivot - 1, target);
}
private int partition(int[] nums, int left, int right) {
int pivot = nums[right], i = left;
for (int j = left; j < right; j++) {
if (nums[j] <= pivot) { int t = nums[i]; nums[i++] = nums[j]; nums[j] = t; }
}
int t = nums[i]; nums[i] = nums[right]; nums[right] = t;
return i;
}
Q47. 最大子数组和(Kadane 算法)
经典动态规划,O(n) 时间。dp[i] = 以 nums[i] 结尾的最大子数组和 = max(nums[i], dp[i-1] + nums[i]),空间可以压缩到 O(1)。
Q48. 有效的括号(栈)
栈应用,遇到左括号压栈,遇到右括号判断栈顶是否匹配。字节会追问「设计一个支持 push、pop、min 的 O(1) min 栈」。
Q49. 二分查找变体:找旋转排序数组的最小值
旋转数组系列是字节高频题。核心是 mid 和 right 比较:如果 nums[mid] > nums[right],最小值在右半段;否则在左半段(含 mid)。
Q50. 动态规划:最少完全平方数(BFS 或 DP 均可)
字节一面真实出现(LeetCode 279)。DP 思路:dp[i] = min(dp[i - j*j] + 1),j 从 1 枚举到 j*j <= i。
高频 FAQ
Q:字节一面算法几道题,什么难度?
一般 1-2 道,LeetCode Medium 为主,少部分 Hard(二叉树系列、动规)。但字节面试官喜欢在你写完后追加约束或变形,「如果输入有重复元素呢」「如果要求 O(1) 空间呢」,这才是真正筛人的部分。写完就满足是不够的,要主动说出边界情况和复杂度分析。
Q:一面多长时间,知识点问多少?
通常 45-60 分钟。结构通常是:5 分钟自我介绍 + 项目深挖 → 20 分钟知识点(选 2-3 个领域,每个领域 3-4 道追问) → 20 分钟算法 → 5 分钟反问。知识点不是一道道顺序过,而是选几个点深挖到底。
Q:项目经历和知识点哪个更重要?
都重要,但项目是「差异化」的地方。知识点回答差不多,面试官会在项目上找区分度——「你说你用了分布式锁,具体是什么场景,为什么不用 DB 乐观锁」。没有实际项目里用过的技术,背再多八股也很容易被追问露馅。
Q:答题时发现某个原理没背到怎么办?
实话实说「这个细节我不太确定,我的理解是 XX,但可能有偏差」,然后说出你能推导出来的部分。比「编一个不确定的答案」好得多——字节面试官追几句就能判断你是在背书还是真正理解。
Q:Spring Boot 相关知识面吗?
一面通常不主动考 Spring,但如果你简历上写了 Spring 项目,会借此追问「Bean 的生命周期」「循环依赖怎么解决」「Spring 事务失效的场景」。所以写进简历的框架要确保能说清楚原理。
总结
字节一面的通过率不高,不是因为题目超纲,而是因为大多数人准备的是「背答案」而不是「理解设计」。这 50 道题的答题要点都在往「为什么这样设计」的方向引,看到一道题脑子里先想「这个设计在解决什么问题」,而不是直接找对应的记忆片段。
写这篇的时候码哥翻了不少 2025-2026 的面经,发现字节这两年越来越爱考 Java 21 的特性(虚拟线程、Records、Pattern Matching)和 G1/ZGC 的对比。
下篇打算把字节二面的系统设计题整理一遍,二面和一面的考察维度差别挺大,关注一下,不然等用到了才来找就来不及了。身边有人在准备字节面试,这篇可以直接发给他,省他再去各处找面经的时间。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号