2026-06-09:带权单词映射。用go语言,给定一个字符串数组 words,以及一个长度为 26 的整数数组 weights,其中 weights[i] 表示字母表中

2026-06-09:带权单词映射。用go语言,给定一个字符串数组 words,以及一个长度为 26 的整数数组 weights,其中 weights[i] 表示字母表中

福大大架构师每日一题
发布于 2026-06-12 18:07:34
发布于 2026-06-12 18:07:34
2026-06-09:带权单词映射。用go语言,给定一个字符串数组 words,以及一个长度为 26 的整数数组 weights,其中 weights[i] 表示字母表中第 i 个小写字母的权重。
每个单词的权重是该单词中所有字符对应权重的总和。对每个单词计算:
1.取它的权重对 26 的余数;
2.将这个余数按“倒序字母”的规则映射到字符:余数为 0 对应 'z',1 对应 'y',…,25 对应 'a'。
最后把所有单词对应得到的字符依次连接,形成返回的字符串。
1 <= words.length <= 100。
1 <= words[i].length <= 10。
weights.length == 26。
1 <= weights[i] <= 100。
words[i] 仅由小写英文字母组成。
输入: words = ["abcd","def","xyz"], weights = [5,3,12,14,1,2,3,2,10,6,6,9,7,8,7,10,8,9,6,9,9,8,3,7,7,2]。
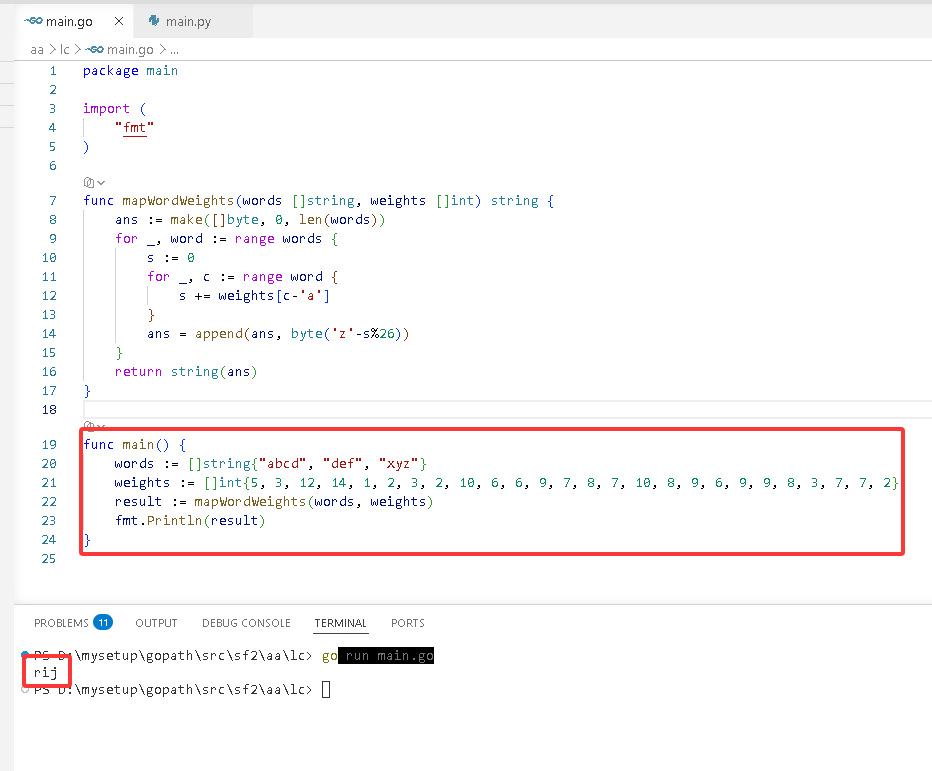
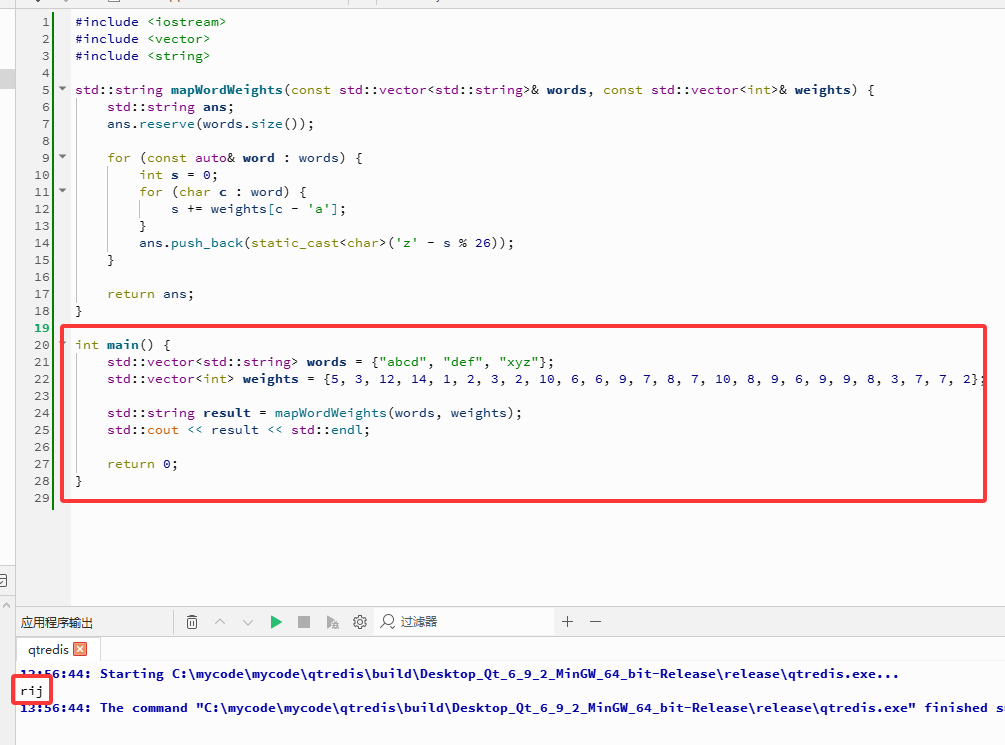
输出: "rij"。
解释:
"abcd" 的权重是 5 + 3 + 12 + 14 = 34。对 26 取模的结果是 34 % 26 = 8,映射为 'r'。
"def" 的权重是 14 + 1 + 2 = 17。对 26 取模的结果是 17 % 26 = 17,映射为 'i'。
"xyz" 的权重是 7 + 7 + 2 = 16。对 26 取模的结果是 16 % 26 = 16,映射为 'j'。
因此,连接映射字符后形成的字符串是 "rij"。
题目来自力扣3838。
一、分步详细执行过程
步骤1:初始化输入数据
在main函数中,定义两个核心输入变量:
- 1. 字符串数组
words:["abcd", "def", "xyz"],包含3个需要处理的单词; - 2. 整数数组
weights:长度固定为26,对应小写字母a-z的权重,weights[0]是a的权重,weights[1]是b的权重……weights[25]是z的权重。
步骤2:调用核心函数mapWordWeights
函数接收words和weights两个参数,开始逐单词处理,第一步先初始化结果容器:
创建一个空的字节切片ans,预分配容量为单词的数量(3),用于存储每个单词最终映射的字符。
步骤3:遍历处理每一个单词
程序会依次遍历words中的每一个单词,对每个单词执行计算总权重、取余数、倒序映射字符三个子步骤:
子步骤3.1:处理第一个单词 "abcd"
- 1. 计算单词总权重:
遍历单词的每一个字符,将字符转换为对应权重索引(字符
c - 'a'得到字母在a-z中的序号),累加所有字符的权重:- • a → 序号0 → 权重5
- • b → 序号1 → 权重3
- • c → 序号2 → 权重12
- • d → 序号3 → 权重14 总权重 = 5+3+12+14 = 34
- 2. 计算权重对26的余数:34 % 26 = 8
- 3. 倒序字母映射字符:规则是余数0→z,1→y……25→a,计算公式:
'z' - 余数余数8 → 'z' - 8 = 字符'r',将'r'存入结果容器ans。
子步骤3.2:处理第二个单词 "def"
- 1. 计算单词总权重:
- • d → 序号3 → 权重14
- • e → 序号4 → 权重1
- • f → 序号5 → 权重2 总权重 = 14+1+2 = 17
- 2. 计算权重对26的余数:17 % 26 = 17
- 3. 倒序字母映射字符:'z' -17 = 字符'i',将'i'存入结果容器
ans。
子步骤3.3:处理第三个单词 "xyz"
- 1. 计算单词总权重:
- • x → 序号23 → 权重7
- • y → 序号24 → 权重7
- • z → 序号25 → 权重2 总权重 =7+7+2=16
- 2. 计算权重对26的余数:16 %26=16
- 3. 倒序字母映射字符:'z'-16=字符'j',将'j'存入结果容器
ans。
步骤4:拼接结果并返回
所有单词处理完成后,结果容器ans中存储了['r','i','j'],将字节切片转换为字符串,得到最终结果"rij"。
步骤5:输出结果
main函数打印最终结果rij,程序执行结束。
二、时间复杂度分析
时间复杂度描述程序执行时操作次数的增长趋势,我们分维度计算:
- 1. 设单词数组长度为
N(题目中1≤N≤100),单个单词的最大长度为M(题目中1≤M≤10); - 2. 程序核心操作:遍历每个单词(N次),遍历单词的每个字符(M次),字符权重计算、取余、映射都是常数时间操作(O(1));
- 3. 总操作次数 = N × M;
- 4. 最终时间复杂度:O(N*M)。
补充:题目中N和M都是固定小范围数值,程序执行效率极高。
三、额外空间复杂度分析
额外空间复杂度描述除输入数据外,程序额外占用的内存空间:
- 1. 程序额外创建的变量:总权重累加变量
s、遍历用的临时字符/索引变量、结果字节切片ans; - 2. 结果切片
ans的长度等于单词数量N,是唯一与输入规模相关的额外空间; - 3. 其余变量均为常数级空间(O(1));
- 4. 最终额外空间复杂度:O(N)。
总结
- 1. 执行过程:准备输入→逐单词计算总权重→计算余数→倒序映射字符→拼接结果→输出;
- 2. 时间复杂度:O(N*M)(N为单词个数,M为单词最大长度);
- 3. 额外空间复杂度:O(N)(仅存储结果的切片占用线性空间)。
Go完整代码如下:
.
package main
import (
"fmt"
)
func mapWordWeights(words []string, weights []int)string {
ans := make([]byte, 0, len(words))
for _, word := range words {
s := 0
for _, c := range word {
s += weights[c-'a']
}
ans = append(ans, byte('z'-s%26))
}
returnstring(ans)
}
func main() {
words := []string{"abcd", "def", "xyz"}
weights := []int{5, 3, 12, 14, 1, 2, 3, 2, 10, 6, 6, 9, 7, 8, 7, 10, 8, 9, 6, 9, 9, 8, 3, 7, 7, 2}
result := mapWordWeights(words, weights)
fmt.Println(result)
}
在这里插入图片描述
Python完整代码如下:
.
# -*-coding:utf-8-*-
def map_word_weights(words, weights):
ans = []
for word in words:
s = 0
for c in word:
s += weights[ord(c) - ord('a')]
ans.append(chr(ord('z') - s % 26))
return''.join(ans)
def main():
words = ["abcd", "def", "xyz"]
weights = [5, 3, 12, 14, 1, 2, 3, 2, 10, 6, 6, 9, 7, 8, 7, 10, 8, 9, 6, 9, 9, 8, 3, 7, 7, 2]
result = map_word_weights(words, weights)
print(result)
if __name__ == "__main__":
main()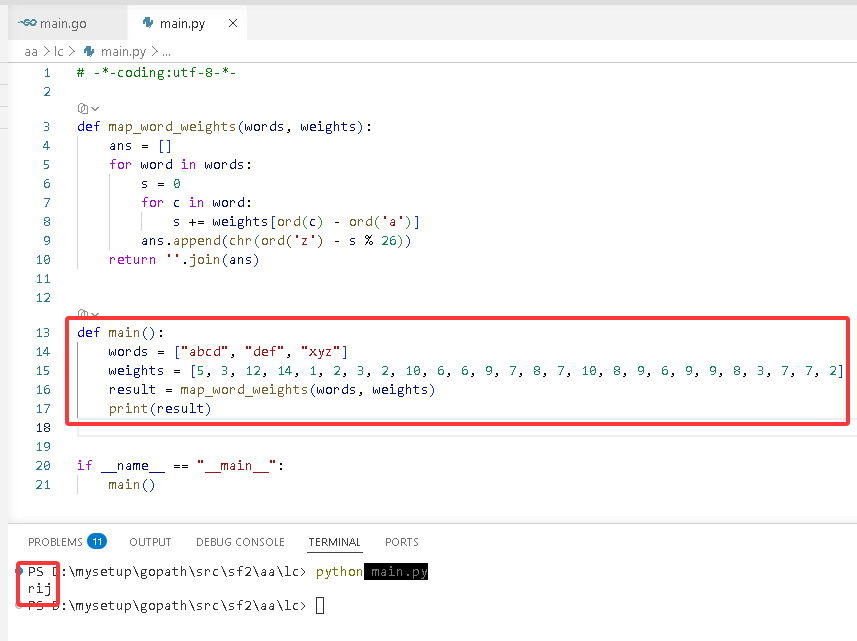
在这里插入图片描述
C++完整代码如下:
.
#include <iostream>
#include <vector>
#include <string>
std::string mapWordWeights(const std::vector<std::string>& words, const std::vector<int>& weights) {
std::string ans;
ans.reserve(words.size());
for (const auto& word : words) {
int s = 0;
for (char c : word) {
s += weights[c - 'a'];
}
ans.push_back(static_cast<char>('z' - s % 26));
}
return ans;
}
int main() {
std::vector<std::string> words = {"abcd", "def", "xyz"};
std::vector<int> weights = {5, 3, 12, 14, 1, 2, 3, 2, 10, 6, 6, 9, 7, 8, 7, 10, 8, 9, 6, 9, 9, 8, 3, 7, 7, 2};
std::string result = mapWordWeights(words, weights);
std::cout << result << std::endl;
return0;
}
在这里插入图片描述
·
我们相信人工智能为普通人提供了一种“增强工具”,并致力于分享全方位的AI知识。在这里,您可以找到最新的AI科普文章、工具评测、提升效率的秘籍以及行业洞察。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号