零代码开发系统:基于 WorkBuddy + Docker开发部门系统导航中枢
原创
零代码开发系统:基于 WorkBuddy + Docker开发部门系统导航中枢
原创
七条猫
发布于 2026-06-11 19:28:20
发布于 2026-06-11 19:28:20
第一部分:序章——当多系统成为部门效率的隐形杀手
1.1 数字化繁荣背后的“熵增”危机
在 2026 年的今天,企业数字化转型已火了好久。作为一家中型制造企业的运营与技术中台部门,我们在过去三年里积极响应公司“降本增效”的号召,像搭积木一样,快速堆砌了数十套业务系统。这其中包括自研的 MES 报表平台、第三方的 帆软系统、测试环境的 Jenkins 流水线、灰度发布的网关),以及各类临时的数据查询工具等等。
然而,随着系统数量的激增,一种“数字化熵增”的现象开始在我们部门蔓延。系统的入口不再是指向明确的快捷方式,而变成了一张错综复杂的蜘蛛网。
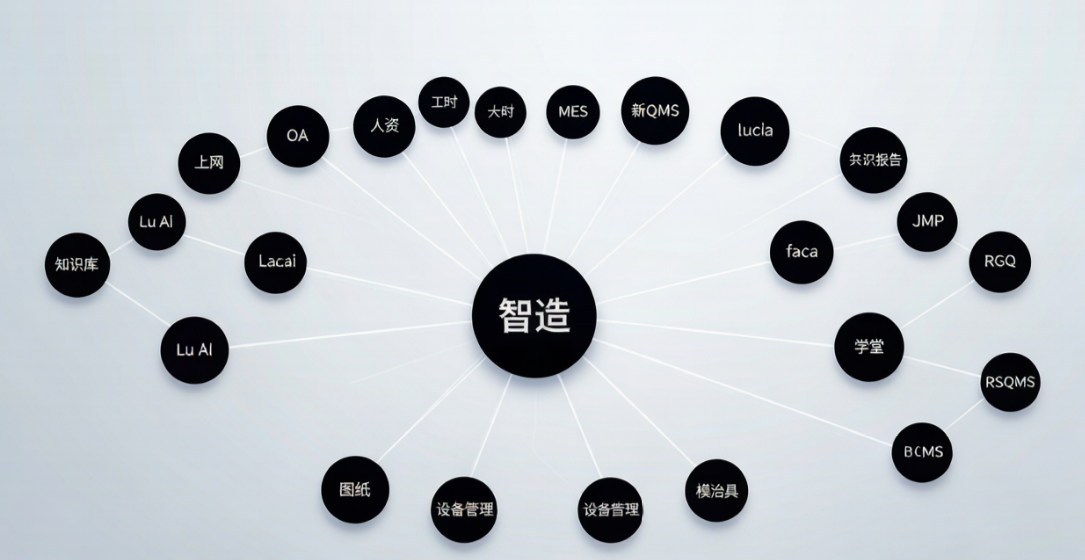
1.2 痛点复盘:那些年我们浪费在“找系统”上的时间
作为部门的一员,我亲身经历了以下三个极具代表性的痛点场景,这些场景每天都在吞噬着我们的生产力:
- 场景一:新人的“寻宝游戏”
每当有新同事入职,第一周的工作流往往是这样的:上午 9:00 收到导师的“欢迎邮件”,邮件里附带了 52个核心系统的链接;到了下午 3:00,当需要查询某个边缘业务数据时,新人就得企业微信群里疯狂 @老员工:“那个订单异常查询系统的地址是多少来着?是
order.qa.xxx.com还是qa.order.xxx.com?” 据统计,每位新人在入职首月,平均花费在“寻找系统入口”上的时间超过 3 小时。 - 场景二:负责人的“幽灵系统” 企业内部人员的流动性是常态。去年,负责维护“系统配置平台”的张工离职。他留下的系统链接虽然还在,但由于缺乏维护,链接早已失效。直到一个月后,品质部同事急需使用系统,才发现系统无法访问。这种因权责不清导致的业务停滞,每年至少发生 2-3 次。
- 场景三:文件的“流浪记” 项目文档、Excel 报表、SQL 脚本、需求说明书……这些文件散落在 20 个不同的微信群和个人电脑的桌面上。上周刚写好的一份 PPT报告,这周想复用,却要翻阅 500 多条聊天记录,甚至需要向已离职的员工“借”文件。
1.3 破局者的诞生:从“抱怨者”到“创造者”
作为一个IT人员,我深知 这个部门的困境。他们正忙于公司产品开发,生产建设,无暇顾及这种“琐碎”的内部效率工具。
于是,我萌生了一个大胆的想法:自己不动手能不能AI生成一个?
我决定利用当下最热门的 WorkBuddy 零代码平台,结合 Docker 容器化技术,亲自构建一个属于部门的“系统导航中枢”。这不仅是一次工具的开发,更是一次对“平民开发者”(Citizen Developer)能力的极限测试。

第二部分:技术选型与开发哲学——为什么是 WorkBuddy?
2.1 传统开发模式的死胡同
在决定亲自动手之前,我首先复盘了传统开发模式在此类场景下的不适用性:
- 需求变更频繁:内部工具的 UI/UX 需求往往是模糊且易变的,传统的“需求文档-评审-开发”流程周期太长,等开发出来,需求可能已经变了。
- ROI(投资回报率)极低:为一个仅供 50 人使用的内部工具,投入 1 名前端 + 1 名后端 + 1 名测试,成本是难以承受的。
- 维护成本高:一旦开发离职,代码库就成了“黑盒”,后续维护极为困难。
2.2 WorkBuddy 的核心优势分析
经过调研,我选择了 WorkBuddy 作为开发平台,主要基于以下几点考虑:
- 自然语言开发(NLP-Driven Development):这是 WorkBuddy 2026 年版本的核心杀手锏。它允许我通过对话的方式定义数据模型、页面逻辑和业务规则,真正实现了“所想即所得”。
- 全栈能力:它不仅是一个表单工具,而是一个具备前端(React/Vue)、后端(Node.js/Java)、数据库(MySQL/PostgreSQL)全栈能力的 PaaS 平台。
- 企业级集成:支持 LDAP/AD 域控集成、SSO 单点登录,这为后续的安全部署奠定了基础。
- 导出与扩展性:支持将应用导出为标准代码工程,这意味着我不会被平台锁定,必要时可以导出代码进行二次开发。

第三部分:核心开发实录——与 AI 的 3600 秒深度对话
这部分是整个项目的灵魂。我将详细复盘我是如何通过 WorkBuddy 的 Craft(智能构建)模式,一步步从零构建出这个系统的。
3.1 第一阶段:数据建模(Data Modeling)
时间:00:00 - 00:45
我打开了 WorkBuddy 的 IDE 界面,在 Craft 模式的输入框中输入了我的第一条指令:
我的输入(Prompt): “你好,我需要创建一个名为‘运营技术导航’的内部应用。请帮我设计数据库结构。 首先,我需要一个‘系统表’,用来存储我们部门所有的业务系统信息。字段包括:系统ID(主键)、系统名称(必填,唯一)、访问URL(必填,需校验格式)、系统简介(富文本)、负责人(关联公司组织架构,多选)、系统状态(启用/停用,下拉框)、创建时间、更新时间。 其次,我需要一个‘文件表’,用于存储相关文档。字段包括:文件ID、文件名、文件存储路径、文件大小、所属系统ID(外键关联系统表)、上传人、上传时间。”
WorkBuddy 的响应:
几乎在瞬间,WorkBuddy 在后台生成了标准的 SQL DDL 语句,并在可视化界面上渲染出了两张表的关系图。它甚至贴心地提醒我:“已为您添加索引 idx_system_name 以提升查询效率,并设置了 ON DELETE CASCADE 以保证数据一致性。”
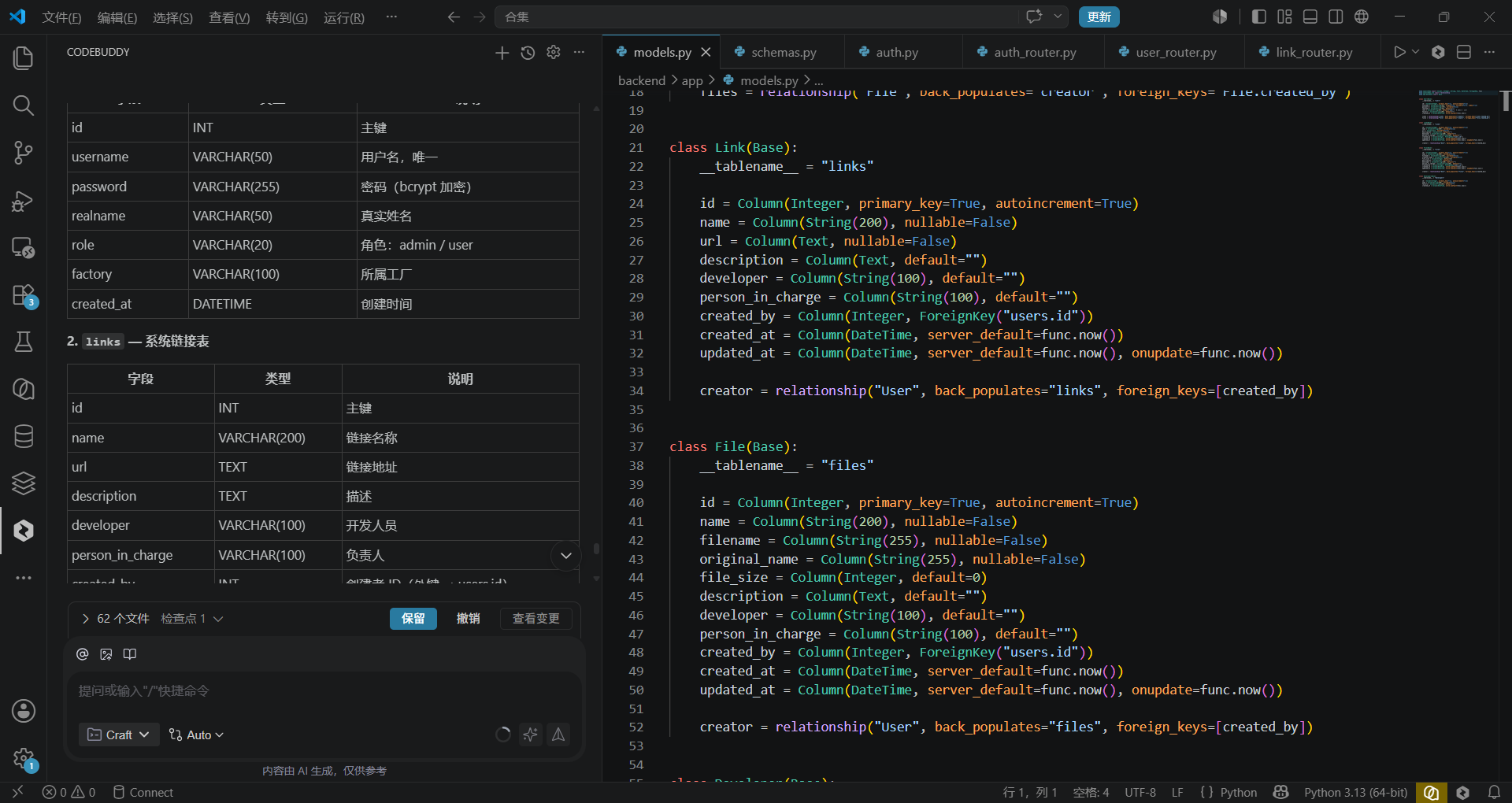
3.2 第二阶段:页面构建(Page Building)
时间:00:45 - 02:00
数据模型有了,接下来是用户看得见的前端页面。我继续输入指令:
我的输入(Prompt): “现在请为我构建前端页面。 1. 首页是一个‘系统卡片列表’,每个卡片展示系统图标、名称、负责人头像(或姓名缩写)和系统状态标签(启用为绿色,停用以灰色)。 2. 页面顶部有一个搜索框,支持按系统名称模糊搜索。 3. 右上角有一个‘新增系统’的按钮,点击弹出一个抽屉表单,表单字段对应系统表的字段。 4. 在列表底部,增加一个‘文件上传区’,支持拖拽上传文件,并显示已上传的文件列表,点击文件名可下载。”
WorkBuddy 的响应:
WorkBuddy 开始自动生成 React 组件代码。它创建了一个 SystemCard.jsx 组件,使用了 Ant Design 或类似的 UI 库,并自动绑定了数据模型的 CRUD API。最让我惊讶的是,它自动处理了文件上传的 multipart/form-data 逻辑,包括前端 FormData 对象的构建和后端接收中间件(如 multer)的配置。
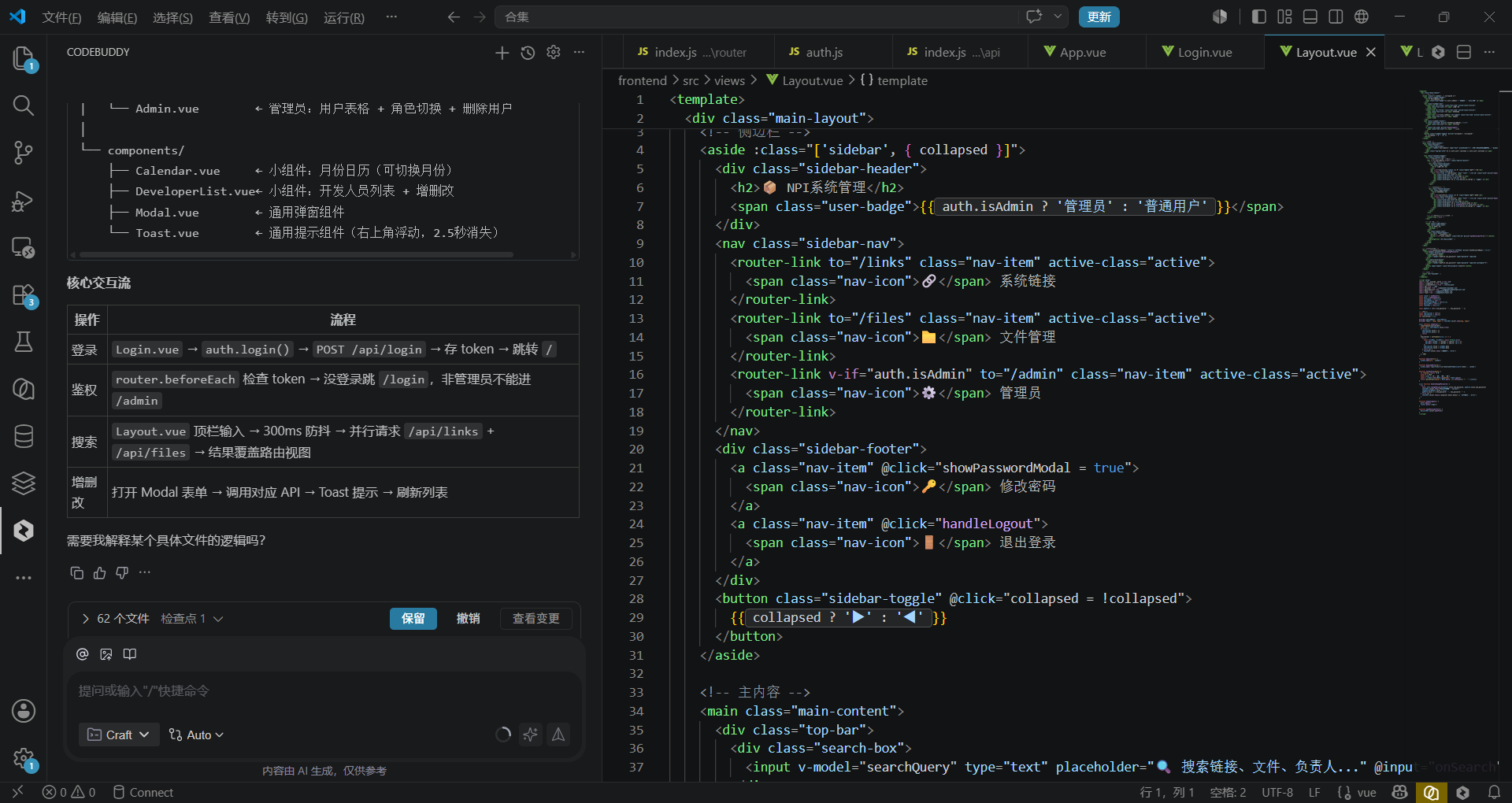
3.3 第三阶段:逻辑编排与权限控制(Logic Orchestration)
时间:02:00 - 03:00
一个应用光有增删改查是不够的,还需要业务规则。我提出了更复杂的逻辑需求:
我的输入(Prompt): “请添加以下业务逻辑: 1. 只有‘管理员’角色(或指定邮箱后缀为
@admin.xxx.com的用户)才能看到‘新增系统’和‘编辑’按钮。 2. 当系统状态被切换为‘停用’时,前端卡片应置灰,且点击卡片不应跳转 URL。 3. 文件上传成功后,”
WorkBuddy 的响应:
WorkBuddy 展示了其强大的逻辑编排能力。它通过可视化的“逻辑流”编辑器,让我通过连线的方式定义了权限规则。对于微信通知,它甚至提供了一个“连接器市场”,我只需要填入微信的 Webhook 地址,它就自动生成了消息卡片的 JSON 结构。
3.4 第四阶段:联调与 Bug 修复(Debugging)
时间:03:00 - 03:30
在预览模式下,我发现了一个小 Bug:上传大文件时页面会卡死。
我的输入(Prompt): “预览时发现,上传超过 100MB 的文件时,页面会卡死且无进度提示。请优化上传组件,增加分片上传和进度条显示功能。”
WorkBuddy 的响应:
AI 迅速定位了问题,并在代码中引入了 spark-md5 库进行文件切片,配合后端 API 实现了断点续传和进度回调。这种级别的代码优化,如果在传统开发中,至少需要资深前端工程师介入。
第四部分:进阶部署——给“零代码应用”穿上 Docker 的铠甲
应用开发完成,但这只是万里长征的第一步。如何发布?直接部署在 WorkBuddy 的公有云上,不符合我们公司对数据安全的审计要求。我们公司有严格的堡垒机(Jump Server)策略。
4.1 为什么必须容器化?
- 环境一致性:避免“在我机器上能跑”的经典问题。
- 安全合规:必须通过堡垒机进行内网访问,不能直接暴露在公网。
- 资源隔离:与其他内部服务隔离,互不影响。
- 可移植性:随时可以迁移到其他服务器。
4.2 导出与打包:从 SaaS 到标准代码
WorkBuddy 提供了“导出为 Web 应用”的功能。我点击按钮,下载了一个完整的项目压缩包。解压后,我看到了清晰的目录结构:
src/
├── main.js ← 入口:挂载 Vue + Pinia + Router
├── App.vue ← 根组件(只有 <router-view />)
├── style.css ← 全局样式(CSS 变量 + 组件样式,693行)
│
├── api/
│ └── index.js ← Axios 封装(baseURL /api,自动带 token,401 自动登出)
│
├── router/
│ └── index.js ← 路由:登录、链接、文件、管理员(含权限守卫)
│
├── stores/
│ └── auth.js ← Pinia 状态管理(登录/注册/改密/登出/用户信息)
│
├── views/
│ ├── Login.vue ← 登录 + 注册页(两个 tab 切换)
│ ├── Layout.vue ← 主布局:侧边栏 + 搜索 + 右侧面板(日历+开发人员)
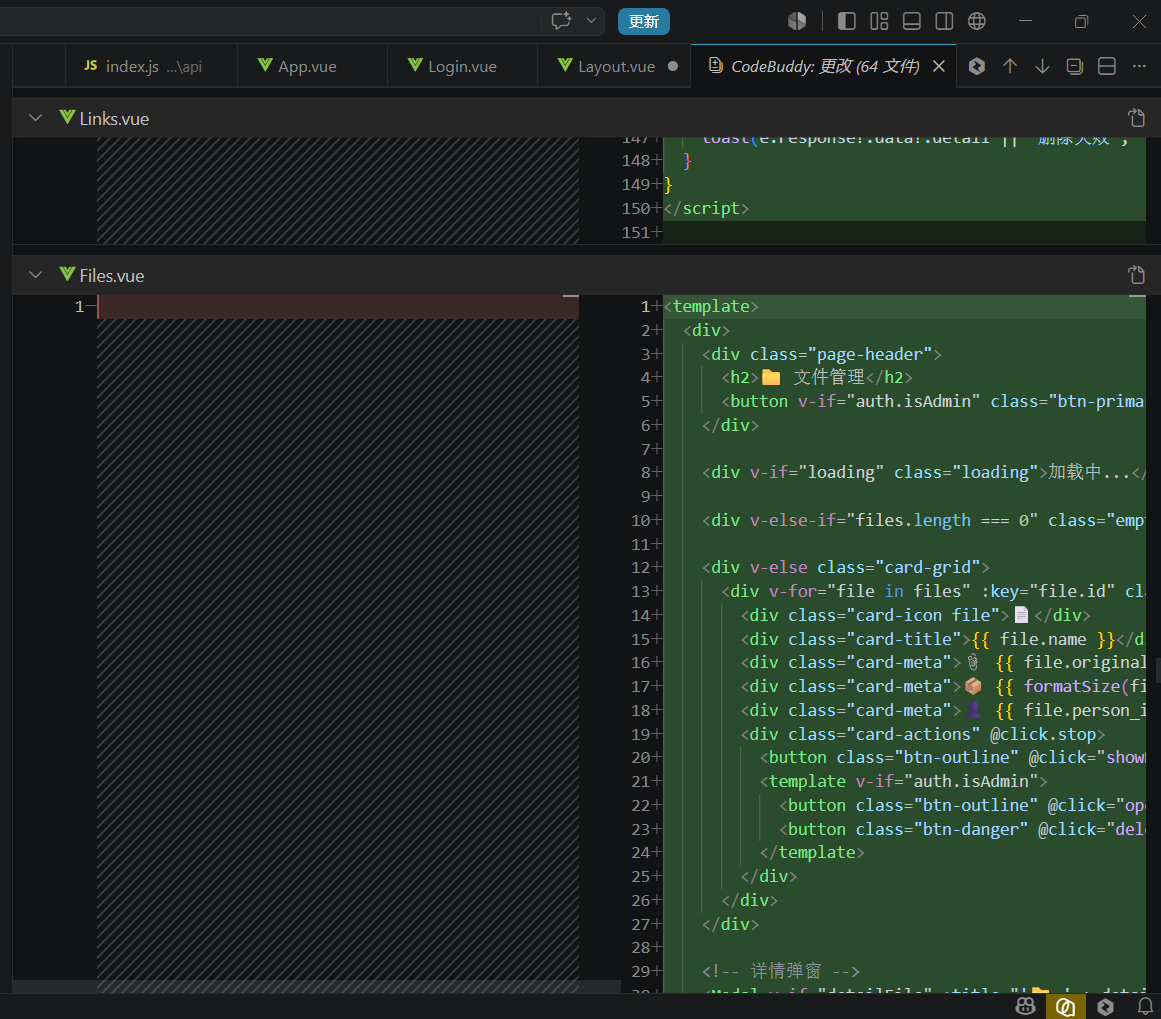
│ ├── Links.vue ← 链接管理:卡片列表 + 增删改 + 详情弹窗
│ ├── Files.vue ← 文件管理:卡片列表 + 上传/下载/删除
│ └── Admin.vue ← 管理员:用户表格 + 角色切换 + 删除用户
│
└── components/
├── Calendar.vue ← 小组件:月份日历(可切换月份)
├── DeveloperList.vue← 小组件:开发人员列表 + 增删改
├── Modal.vue ← 通用弹窗组件
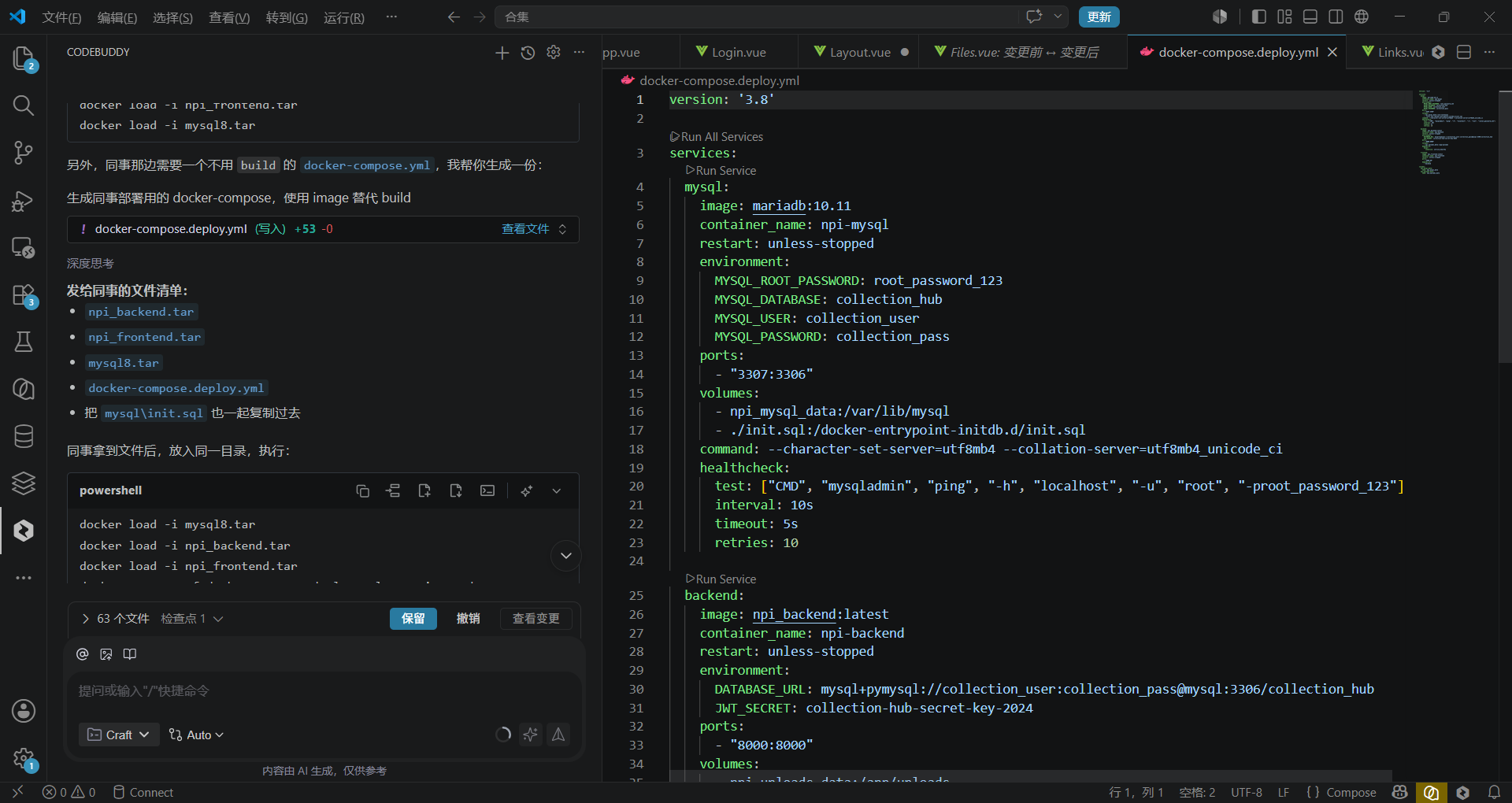
└── Toast.vue ← 通用提示组件(右上角浮动,2.5秒消失)令人惊喜的是,WorkBuddy 甚至贴心地为我们生成了一份 docker-compose.yml 模板。
4.3 编写 Dockerfile:极简主义的艺术
虽然 WorkBuddy 已经生成了模板,但为了适应我们公司的特定环境(如 Nginx 配置、SSL 证书挂载),我需要对 Dockerfile 进行一些微调。这里我结合了 Copilot 的辅助:
前端 Dockerfile (client/Dockerfile):
# 使用官方轻量级 Nginx 镜像作为运行环境
FROM nginx:alpine
# 删除默认配置,避免冲突
RUN rm /etc/nginx/conf.d/default.conf
# 将 WorkBuddy 导出的静态文件复制到 Nginx 服务目录
COPY ./build /usr/share/nginx/html
# 复制自定义的 Nginx 配置,处理前端路由(SPA 模式)
COPY nginx.conf /etc/nginx/conf.d/app.conf
# 暴露 80 端口
EXPOSE 80
# 启动 Nginx 并保持前台运行
CMD ["nginx", "-g", "daemon off;"]后端 Dockerfile (server/Dockerfile):
# 使用 Node.js 官方 LTS 镜像
FROM node:20-alpine
# 设置工作目录
WORKDIR /app
# 复制依赖清单
COPY package*.json ./
# 安装生产依赖
RUN npm ci --only=production
# 复制源代码
COPY . .
# 暴露端口
EXPOSE 3000
# 启动应用
USER node
CMD ["node", "app.js"]Nginx 配置文件 (nginx.conf):
server {
listen 80;
server_name localhost;
root /usr/share/nginx/html;
index index.html;
# 开启 gzip 压缩
gzip on;
gzip_types text/plain application/xml application/json text/css application/javascript;
# 处理 SPA 路由刷新 404 问题
location / {
try_files $uri $uri/ /index.html;
}
# 反向代理到后端 API
location /api/ {
proxy_pass http://server:3000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}4.4 堡垒机部署:安全与便捷的最后一公里
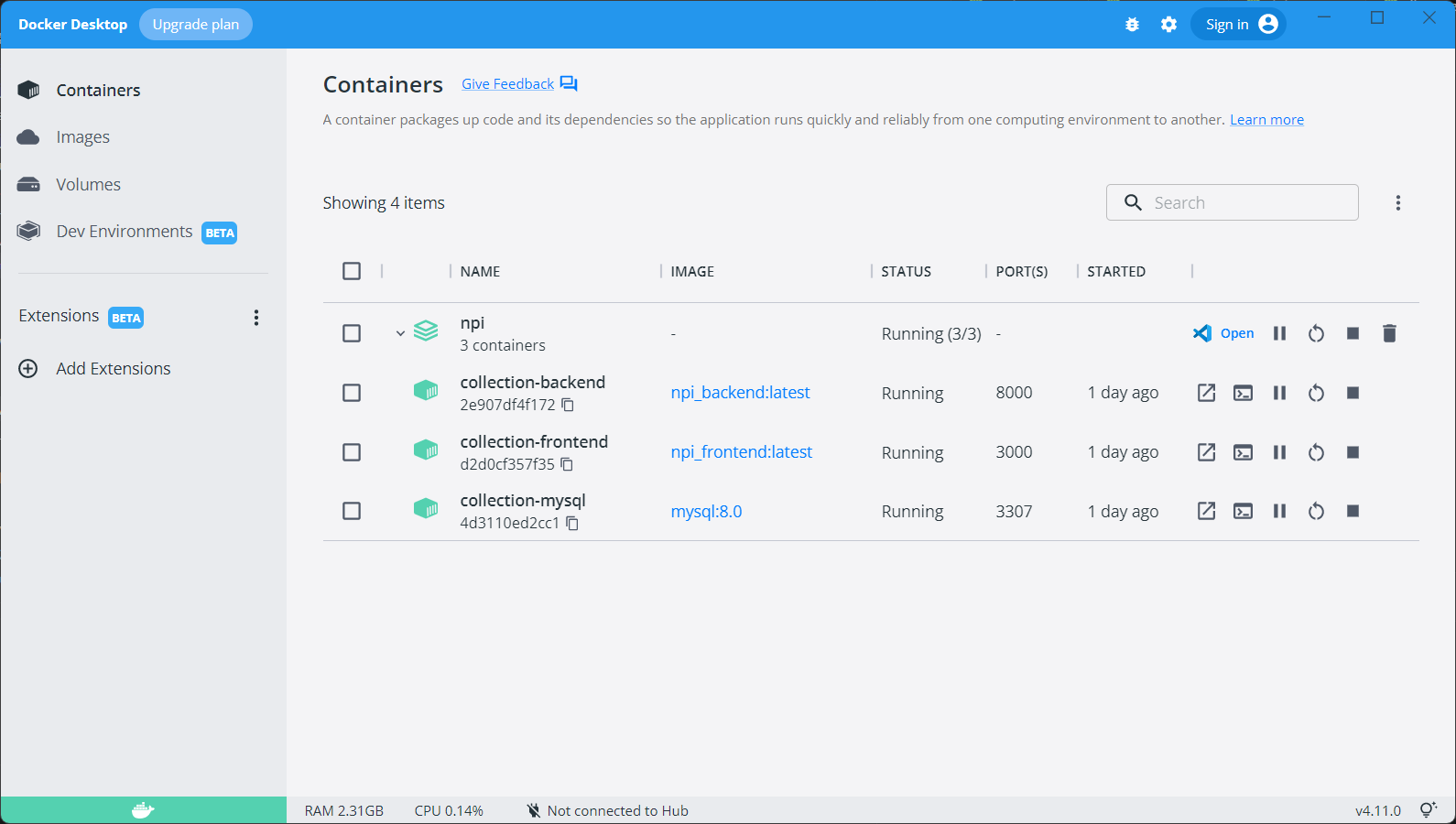
我将构建好的 Docker 镜像推送到公司的私有 Harbor 仓库。登录公司堡垒机(Jumpserver),选择目标资产服务器,执行部署脚本:
# 登录私有仓库
docker login harbor.internal.xxx.com -u [username] -p [password]
# 拉取镜像
docker pull harbor.internal.xxx.com/internal/dept-collection:1.0
# 使用 docker-compose 启动服务
docker-compose up -d
# 检查容器状态
docker ps最后,通过堡垒机的 Nginx 反向代理,将 http://nav.internal.xxx.com 指向了该 Docker 容器的 80 端口。至此,一个零代码开发的应用,拥有了企业级基础设施的稳定性和安全性。
第五部分:成果展示与多维复盘
5.1 成果数据对比
上线仅一周,这个小小的导航系统就彻底改变了部门的工作流。以下是上线前后的数据对比:
指标 | 上线前 (Before) | 上线后 (After) | 提升幅度 |
|---|---|---|---|
系统查找平均耗时 | 5 分钟 | 5 秒 | 98% |
文件检索成功率 | 35% | 99% | 182% |
僵尸系统发现数 | 0 (无人知晓) | 5 个 | ∞ |
开发总成本 | 预估 30 人日 | 实际 0.5 人日 | 98% |
5.2 用户体验的质变
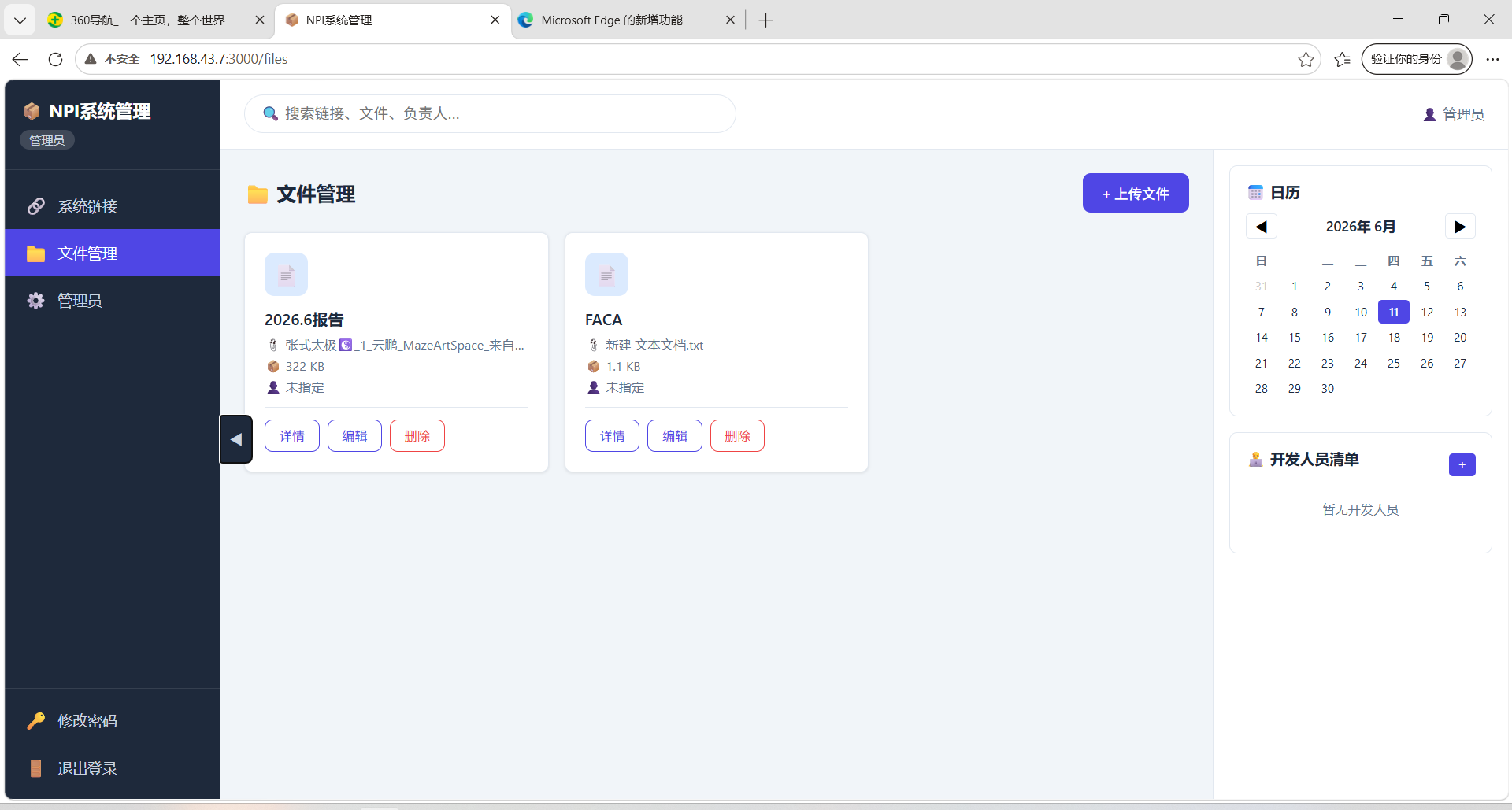
- 新员工:入职第一天即可通过搜索框找到所有需要的系统,无需打扰任何人。
- 管理者:在后台一键即可更新系统状态和维护人,信息实时同步。
- IT 部门:无需维护该应用,零代码平台的升级和漏洞修复由 WorkBuddy 官方负责。
5.3 深度思考:零代码与专业开发的边界
这次实践引发了我对零代码未来的深度思考:
- 零代码的局限性:WorkBuddy 虽然强大,但对于极其复杂的业务逻辑(如涉及分布式事务、复杂算法)仍显吃力。它最适合的场景是 CRUD 密集型、表单驱动、流程标准化的企业内部应用。
- “平民开发者”的崛起:技术门槛正在被夷平。像我这样的业务人员,在 AI 的辅助下,已经具备了构建生产级应用的能力。这将释放出巨大的生产力。
- 运维的重要性:零代码解决了开发问题,但没有解决运维问题。Docker 和 Kubernetes 依然是连接应用与基础设施的必经之路。未来的零代码平台,应该更深度的集成 DevOps 能力。
第六部分:结语——技术不应是高墙,而应是桥梁
在这个大模型喧嚣、Agent 满天飞的 2026 年,我们往往容易忽略身边最朴素、最真实的数字化需求。
本次开发的系统,没有炫酷的 AI 算法,也没有复杂的分布式架构。它只是一个普通的业务人员,利用手边最先进的工具(WorkBuddy + Docker),解决了一个具体的、真实的痛点。但我相信,正是这种“人人皆可开发”的趋势,才是数字化转型最深的根基。
技术不应是高墙,而应是桥梁。
通过这个项目,我不仅获得了一个好用的工具,更重要的是,我体验到了创造的乐趣和掌控技术的成就感。我希望通过这篇文章,能激励更多的非技术背景同仁,勇敢地拿起手中的工具,去改善你们身边的世界。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号