16年76K stars背后:Elasticsearch称霸搜索的5个关键技术决策

16年76K stars背后:Elasticsearch称霸搜索的5个关键技术决策

智能时代蛮子
发布于 2026-06-10 21:15:04
发布于 2026-06-10 21:15:04
GitHub: https://github.com/elastic/elasticsearch
一句话总结
Elasticsearch 是将 Apache Lucene 改造为分布式搜索引擎的标杆项目,通过分片副本、Translog WAL、不可变 ClusterState 等设计,在 16 年间积累了 76K stars,成为企业级搜索、日志分析、AI 向量检索的事实标准。
值得关注的理由
- 分布式系统设计的活教材:Elasticsearch 的分片路由、副本同步、集群协调机制是理解分布式存储的绝佳案例
- 许可证博弈的经典样本:2021 年从 Apache 2.0 转向 SSPL/ELASTIC 双许可证,催生 OpenSearch 分叉,是开源商业化的重要参考
- AI 时代的新增长曲线:2026 年 Agent Builder + ES|QL + 混合向量搜索的组合,使其从日志分析扩展到 RAG 应用基础设施
项目展示
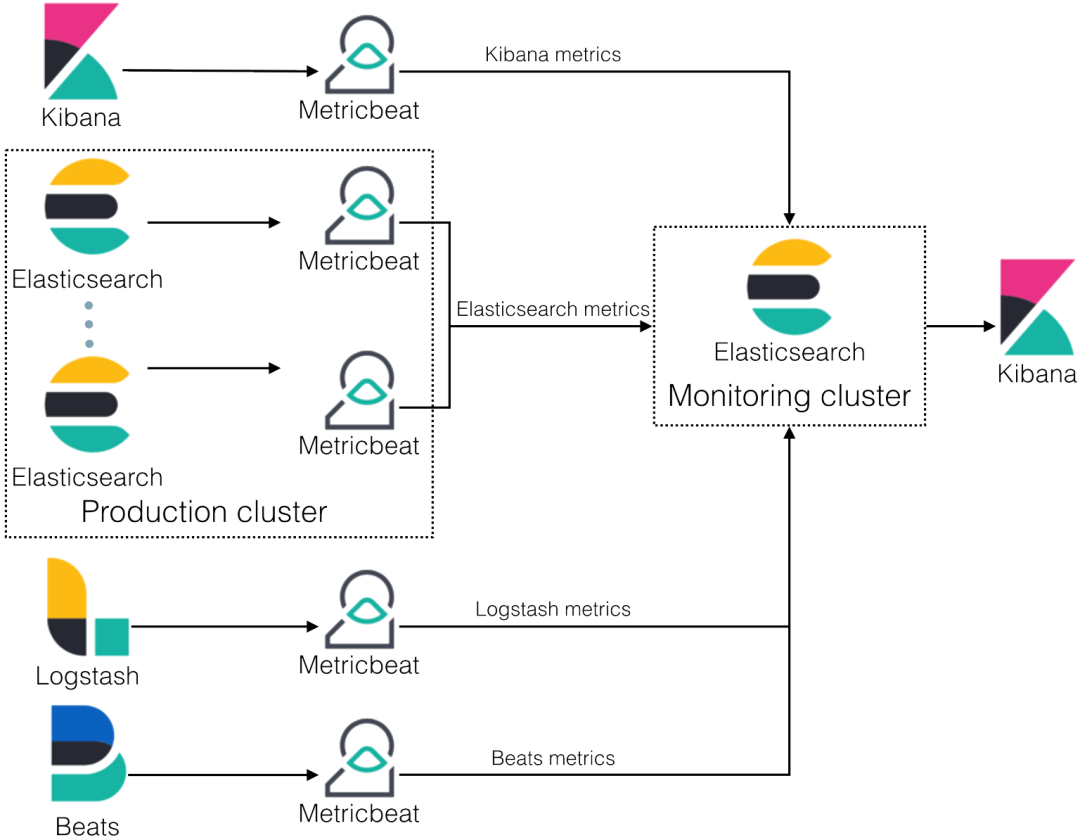
Elasticsearch 分布式架构图
Elasticsearch 节点与分片架构:Primary Shard + Replica Shard 模型实现水平扩展与高可用
项目画像
维度 | 数据 |
|---|---|
GitHub | https://github.com/elastic/elasticsearch |
Star / Fork | 76,777 / 25,950 |
代码行数 | ~110 万行(Java 95%+,核心模块估算) |
项目年龄 | 195 个月(16.3 年,2010-02-08 首次提交) |
开发阶段 | 密集开发(2026 年 4 月创历史新高 1,704 commits/月) |
贡献模式 | 社区驱动(2,367 贡献者,但 Top 10 占 73%) |
热度定位 | 大众热门(76K stars,全球最大开源搜索引擎) |
质量评级 | 代码[优秀] 文档[优秀] 测试[充分] |
作者视角:为什么存在这个项目
创始人/作者背景
Shay Bannon(GitHub ID: kimchy)于 2010 年创立 Elasticsearch: - 领域背景:以色列工程师,Apache Lucene 顶级贡献者,对搜索底层有深刻理解 - 时机选择:2010 年云计算萌芽期,NoSQL 运动启示了分片和副本的数据分布思路 - 公司演进:2012 年成立 Elastic N.V.,2017 年 NASDAQ 上市,定位为"The Search AI Company"
问题判断
Bannon 观察到三个未被满足的需求: 1. Lucene 功能强大但缺乏分布式能力:企业需要从单机扩展到集群 2. 企业搜索市场要么昂贵要么难维护:需要一个开箱即用的方案 3. 云时代需要统一体验:从笔记本到百节点集群都能运行的同一套系统
解法哲学
- 分布式优先:将 Lucene 包装成分片副本模型,写入经 Primary 同步到 Replicas
- RESTful 降低门槛:所有操作通过 HTTP JSON API,curl 即可调用
- 开源核心 + 商业特性:开源版本吸引开发者,x-pack(安全、ML、告警)实现变现
- 实时性保障:Translog(WAL)+ Lucene 写入管道,毫秒级延迟
战略意图
从日志分析栈(ELK)扩展到 AI 应用基础设施: - ELK 生态锁定:Logstash + Kibana + Beats 形成闭环 - 2026 年新方向:Agent Builder + ES|QL + 混合向量搜索,进入 RAG 赛道
核心价值提炼
创新之处
- 分布式 Lucene 抽象 - 将单机 Lucene 改造成水平可扩展的分布式搜索引擎 - 新颖度 5/5 | 实用性 5/5 | 可迁移性 5/5 - 适用场景:所有需要水平扩展的搜索引擎、大规模日志分析系统
- Translog 崩溃恢复机制 - WAL + Lucene 的混合持久化,既保证实时性又确保 durability - 新颖度 4/5 | 实用性 5/5 | 可迁移性 4/5 - 适用场景:需要高写入可靠性的存储系统、日志收集管道
- 向量搜索与全文搜索融合 - 在同一查询引擎中支持 ANN 向量检索(HNSW/IVF)和 BM25 全文检索,评分可混合 - 新颖度 4/5 | 实用性 5/5 | 可迁移性 3/5 - 适用场景:RAG 应用的多模态搜索(文本+向量)
- 跨集群搜索(CCS) - 跨集群、跨索引的统一查询接口,federated search 能力 - 新颖度 4/5 | 实用性 5/5 | 可迁移性 3/5 - 适用场景:多数据中心、多租户场景
- ES|QL 统一分析语言 - SQL-like 管道语言,支持向量化的列式执行引擎 - 新颖度 3/5 | 实用性 5/5 | 可迁移性 2/5 - 适用场景:复杂数据分析、安全事件调查、时序数据处理
可复用的模式与技巧
- 不可变状态 + Diff 传播:集群状态管理 — 适用场景:[分布式协调、心跳检测]
- WAL + 准实时索引:持久化写入 — 适用场景:[消息队列、时序数据库、存储引擎]
- 分片路由 + 副本同步:水平扩展 — 适用场景:[分布式缓存、数据分片、多租户]
- RESTful 统一入口:API 设计 — 适用场景:[微服务网关、多语言客户端、SDK]
- HNSW/IVF 向量索引:ANN 检索 — 适用场景:[推荐系统、图像搜索、RAG]
关键设计决策
- 分片副本模型(Shard-Replica) - 问题:如何实现水平扩展和数据高可用 - 方案:Primary + Replica,写入经 Primary 同步到 Replicas,使用 seq_no 跟踪一致性 - Trade-off:写入延迟 vs 可用性;eventually consistent 模型缓解一致性 vs 性能矛盾 - 可迁移性:高(适用于所有分布式存储系统)
- Translog(WAL)+ Lucene 混合持久化 - 问题:Lucene 刷新间隔默认 1 秒,如何保证 durability - 方案:Translog 作为 WAL,先写日志(fsync)再刷 Lucene segments - Trade-off:写入放大(双重写入) vs 零数据丢失 - 可迁移性:高(LSM-tree、PostgreSQL WAL 均采用类似模式)
- ClusterState 不可变数据结构 - 问题:集群状态如何在节点间高效传播 - 方案:ClusterState 不可变,通过 Diffable 接口计算增量 diff,仅传输 delta - Trade-off:内存占用(每次变更创建新对象) vs 网络传输效率 - 可迁移性:高(分布式系统状态同步通用模式)
竞品格局与定位
竞品对比矩阵
维度 | Elasticsearch | OpenSearch | Meilisearch | Qdrant | Apache Solr |
|---|---|---|---|---|---|
Stars | 76,777 | 13,022 | 57,889 | 31,707 | 1,619 |
语言 | Java | Java | Rust | Rust | Java |
分布式 | 原生 | 原生 | 有限 | 云原生 | 有限 |
向量搜索 | ✅ +全文 | ✅ +全文 | ✅ +全文 | ✅ 仅向量 | ✅ |
许可证 | SSPL/ELASTIC | Apache 2.0 | MIT | Apache 2.0 | Apache 2.0 |
生态 | ELK 全家桶 | AWS 支持 | 轻量生态 | 纯向量 | 成熟但老旧 |
目标用户 | 企业级 | 企业级(许可敏感) | 中小型 | AI/RAG | 企业级(传统) |
差异化护城河
- ELK 生态锁定:Logstash + Kibana + Beats 形成闭环,迁移成本极高
- ES|QL 统一分析:SQL-like 管道语言,统一搜索 + 分析 + 向量
- AI Agent 集成:Agent Builder + Workflows GA,2026 年 5 月随 v9.4 发布
- 全球最大社区:16 年积累、2,367 贡献者、350+ 集成
竞争风险
- OpenSearch 分叉:AWS 背书,Apache 2.0 许可证,对许可敏感的企业首选
- Qdrant 等向量专用库:Rust 原生优化,专注向量检索精度
- 许可证争议:SSPL/ELASTIC 双许可可能继续流失对开源敏感的用户
生态定位
Elasticsearch 是企业级"搜索即平台",从日志分析栈(ELK)扩展到 AI 应用基础设施(RAG)。它填补了"单机 Lucene 无法满足企业级扩展性"的市场空白,并通过 ELK 生态形成了难以复制的护城河。
套利机会分析
- 信息差:AI Agent 时代的新增长曲线(Agent Builder、混合向量搜索)尚未被主流技术社区充分认知
- 技术借鉴:分片副本模型、Translog WAL、不可变状态 diff 传播可直接迁移到其他分布式系统
- 生态位:作为 RAG 应用的核心向量存储,对接 LangChain、LlamaIndex 等 AI 开发框架
- 趋势判断:搜索即平台战略 + AI 集成,2026 年 v9.4 发布显示持续创新能力,优于大多数停滞的老牌项目
风险与不足
- 许可证风险:SSPL/ELASTIC 双许可持续争议,部分云厂商和开发者转向 OpenSearch
- 资源消耗:110 万行 Java 代码,JVM 内存开销大,入门门槛较高
- 复杂性:分布式系统的运维复杂度(分片调优、集群扩缩容、故障恢复)不容忽视
- 向量搜索后发:纯向量库(Qdrant、Pinecone)在向量检索性能上更专注
行动建议
- 如果你要用它:中小企业选 Meilisearch(极简);企业级选 Elasticsearch(功能完整 + ELK 生态);RAG 场景可考虑 Qdrant(向量性能)或 ES(统一平台)
- 如果你要学它:重点关注
server/src/main/java/org/elasticsearch/index/shard/IndexShard.java(Translog 机制)、server/src/main/java/org/elasticsearch/cluster/ClusterState.java(不可变状态)、x-pack/plugin/src/main/java/org/elasticsearch/xpack/esql/(ES|QL 引擎) - 如果你要 fork 它:OpenSearch 是现成的 Apache 2.0 fork,但需评估长期维护成本
知识入口
资源 | 链接 |
|---|---|
DeepWiki | https://deepwiki.com/elastic/elasticsearch |
Zread.ai | 未收录 |
关联论文 | 无特定 arXiv 论文(基于 Lucene 的学术研究可追溯) |
在线 Demo | https://www.elastic.co/downloads/elasticsearch + Elastic Cloud 免费试用 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号