首字延迟降低3.6倍,腾讯混元提出Stem稀疏注意力算法,长文推理加速新SOTA

首字延迟降低3.6倍,腾讯混元提出Stem稀疏注意力算法,长文推理加速新SOTA

小腾资讯君
发布于 2026-06-10 09:04:06
发布于 2026-06-10 09:04:06
当你把一篇数万字的长文档丢给大语言模型,点击发送后,是否经历过漫长的等待?光标闪烁,模型却迟迟不吐出第一个字——这段"等待第一个字"的过程,就是所谓的 预填充(Prefill)阶段。
它背后的瓶颈,是 Transformer 自注意力的二次方计算复杂度:输入越长,预填充越慢,且呈平方级增长。
稀疏注意力(Sparse Attention) 是当下最主流的破局方向:只计算"重要"的 token,把不必要的算力省掉。
然而从算法到算子,现有方案都存在明显短板。算法上:一是对所有位置"一刀切"地分配相同稀疏预算,忽视了因果架构中初始 token 的递归依赖特性;二是只看注意力分数来挑 token,忽略了 Value 向量本身携带的信息量。算子上还有一道隐形门槛:再聪明的稀疏模式,如果底层算子无法真正高效地跳过被稀疏丢弃的块,加速比也会大打折扣。
针对以上问题, 腾讯混元提出 Stem 稀疏注意力算法,已被机器学习顶会 ICML-26 收录——它从"因果信息流"重新审视块级稀疏,用 Token 位置衰减(TPD) 和 输出感知度量(OAM) 两大创新,仅用 25% 算力就逼近稠密注意力的精度。配套的 HPC 算子库则将这份理论加速比真正转化为端到端的实测性能。
- Stem论文链接:https://arxiv.org/abs/2603.06274
- Stem开源地址:https://github.com/Tencent/AngelSlim
- HPC算子开源地址:https://github.com/Tencent/hpc-ops
Stem 算法:从"信息流"重新理解稀疏注意力
1. 核心洞察:初始token是信息流的"树干"
Stem的名字来源于"树干"的隐喻——在因果注意力架构中,初始位置的token如同一棵树的主干,支撑着所有后续信息的传递。
为什么初始token如此重要? 在因果自注意力中,每一层的计算遵循严格的因果约束:第 $l$ 层第 $n$ 个位置的输出,由该层前 $n$ 个位置的Value向量加权聚合而来($O_n^{(l)} = \sum_{j=1}^{n} P_{n,j}^{(l)} V_j^{(l)}$),而这些Value向量又源自上一层的输出经映射得到。这意味着:
· 位置1的Value $V_1^{(l)}$:出现在本层每一个位置的输出计算中($O_1^{(l)}, O_2^{(l)}, \dots, O_N^{(l)}$)
· 位置N的Value $V_N^{(l)}$:仅参与本层最后一个位置 $O_N^{(l)}$ 的计算
这种不对称性在多层Transformer中被递归放大。初始token的信息经由 $V^{(l)} \to O^{(l)} \to V^{(l+1)}$ 的路径层层传递,最终嵌入到深层网络的每一个表示中。如下图所示,一旦在某一层注意力稀疏掉初始token $V_1$,误差将沿红色虚线路径扩散至下一层的所有token;而稀疏掉末尾token $V_N$,影响仅局限于最后一个位置(红色实线)。
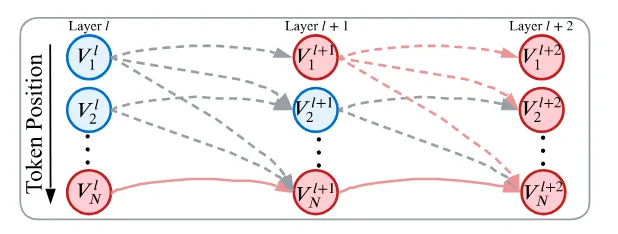
图片
2. 实战验证:Stem 全栈加速效果
讲完了"为什么初始 token 重要",你可能会问:这个发现,最终在生产环境里到底能跑出什么样的数字?
我们没有停留在学术 BenchMark,而是把 Stem 直接集成进腾讯混元 Hy3 preview(W8A8-FP8) 的 vLLM 推理框架,搭配 HPC 团队优化的 Stem 算子,端到端测量首字延迟(TTFT)与模型精度——这意味着 Stem 不仅要在 BF16 学术基线上跑得通,还要在量化后的工业级模型上稳得住。
至于 Stem 与其他稀疏算法在开源模型上的速度/精度对比,论文中已给出完整结果,本文不再赘述。
下面看 Stem 在 Hy3 preview(W8A8-FP8)上更贴近生产环境的真实落地数据。
2.1 首字加速比
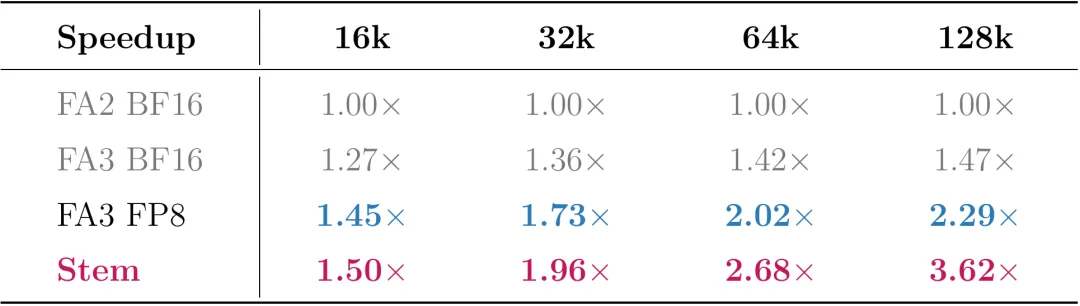
图片
2.2模型精度
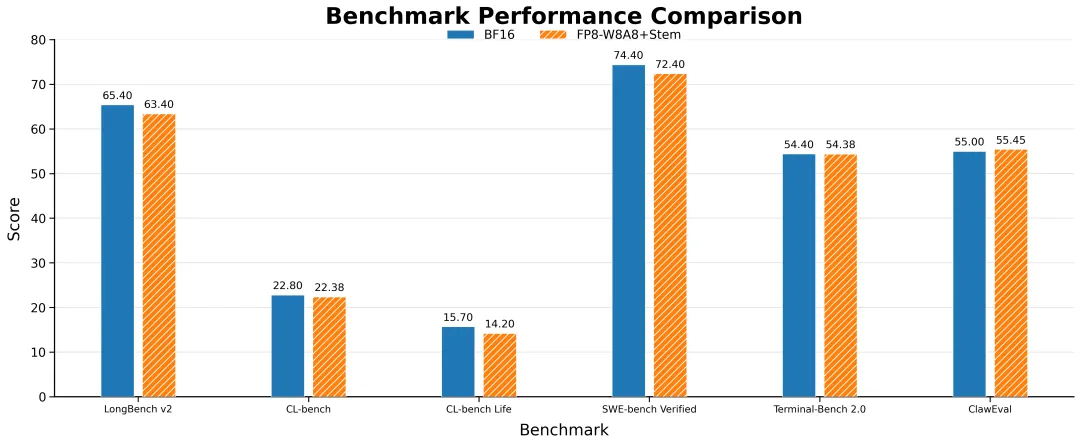
图片
3.揭秘:Stem 凭什么又快又准?
数字摆在这里,问题就来了——Stem 是怎么在砍掉 75% 计算的同时,还把精度保住的?
答案藏在两个看似简单、却被以往工作长期忽视的细节里:给谁多一点预算?挑 token时该看什么?Stem 的两大核心创新——Token 位置衰减(TPD) 和 输出感知度量(OAM)——分别回答了这两个问题。
3.1 Token 位置衰减策略(TPD):重新分配预算,而非增加预算
现有方法对所有位置施加统一的Top-$k$ 预算——这是一种"一刀切"的策略,完全忽视了上述位置敏感性差异。
Stem提出线性衰减的预算分配:
· 初始位置:分配较大预算 $k_{\text{start}}$,充分保留递归依赖链上的关键token
· 末尾位置:预算线性衰减至 $k_{\text{end}} = \mu \times k_{\text{start}}$(默认 $\mu=0.7$),对冗余信息激进剪枝
关键在于:TPD并不增加总计算量,而是在相同预算下重新分配资源,将计算集中在信息流的关键节点上。
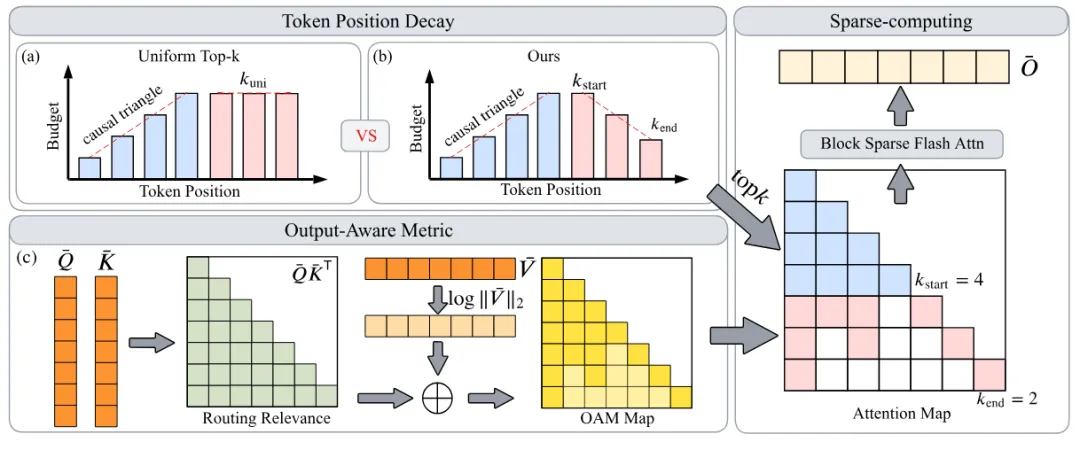
图片
Stem整体流程图。(a)为传统Uniform Top-$k$ 的均匀预算分配,(b)为TPD的衰减式分配,直观展示了预算如何向初始位置倾斜。
3.2 输出感知度量(OAM):不只看"路由分数",更看"信息贡献"
预算分配定了,接下来的问题是:在预算内,选哪些 token?
传统方法只用注意力分数(Query 和 Key 的点积)来挑 token,但 Stem 指出一个常被忽视的事实:分数高 ≠ 实际贡献大——一个 token 可能与 Query 很相关,但它的 Value 向量幅值接近零,对输出几乎无贡献;反过来,分数中等但 Value 幅值很大的 token,才是真正的"信息富矿"。
注意力的本质是加权求和,一个 token 的真实贡献其实是 路由概率 × 信号幅值。Stem 据此提出输出感知度量(OAM):
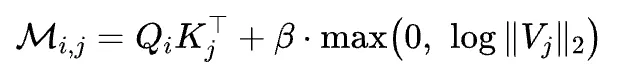
图片
通过对数变换把"乘法"转成"加法",排序结果不变,又能直接套用标准 Top-$k$ 算子,几乎零开销。
至此,Stem 算法层面的全貌已经清晰:TPD 决定"给谁多一点",OAM 决定"在那一点里挑谁",一前一后,把稀疏注意力从"一刀切"升级到了"看信息流决定稀预算"。
但算法选得再准,最终能不能在 GPU 上真的跑出 3.6×,还得看底层算子是不是配合得上。下一节,我们将介绍 HPC 算子。
算子优化:HPC-Stem + HPC-BSA
现有算子实现的挑战
块级稀疏注意力的计算分为两个阶段:评估选块(评估每个block的重要性并记录结果)和稀疏执行(按评估结果跳过不重要的block,只对选中的执行注意力计算)。在现有生态中,这两个阶段都存在瓶颈。在评估选块的流程中,现有主流方法依赖softmax归一化,带来额外的gather操作和FP8 GEMM精度误差,需要维护较大的中间张量(128K下可达16 GB)。在稀疏注意力计算过程中,已有的开源BSA算子需要动态的判断哪些块是否跳过,带来较为显著的跳块开销。
HPC优化:我们做了什么
针对上述两个瓶颈,我们分别设计了两个核心算子:HPC-Stem将评估选块流程加速数十倍,HPC-BSA面向Hopper架构将稀疏算法的理论加速比真正落地。
1)Stem算子优化:
HPC-Stem的评估流程分为OAM评分和TPD选块两步。对于OAM评分,我们发现其纯加法的度量结构(不依赖softmax和gather)允许一个关键的数学简化:原始实现中对采样后的Q/K做全量矩阵乘法产生的中间张量,可以等价转化为先预计算Q和K各自的紧凑block级别表示,再用一次标准GEMM直接得到全部block评分,计算量降低约64倍,中间张量完全消除。对于TPD选块,我们将预算的生成和选块排序的逻辑融合为一个算子,显著提高了评估速度。
2)BSA算子优化:
HPC-BSA针对Hopper架构从头设计,采用数据搬运与计算并行的流水线架构,原生支持vLLM的Paged KV Cache和FP8量化(计算吞吐翻倍)。
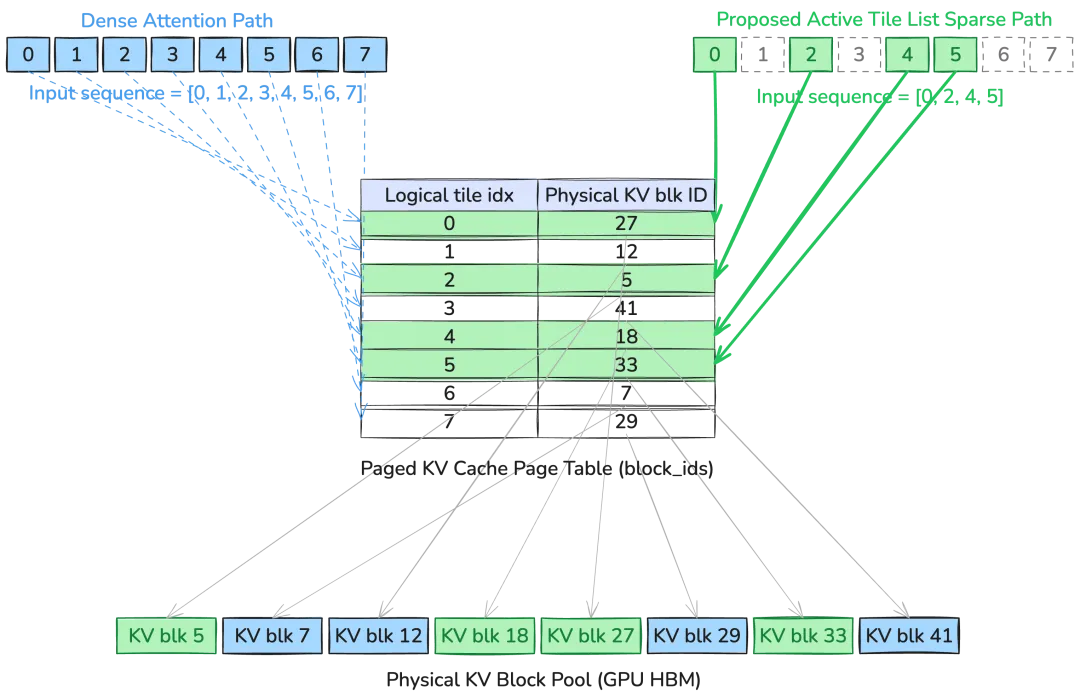
图片
在此基础上,块级稀疏的支持自然融入。如上图所示,经过分页的KV Cache本就是非连续的、逐页加载的。对于稀疏场景,kernel在处理每个Q分块时,先将对应的block mask缓存到片上高速存储,并在线构建出需要计算的KV分块列表。内层循环只遍历这些有效分块,完全避免了逐次判断跳过带来的额外开销。被跳过的分块在数学上等价于注意力分数全为负无穷,不影响softmax的正确性,计算逻辑无需任何修改。
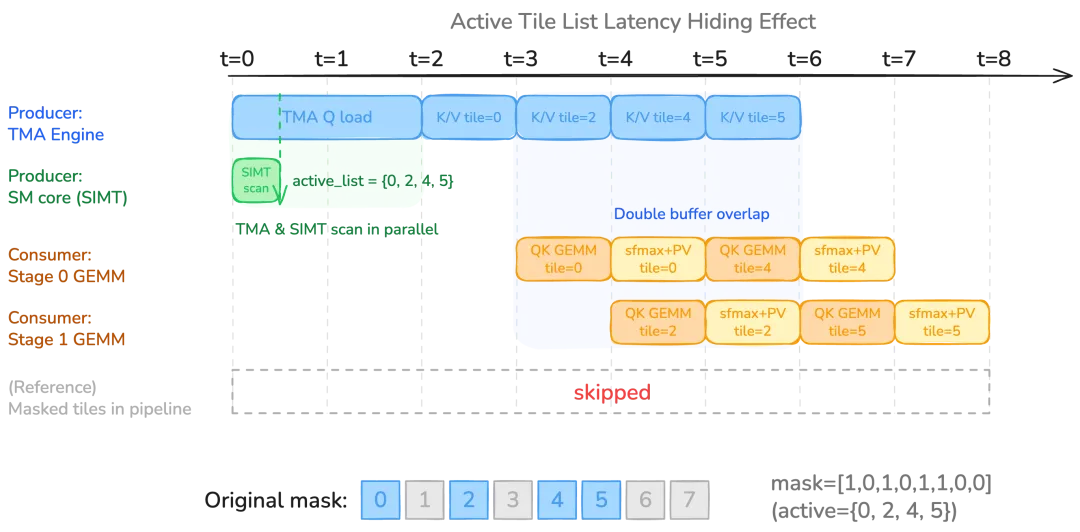
图片
如上图所示,相比MIT原版算子中逐步查询索引、计算偏移的跳块流程,HPC-BSA将稀疏的判断和筛选完全前置到循环之外,内层计算路径与稠密Attention几乎一致,实现了近零开销的块级跳过。
Benchmark:算子级性能
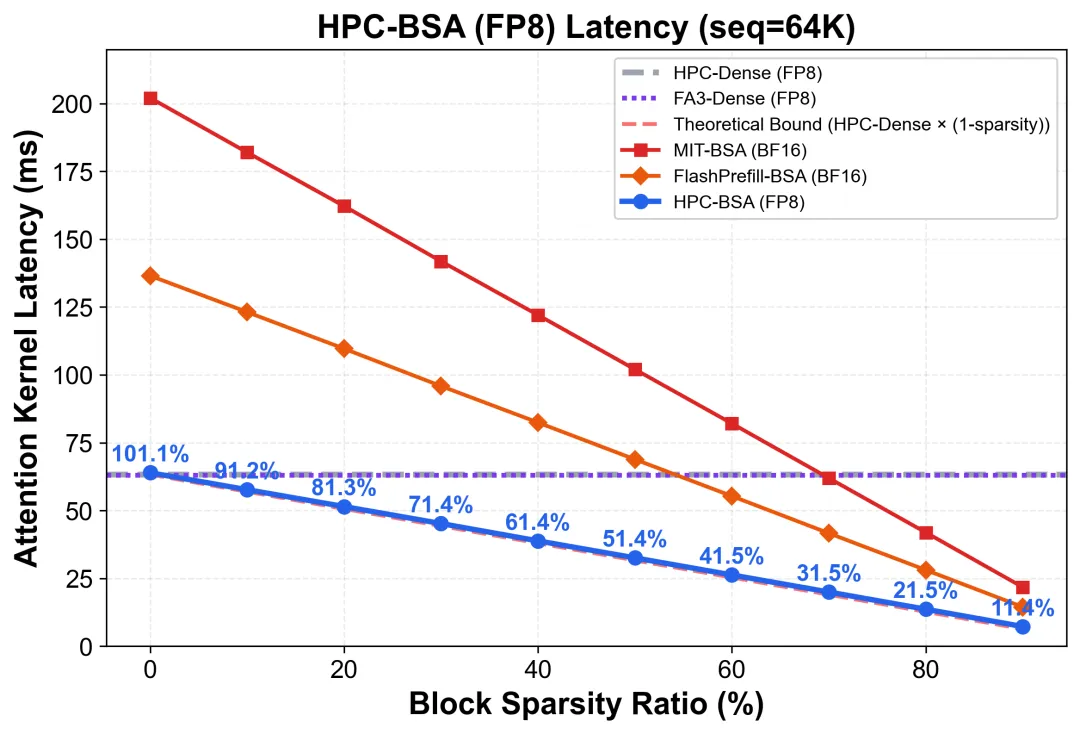
我们对HPC-BSA算子进行了性能测试,以HPC-Dense (FP8)和FlashAttention V3 (FP8)作为稠密基线,以MIT-BSA (BF16)和FlashPrefill-BSA (BF16)两个主流开源实现作为稀疏对照。
结果揭示了三个关键发现。第一,HPC-BSA的延迟与计算密度呈近乎完美的线性关系:50%稀疏度下延迟约为稠密基线的一半,80%稀疏度下仅为约五分之一,跳块机制的额外开销控制在2.5%以内,算法的理论加速比被几乎完整地转化为实测性能。第二,HPC-BSA相比MIT开源的BSA算子(MIT-BSA)在全稀疏度范围内稳定保持约3倍加速,该收益来自FP8计算吞吐优势与Hopper架构优化的叠加。第三,上述优势在8K到256K的全序列长度范围内保持稳定,展现出良好的长序列扩展性。
不同稀疏度 (block sparse ratio) 下,BSA算子延时的变化:
图片
不同稀疏度下 HPC-BSA (FP8) 的延迟与稠密基线对比。标注百分比为 HPC-BSA 延迟占 HPC-Dense 的比例。淡红虚线为理论的最快速度上限(HPC-Dense × density)。
64K输入下,不同稀疏度 (block sparse ratio) 下HPC-BSA算子与主流开源BSA算子加速比,HPC-BSA相比MIT-BSA (BF16) 在全稀疏度范围内稳定保持约3.1倍加速,相比于FlashPrefill (BF16) 稳定~2.1倍加速
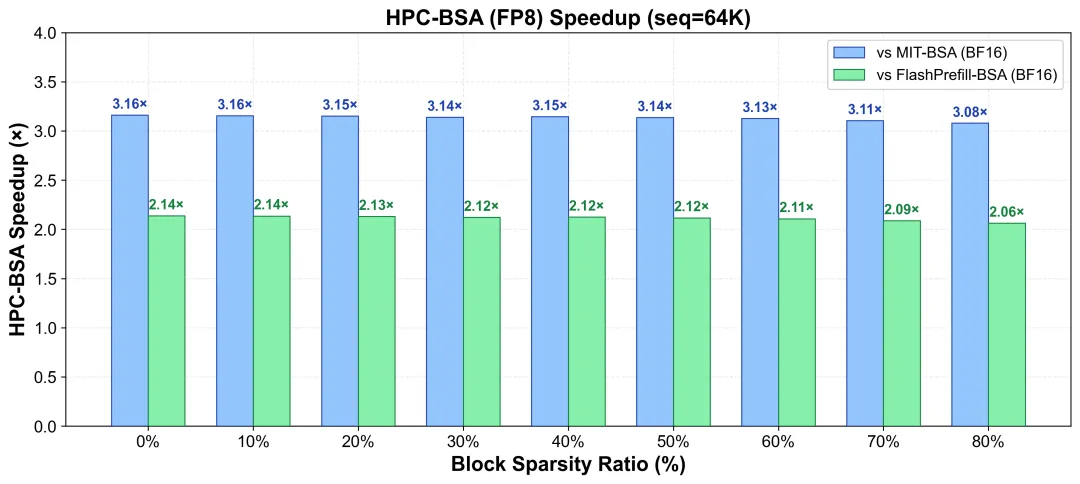
图片
75% 稀疏度下,不同序列长度下 HPC-BSA相比主流开源BSA算子的加速比,相较于两个基线同样保持了较稳定的效果
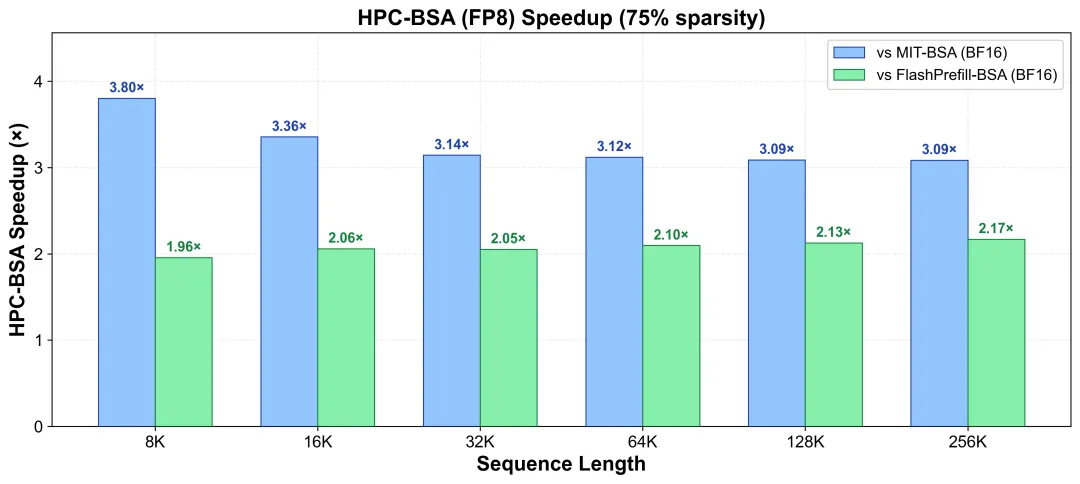
图片
总结与展望
本文介绍了 Stem算法 × HPC算子 的全栈加速方案:算法层面,Stem通过Token位置衰减(TPD)和输出感知度量(OAM)实现25%预算下的近无损精度;算子层面,HPC开源的Stem+BSA算子将稀疏收益转化为真实硬件加速,128K上下文下首字延迟降低3.7倍。
算法决定"省哪些计算",算子决定"省下的计算能快多少"——两者协同,构成从理论到部署的完整闭环。
随着大模型上下文窗口持续扩展至百万级别,高效的长文本推理将成为刚需。我们期待这一"算法+算子"的思路能为长文本高效推理提供新的范式参考。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号