从 MySQL 到 KingbaseES:Database、Schema、User 一次讲透
原创
从 MySQL 到 KingbaseES:Database、Schema、User 一次讲透
原创
一只牛博
发布于 2026-06-08 18:46:54
发布于 2026-06-08 18:46:54
先准备一个普通用户 app_user 和一个数据库 app_db。如果按 MySQL 的习惯看,很容易把事情理解成:连上 app_db,表就建在 app_db 下面。
这个理解在日常口头表达里问题不大,但继续写 SQL 时会很快遇到麻烦。KingbaseES 里,连接目标、对象命名空间、登录用户是三件事:
database:连接到哪个数据库
schema:表、视图、函数这些对象放在哪个命名空间
user/role:当前是谁在执行操作MySQL 里经常把 database 当作命名空间使用,写 db_name.table_name 很常见。KingbaseES 这里更需要先适应 schema.table 这层关系。不把这件事分清楚,后面很容易出现表明明存在却查不到、同一个表名查到的不是预期数据、换个用户以后对象显示不一样这些问题。
这不是概念洁癖。开发时最常见的低级问题,往往不是 SQL 函数不会用,而是连错库、建错位置、查错对象。MySQL 里执行 use app_db; 以后,再 show tables;,心里通常会默认“当前库里的表就在这里”。到了 KingbaseES,连接到 app_db 以后,还要多看一层:当前 schema 是谁,默认对象查找顺序是什么。
如果只做一个简单表,这个差别不明显。一旦开始做迁移、按模块拆 schema、给不同用户分配对象,差别就会变得很具体。一个库里可能有 public.t_order,也可能有 archive.t_order、report.t_order。不带 schema 前缀的 select * from t_order 到底查哪张表,不能只靠表名判断。
下面的实验只用两个对象名:一个普通用户 app_user,一个数据库 app_db。表名也故意复用 t_schema_demo,让它分别出现在 public 和 app_schema 下面。这样能把问题压到最小:同一个 database、同一个 user、同一个表名,只因为 schema 和 search_path 不同,查询结果就会变。
当前连接里不只有数据库名
先用普通用户连接数据库:
ksql -h 127.0.0.1 -p 54321 -U app_user -d app_db进入 ksql 后查三个值:
select current_database(), current_user, current_schema();
show search_path;返回结果里,当前数据库是 app_db,当前用户是 app_user,当前 schema 是 public。search_path 是:
"$user", public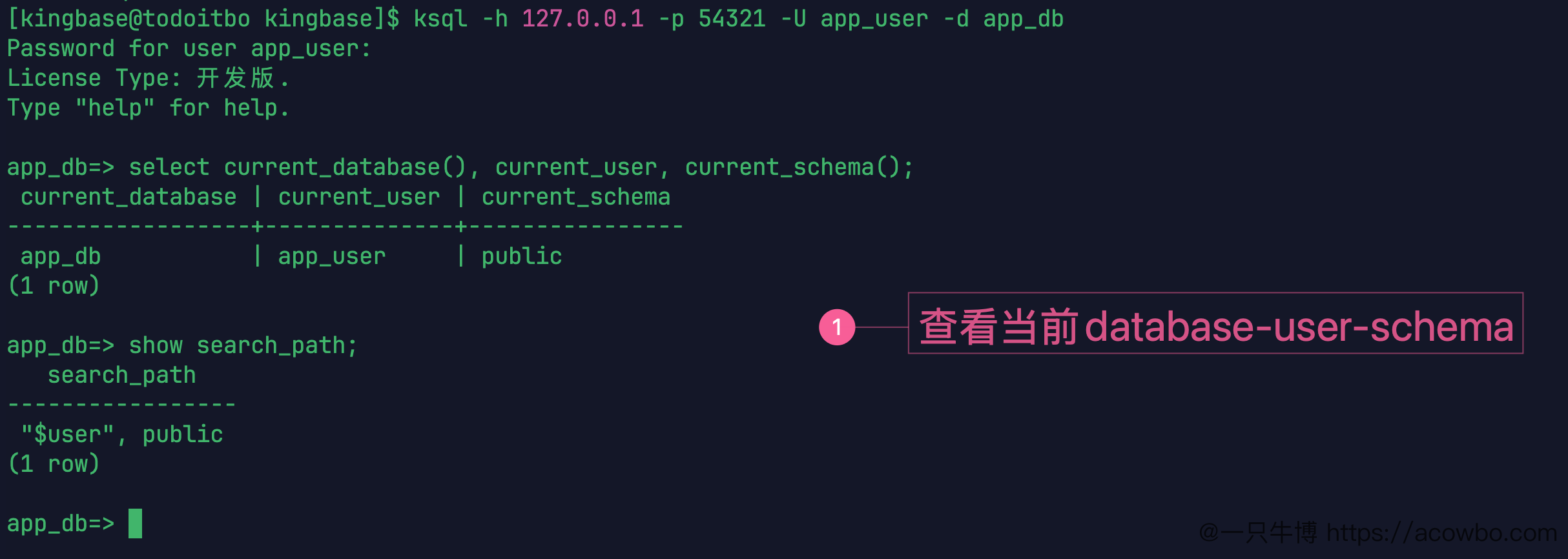
查看当前 database user schema
这里已经能看到几个概念被拆开了。连接命令里的 -d app_db 只决定当前 database;登录命令里的 -U app_user 决定当前用户;真正不写前缀建表时会落到哪里,还要看当前 schema 和 search_path。
"$user", public 的意思是:先尝试找和当前用户同名的 schema,再找 public。当前环境里没有 app_user 这个 schema,所以 current_schema() 返回的是 public。
这一步对 MySQL 用户很关键。连到 app_db 不等于后面所有对象都直接挂在 app_db 这一层,表还会属于某个 schema。
可以把这组信息拆成一句话:app_user 以某个用户身份连接到了 app_db,当前默认会在 public schema 里创建和查找对象。三个值分别回答三个问题:
current_database() 当前连接哪个数据库
current_user 当前用哪个用户执行
current_schema() 当前默认使用哪个 schemashow search_path; 则回答另一个问题:没写 schema 前缀时,数据库按什么顺序找对象。这个配置不只是显示信息,它会直接影响建表和查表。
不写 schema,表会落到默认位置
直接建一张表:
drop table if exists t_schema_demo;
create table t_schema_demo(id int, name varchar(50));
insert into t_schema_demo values (1, 'from default schema');再用 \dt 和 \d 看对象:
\dt
\d t_schema_demo同时查系统视图:
select schemaname, tablename, tableowner
from sys_tables
where tablename = 't_schema_demo';结果很直接,t_schema_demo 在 public 下,owner 是 app_user。
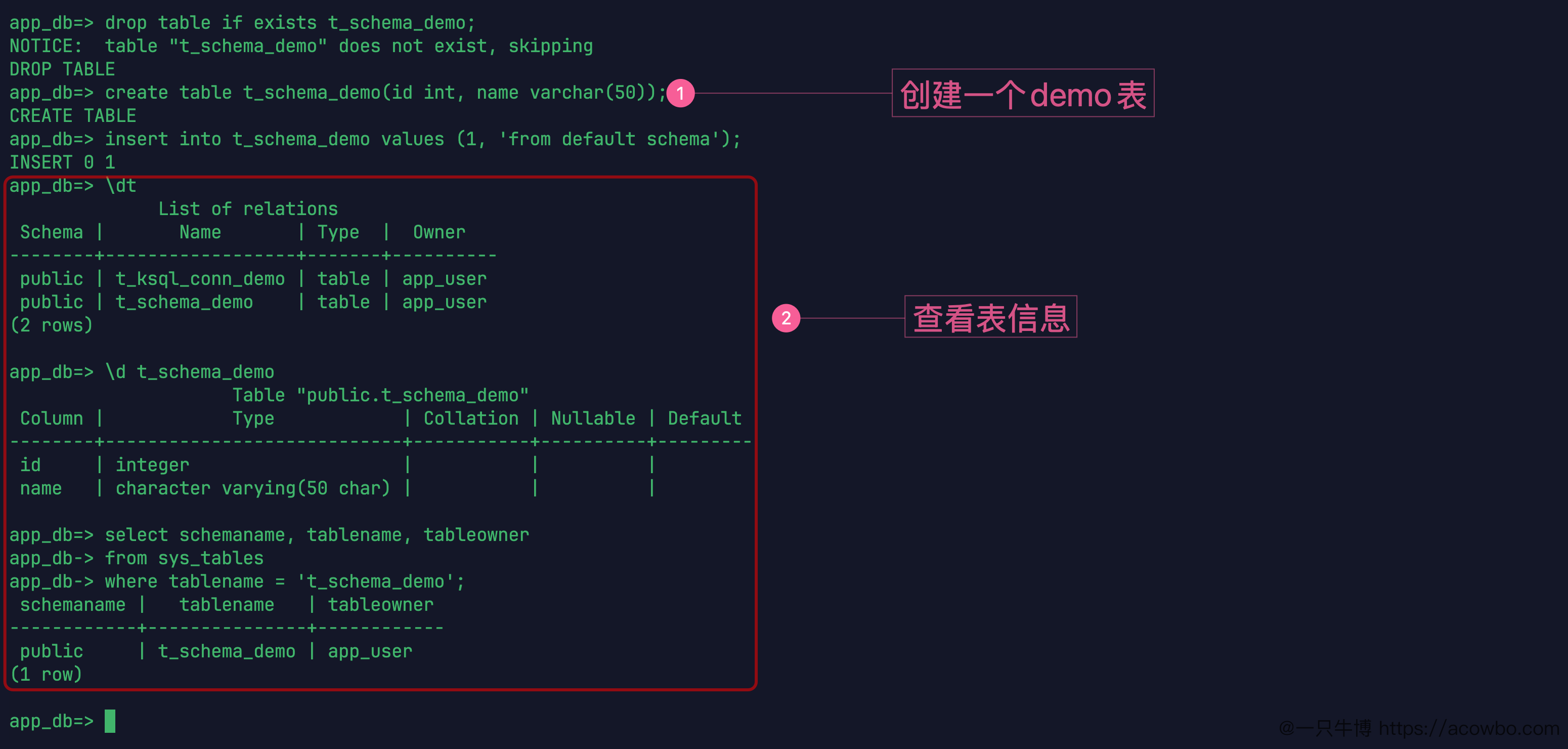
默认 schema 下建表
这就是 search_path 生效后的结果。建表语句没有写 public.t_schema_demo,但当前默认 schema 是 public,所以表落到了 public。
换成 MySQL 习惯时,这里最容易想当然:已经连上 app_db,所以表就在 app_db 里。更准确的说法应该是:当前连接在 app_db,表对象属于 app_db 里的 public schema。
也就是说,database 是更外层的连接边界,schema 才是对象命名空间。后面写 select * from t_schema_demo 时,如果不带 schema 前缀,数据库会按当前搜索路径去找。
这里的 \dt 也能看出问题。它列出来的不只是表名,还有 schema。当前结果里,已有的 t_ksql_conn_demo 和这次新建的 t_schema_demo 都在 public 下,owner 都是 app_user。这说明“谁创建”和“建在哪个 schema”也是两回事:当前用户是 app_user,对象 owner 是 app_user,但对象所在 schema 是 public。
写 DDL 时最好先确认这三件事。只知道“当前连的是 app_db”还不够,至少还要知道默认 schema 是什么。否则以后清理对象时,可能会发现同一个库里散着多个 schema,表名也不一定唯一。
再建一个 app_schema
接着创建一个新的 schema:
create schema app_schema authorization app_user;再查当前数据库里关心的 schema:
select schema_name
from information_schema.schemata
where schema_name in ('public', 'app_schema');结果里能看到 public 和 app_schema。
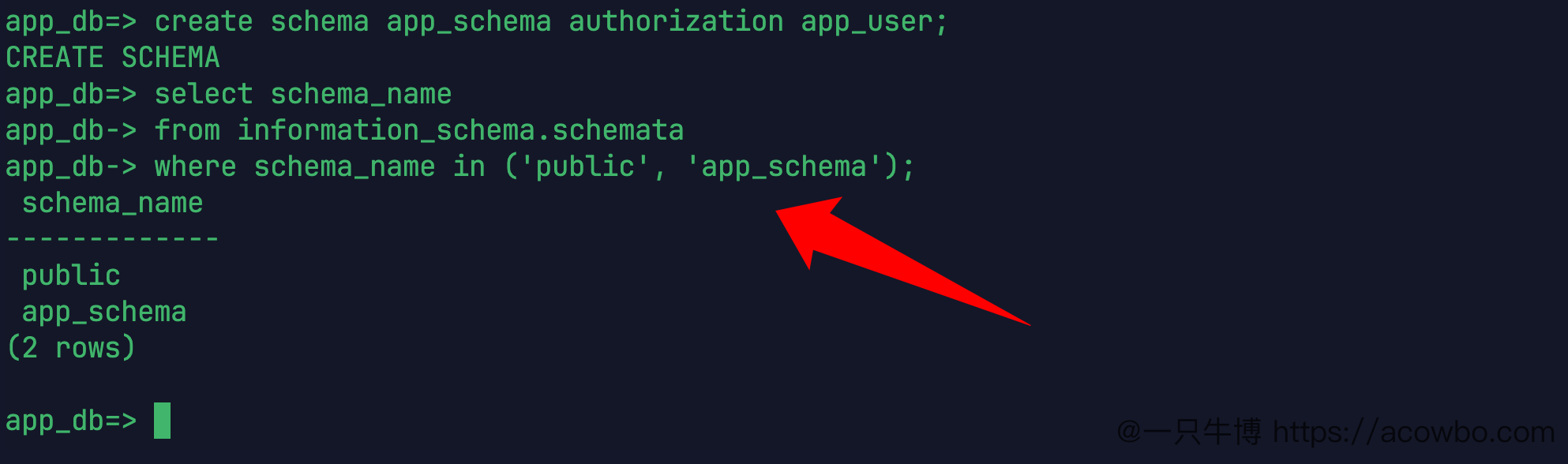
创建 app_schema
app_schema 不是新数据库,它只是 app_db 里的一个命名空间。authorization app_user 表示这个 schema 归 app_user 所有。
这一步不用先展开权限体系。先抓住一点就行:同一个 database 里可以有多个 schema。表名、视图名、函数名这些对象名,都是在 schema 这一层组织的。
authorization app_user 也不是随手加的装饰。它让 app_schema 这个命名空间归 app_user 所有。后面在这个 schema 下建表时,逻辑就更接近日常开发:普通用户连接自己的数据库,在自己的 schema 里放对象。完整权限还可以继续细分,这里先把对象层级跑通。
在真实项目里,schema 常用来做隔离。比如一个库里放业务表、报表表、中间表,或者迁移时先把旧系统对象放到单独 schema。这样不需要每个模块都拆成一个独立数据库,也能避免对象名互相撞在一起。
同一个 database 里可以有同名表
现在显式把表建到 app_schema 下:
create table app_schema.t_schema_demo(
id int,
name varchar(50)
);
insert into app_schema.t_schema_demo values (2, 'from app_schema');再查 information_schema.tables:
select table_schema, table_name
from information_schema.tables
where table_name = 't_schema_demo'
order by table_schema;结果里出现了两行:
app_schema | t_schema_demo
public | t_schema_demo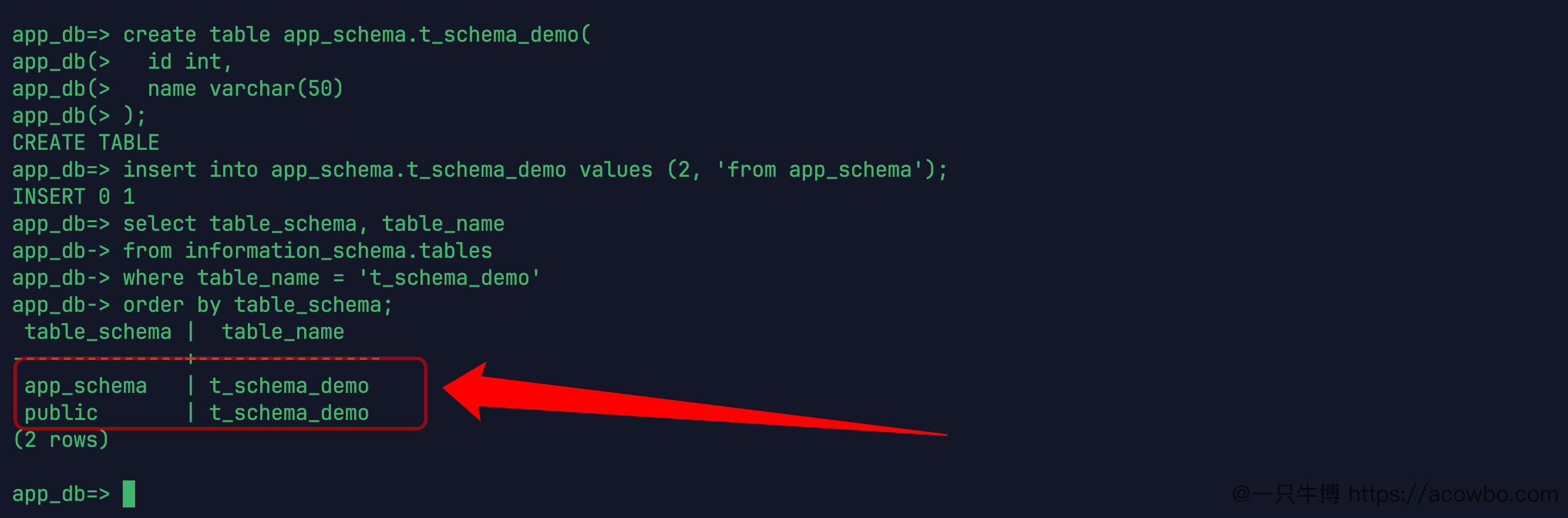
不同 schema 下的同名表
这就是 schema 的作用。同一个 app_db 里,public.t_schema_demo 和 app_schema.t_schema_demo 可以同时存在。它们名字一样,但完整对象名不一样。
这和 MySQL 里常见的 database.table 直觉不一样。在 KingbaseES 里,写到对象层面时,更常见的是:
schema_name.table_name如果只写表名,数据库不会凭空知道想查哪一个 schema 下的表,它会按 search_path 的顺序找。
同名表实验很适合用来打断 MySQL 里的一个惯性:同一个“库”里表名必须唯一。这里并不是同一个 schema 里允许同名表,而是同一个 database 里不同 schema 允许同名对象。完整对象名分别是:
public.t_schema_demo
app_schema.t_schema_demo这两个名字完整写出来以后,就不冲突了。后面做 SQL 排查时,如果只看到一个裸表名,不要马上以为它指向唯一对象。先查对象归属,再看搜索路径。
加上 schema 前缀,目标就明确了
分别查询两张同名表:
select * from public.t_schema_demo;
select * from app_schema.t_schema_demo;前一张表里是:
1 | from default schema后一张表里是:
2 | from app_schema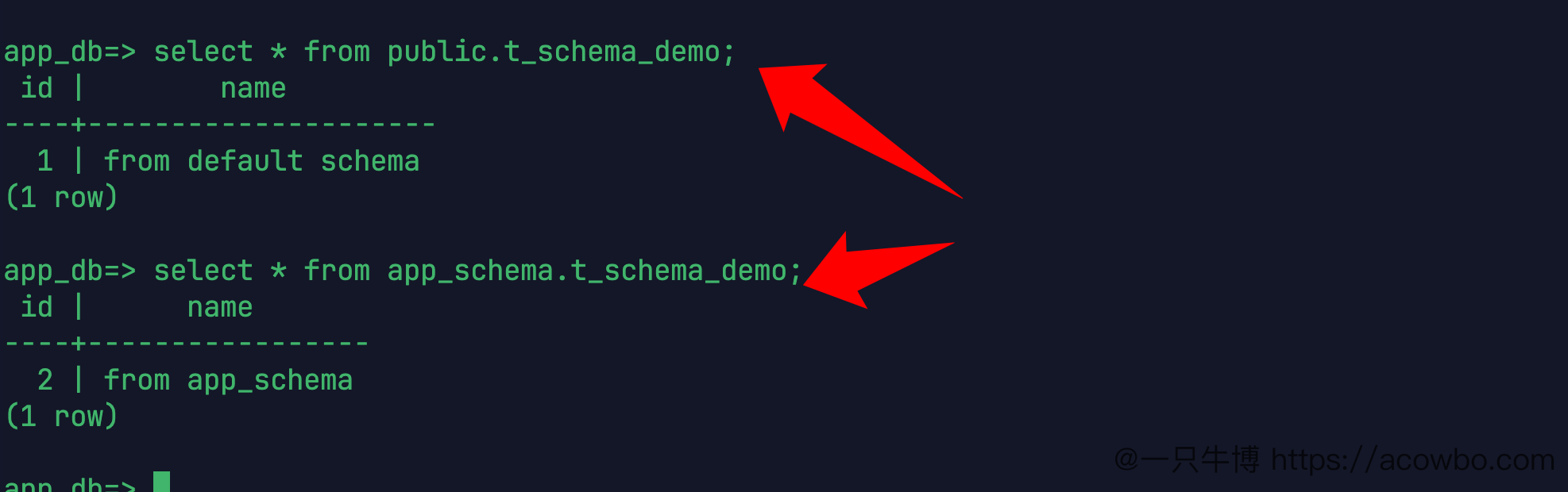
使用 schema 前缀查询同名表
加上 schema.table 前缀以后,查询目标很明确,不受当前 search_path 顺序影响。
平时写业务 SQL 时,不一定每条都要带 schema 前缀。很多项目会通过默认 schema 或连接参数把环境固定下来。但在排查问题、写迁移脚本、做跨 schema 查询时,显式写出 schema 能少很多歧义。
有几种场景最好直接写全名:迁移脚本、初始化脚本、定时任务、跨 schema 查询、临时排查 SQL。这些 SQL 往往会在不同账号、不同终端、不同工具里执行,不能假设每次会话的 search_path 都一样。写成 app_schema.t_schema_demo 虽然长一点,但现场更清楚。
尤其是多人共用测试库时,写清 schema 能避免很多无意义的来回确认,也方便后面清理对象和复盘问题。
这也是迁移时很容易踩的点。MySQL 里从 db1.table1 改到 KingbaseES,不一定能机械改成 database.table。更常见的处理是:连接到目标 database,然后把对象放进指定 schema,再用 schema.table 来访问。具体怎么设计,要看项目是否需要多 schema、是否要保留原库名、是否要隔离临时迁移对象。
search_path 会影响未加前缀的查询
现在不带 schema 前缀,直接查:
select * from t_schema_demo;这条 SQL 查哪张表,取决于当前 search_path。
先把 app_schema 放到前面:
set search_path to app_schema, public;
show search_path;
select * from t_schema_demo;返回的是 app_schema.t_schema_demo 里的数据:
2 | from app_schema再把 public 放到前面:
set search_path to public, app_schema;
show search_path;
select * from t_schema_demo;返回变成 public.t_schema_demo 里的数据:
1 | from default schema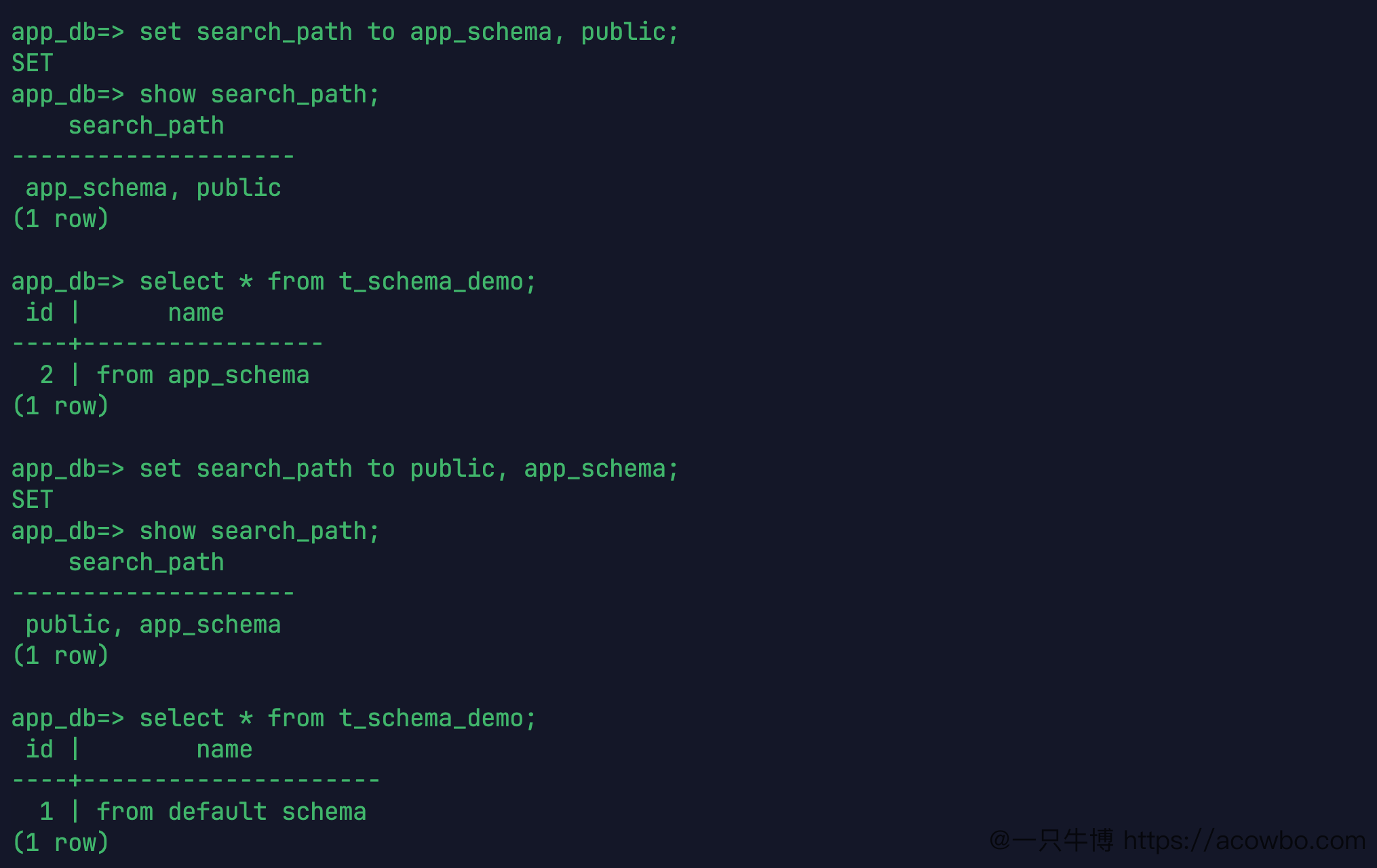
search_path 影响未加前缀查询
这一步能解释很多看起来很怪的问题。表存在,查询也没报错,但结果不是预期那张表的数据,原因可能不是 SQL 写错,而是未加前缀的表名被 search_path 解析到了另一个 schema。
开发阶段如果只有一个 schema,问题不明显。一旦出现多 schema、迁移临时 schema、按用户隔离 schema,search_path 就会变得很重要。
这个实验里,两次查询的 SQL 都是:
select * from t_schema_demo;SQL 文本没有变化,结果却变了。变化来自前面的:
set search_path to app_schema, public;
set search_path to public, app_schema;这类问题在日志里也不好一眼看出来。只看业务 SQL,会以为查的是同一张表;把当时会话里的 search_path 补上,才能解释结果为什么不同。所以排查“查错表”时,show search_path; 应该和 current_database()、current_user 一起看。
换成 system,再看同一个 app_db
退出 app_user 后,换 system 连接同一个数据库:
ksql -h 127.0.0.1 -p 54321 -U system -d app_db再查当前位置:
select current_database(), current_user, current_schema();结果变成:
app_db | system | public继续查 t_schema_demo 的归属:
select table_schema, table_name
from information_schema.tables
where table_name = 't_schema_demo'
order by table_schema;仍然能看到:
app_schema | t_schema_demo
public | t_schema_demo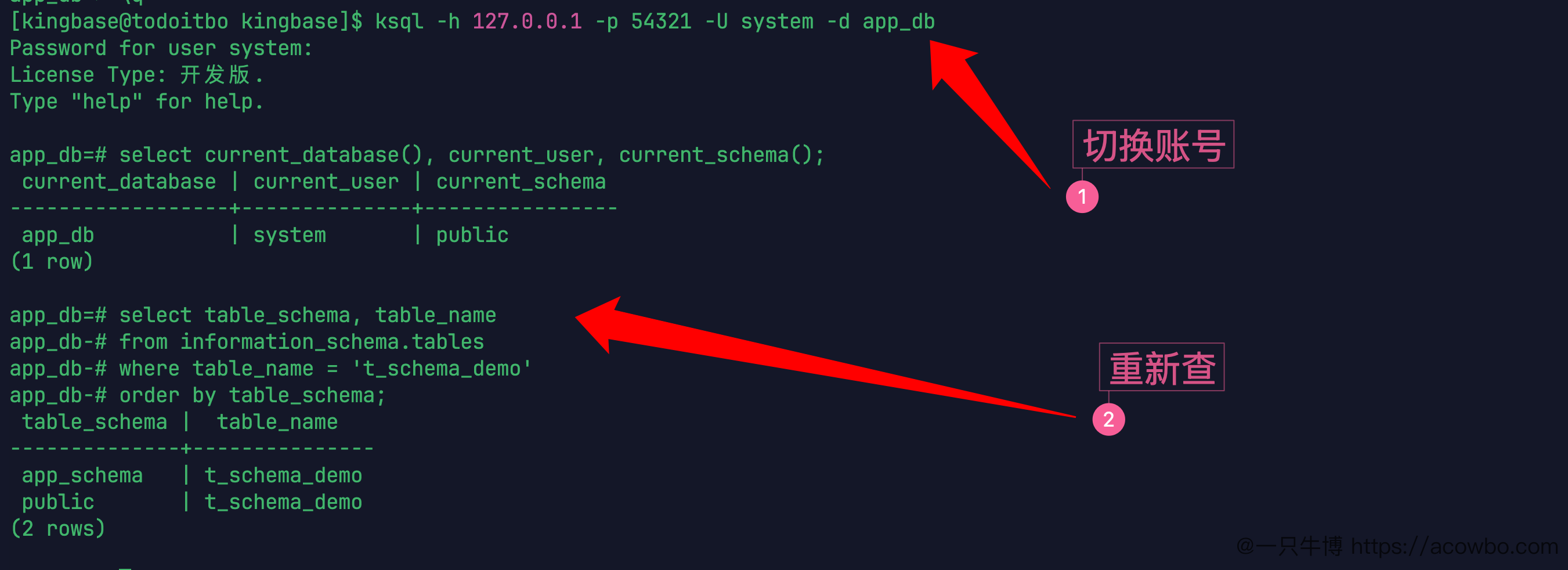
system 查看同一数据库对象
换用户不等于换数据库,也不等于把对象搬到别的 schema。system 只是换了当前执行 SQL 的身份,连接目标仍然是 app_db,对象仍然在 public 和 app_schema 下面。
这里先不展开授权。只看这一组结果已经足够说明:database、schema、user 不是一个概念。
换成 system 后,current_user 变了,但 current_database() 仍然是 app_db,对象归属也没变。这能把 user 和 database 的边界讲清楚。用户不是数据库,数据库也不是用户。用户只是当前会话执行 SQL 的身份,它会影响能不能看、能不能改、默认 schema 怎么解析,但不会因为换用户就把同一个数据库里的对象改名或搬走。
这也是为什么不建议长期拿管理员用户做日常实验。管理员用户能看到更多东西,也能绕过一些权限限制。用它排查问题可以,拿它模拟普通应用连接就不准确。准备 app_user 和 app_db,就是为了让这些实验更接近日常开发账号。
和 MySQL 的习惯对一下
如果从 MySQL 过来,可以先用下面这张对照表调整直觉:
MySQL 常见理解 KingbaseES 里要拆开看
database 常当命名空间 database 是连接目标
database.table schema.table 更常见
use db ksql 里用 \c 切换连接数据库
show tables \dt 或 information_schema.tables
当前库 current_database()
当前用户 current_user
默认 schema current_schema()
对象查找路径 search_path这不是说 MySQL 的方式不好,而是两套对象层级不一样。MySQL 里很多时候看到“库”,脑子里会自动想到一组表;KingbaseES 这里连到 database 以后,还要继续问:当前 schema 是哪个,表实际在哪个 schema 下,当前用户有没有权限访问它。
前面实验里的几个结果可以串起来看:
app_db 当前连接的 database
app_user / system 当前执行 SQL 的 user
public / app_schema 表所在的 schema
t_schema_demo 两个 schema 下都可以存在的表名
search_path 不写 schema 前缀时的查找顺序后面如果遇到“表不存在”“查到的不是预期数据”“换用户以后看不到对象”,不要只盯着表名。先查 current_database()、current_user、current_schema(),再看 search_path 和对象实际归属,很多问题会直接变清楚。
可以把排查顺序固定下来:
select current_database(), current_user, current_schema();
show search_path;
select table_schema, table_name
from information_schema.tables
where table_name = '<表名>';如果对象确实存在,再看权限;如果对象在另一个 schema,先决定是改 SQL 加前缀,还是调整当前会话的 search_path。不要一上来就怀疑表丢了,也不要直接重建同名表。schema 没看清时,重建对象反而可能把现场弄得更乱。
比如应用报“表不存在”,先不要急着执行 create table。如果表在 app_schema,而连接进来以后默认搜索的是 public,裸写 select * from t_schema_demo 就可能找不到目标对象。这个时候有两种处理方式:SQL 里写成 app_schema.t_schema_demo,或者在连接会话里把 app_schema 放进 search_path。两种方式都能解决问题,但含义不一样。前者目标最明确,后者更依赖会话配置。
再比如查出来的数据不对,也不一定是数据被改坏了。同名表同时存在时,public.t_schema_demo 和 app_schema.t_schema_demo 都能正常查询,只是数据来源不同。SQL 不带 schema 前缀时,结果跟着 search_path 走。这个问题在测试库里不显眼,到了迁移验证、报表库、临时表整理时就会很烦。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号