为什么是WorkBuddy?——谈谈Vibe Working长时间以来感受
原创
为什么是WorkBuddy?——谈谈Vibe Working长时间以来感受
原创
大泽同学
发布于 2026-06-07 11:30:34
发布于 2026-06-07 11:30:34
为什么是WorkBuddy?
所有人都在盯着大模型的能力榜单,但一个更隐蔽的差距正在拉开——桌面智能体。本文是一个深度AI工具实践者的真诚复盘。
一、所有人都盯着模型,但真正的战场在别处
过去一年,中文技术圈关于AI的讨论几乎被一个话题垄断:国内大模型和GPT-4/Claude的差距还有多大?Kimi、豆包、文心、通义千问,每一家都在参数、榜单、评测分数上贴身肉搏。这种关注当然有意义——基座模型的能力上限决定了整个应用生态的天花板。
但如果你把视线从模型评测的排行榜上移开,去看另一端——开发者真正用AI工作的方式——你会发现一个令人不安的事实:
在"怎么做"这个层面,国内和国外的差距非但没有缩小,反而在加速拉大。
我指的是桌面智能体软件(Desktop Agent),或者更准确地说,是"vibe working"工具。在硅谷,Claude Code和OpenAI Codex CLI已经成为相当一部分开发者的默认工作界面。他们在终端里用自然语言描述意图,AI自己完成环境配置、文件操作、代码生成、测试、部署的全流程。这不是"AI辅助写代码",而是"AI原生工作流"。
而国内,这个赛道几乎还是空白。或者说,几乎。
我使用AI工具已经超过两年,从最早的ChatGPT网页端到Cursor、Copilot,再到后来深度使用Claude Code CLI和OpenAI Codex。大约三个月前,在腾讯好友的推荐下,我开始尝试WorkBuddy这款国内桌面智能体产品。坦白讲,最初只是出于好奇——一个国内团队,在所有人都在卷模型的时候,默默做了一个桌面Agent,这件事本身就值得一看。
三个月后,我的结论是:WorkBuddy是目前国内最接近Codex体验的产品,它和Codex的差距是具体的、可追赶的,但它拥有的某些优势——如果被正确对待——是Codex也难以复制的。
这篇文章不是评测,也不是软文。是一个把AI工具当作工作方式去探索的人,对"我们正在经历什么样的变化"的一次真诚记录。
二、"Vibe Working":不是工具升级,是范式迁移
在进入具体讨论之前,我想先定义一下我所说的"vibe working"是什么。
这个词不是我造的,它最先出现在硅谷开发者社区,描述使用Claude Code、Codex这类工具时的工作状态:你不再逐行思考代码逻辑,而是描述你想要什么,然后AI去组织一切。你像导演一样给出方向,AI像制片团队一样去执行。你的精力不再消耗在语法细节、配置文件和重复模板上,而是聚焦在意图、架构和判断上。
我把它总结为三个层次的递进:
第一层:AI辅助(AI-Assisted)。这是我们最熟悉的状态。你在IDE里写代码,Copilot帮你补全;你在ChatGPT里问问题,它给你答案。AI是工具,你是主体。你控制节奏,你做出所有决策。
第二层:AI协作(AI-Collaborative)。你开始把更大的任务单元交给AI——比如"帮我重构这个模块"或"给这个功能写一套测试"。AI不只是补全代码,而是理解上下文、执行多步骤任务。Cursor的Composer模式、GitHub Copilot的Agent模式都在这个层面。
第三层:AI原生(AI-Native Working,即Vibe Working)。你的工作流程从"我做,AI帮我"变成了"我描述意图,AI组织执行"。AI不再是一个功能或一个插件,而是你的工作环境本身。它能理解你的项目全貌、管理文件系统、执行Shell命令、调用外部API、调度多个专业智能体协同工作。你从"写代码的人"变成了"定义方向的人"。

AI协作范式递进
这三种状态之间的分界线,不是技术能力,而是自主性。在AI辅助层,AI的自主性为零;在AI协作层,AI有有限的自主性;在AI原生层,AI有高度自主性,你只需要在关键时刻介入——确认方向、审查输出、做出判断。
这不是"AI帮你干更多活"那么简单。当你的角色从"执行者"变成"定义者",你的工作方式发生了质变。 你不再被工具塑造,而是你塑造工具的行为。你的生产力瓶颈不再是你能写多快、能记多少,而是你想多清楚、判断多准确。
我在深度使用Codex的两个月里,切身体会到了这种转变。一个最直观的变化是:我的工作单元从"小时"变成了"会话"。以前一个下午能完成的事情——比如搭建一个完整的项目脚手架、配置CI/CD、写部署文档——现在可能45分钟就够了,而且质量更高。省下来的时间不是在休息,而是在想更根本的问题:这个系统应该长什么样?它的边界在哪里?什么值得做?
然后我遇到了一个问题:Codex依赖OpenAI的服务,而我在国内的使用体验并不总是稳定。更根本的是,我开始思考:如果我构建的所有工作流、所有智能体配置、所有自动化脚本都绑定在一个海外产品上,这意味着什么?
这就是我认真开始使用WorkBuddy的起点。
三、我的WorkBuddy实践全景
说实话,刚上手WorkBuddy的时候,我的期待并不高。国内的桌面智能体产品,听起来像是一个"勇气可嘉但为时过早"的尝试。但三个月下来,我在上面构建的东西远超预期。
3.1 一个AI组织,而非一个AI助手
自定义智能体(Custom Agents)是目前不少AI工具都支持的功能,WorkBuddy也不例外。但真正有价值的是:WorkBuddy支持你把这套组织体系落地到实际工作中。
我建立了一套古希腊命名体系的多智能体组织,目前有10个成员:
- 毕达哥拉斯(总组织者):任务调度、策略路由、记忆管理。它是整个体系的"大脑",负责判断一个新任务应该交给哪个智能体、需要哪些资源、优先级如何。
- 达芬奇(方案架构师):负责信息化方案设计、PPT演示文稿生成、系统架构规划。它曾经为两个实际项目输出了完整方案。
- 荷马(内容创作者):自媒体文案、视频脚本、运营推广策略。不是我"让AI帮我写文章",而是它理解我的内容定位和风格,给出可用的产出。
- 柏拉图(研究学者):文献检索、数据分析、学术论文辅助。它为我的论文编辑工作提供了从文献管理到论证逻辑的全链路支持。
- 鲁班(技术总监):负责开发调度,下面直接管理5个"下属"——闪电(前端)、锤子(后端)、彩墨(UI/UX)、火箭(运维)、探照灯(测试)。

我的智能体组织
这不是"一个AI帮我做所有事"。而是一群人(虽然都是AI)各司其职,有分工、有协作、有质量把关。鲁班不会直接写代码,但它会把需求拆解成前端任务、后端任务、UI任务,分配给闪电、锤子和彩墨,然后让探照灯检查输出。
这种多智能体架构的核心价值在于上下文聚焦。一个同时处理前端、后端、UI、运维的单一AI很容易在长会话中"失焦",但当你把任务分配给专业化的智能体,每个智能体的注意力是集中且持续的。WorkBuddy的任务调度机制和多智能体协作框架,让这套组织方式能够真正运转起来,而不是停留在概念层面。
3.2 60个任务背后的真实工作
截至目前,我在WorkBuddy上完成了22个任务,38个在进行中,总计60个。这些任务覆盖了四个领域:
战略层面:
- 信息化方案PPT制作(智慧xx项目)
- xx领域信息化项目技术选型和方案设计
- 商机雷达系统搭建(现已积累98条商机数据)
- 记忆系统架构设计
研究层面:
- 论文编辑与文献管理
- 行业技术趋势分析
- AI工具链生态调研
开发层面:
- xx应用开发
- 远程桌面工具
- 记忆可视化系统
- 多智能体协作框架
内容层面:
- 技术文章撰写
- 运营策略规划
- 知识库维护
这些任务中,有些是我一个人不可能在同等时间内完成的——比如商机雷达系统,从数据爬取、清洗、分类到可视化看板,如果纯手写代码可能需要两周,但在WorkBuddy上我花了大约三个晚上。不是AI替我写了所有代码,而是它让我把精力集中在数据源判断、分类标准定义和结果验证上,那些机械性的工作被高效地处理了。
有些任务是"没想到能做"的——比如记忆可视化系统。WorkBuddy有一个内置的记忆机制(后面会讲到),我突然想:能不能把AI和我协作的全部历史可视化出来?于是我和毕达哥拉斯讨论了这个想法,它调度了鲁班团队,一周后一个基于时间线的记忆可视化原型就跑起来了。这种"想法到原型"的速度,是传统开发流程无法比拟的。
3.3 59个技能:我自己造的工具箱
WorkBuddy的技能(Skills)体系值得单独说。目前我的环境里共有59个技能,其中大部分是我自己开发和收集的,包括:
- 文档生成:PPT(docx/pptx/py-ppt-engine)、PDF、Excel处理
- 浏览器自动化:Playwright、Agent Browser,可以做网页数据采集、表单填写、端到端测试
- 知识管理:IMA知识库同步、Obsidian笔记管理、NotebookLM集成
- 图像生成:GPT Image Gen、通义万相、BrandKit品牌设计
- 前端设计:多种设计风格技能(design-taste-frontend、minimalist-ui、industrial-brutalist-ui)
- 多模态内容:视频生成、3D模型、图片特效
- 专业工具:Draw.io图表、Iconify图标搜索、XLSX处理
- 集成连接:飞书双向消息、微信Bot、GitHub MCP、百度网盘、腾讯会议
这里要诚实地说一句:这59个技能中,相当数量是我基于WorkBuddy的平台能力自己创建的,或者从社区收集整理的,不是WorkBuddy官方预装的功能列表。
但这恰恰说明了平台的开放性和可扩展性。WorkBuddy提供了能力基座(文件系统访问、Shell执行、MCP协议集成、技能开发框架),用户可以在上面构建自己的工作流。VS Code的强大不在于微软写了多少功能,而在于它的扩展生态——WorkBuddy的Skill体系在走同样的路。
我自己的深度集成栈是这样的:
- 飞书:通过Webhook和WebSocket实现双向通信,每日早报通过飞书推送
- 微信Bot:关键通知和状态变更实时提醒
- GitHub MCP:代码仓库的读写、Issue管理、PR操作全部对话化
- 百度网盘:大文件存储和分享直接在对话中完成
- IMA知识库 ↔ Obsidian:通过ima-knowledge-sync技能实现三层笔记自动转换
- 腾讯会议:会议纪要、转写、AI总结直接集成
这些集成的意义不在于"又多了一个功能",而在于:我的工作环境从分散的十几个应用,收敛到了一个对话界面。 数据在这些系统之间流动,不需要我手动搬运。
3.4 GEM记忆架构:让AI不再"失忆"
如果你深度使用过任何AI助手,你一定经历过两种挫败感:
- 失忆:聊了半小时,AI忘记了你十分钟前说过什么。
- 行为退化:同一个AI,今天的表现和昨天完全不同,你无法建立稳定的工作预期。
这两个问题,是所有AI Agent产品必须面对的核心挑战。我在深度使用WorkBuddy的过程中,逐渐摸索出了一套记忆管理方法,并把它命名为GEM记忆架构(因为它的三层结构正好是G-E-M):
- G(Gene,基因层):13个策略模板,定义了跨会话持久化的行为模式。包括任务管理策略、记忆管理策略、开发规范、安全边界、沟通风格等。这层是"不变的东西"——无论什么时候打开WorkBuddy,这些基线行为都不会变。
- E(Executive,执行层):调度路由表,根据任务类型懒加载13类"晶体记忆"。比如当我启动一个开发类任务时,相关的技术栈偏好、代码风格、项目结构惯例会被自动加载。
- M(Memory,记忆层):三层记忆体系——L1范式层(永久保留的行为原则)、L2档案层(重要项目和决策的摘要存储)、L3会话层(31天滚动日志,保留近期对话的完整上下文)。
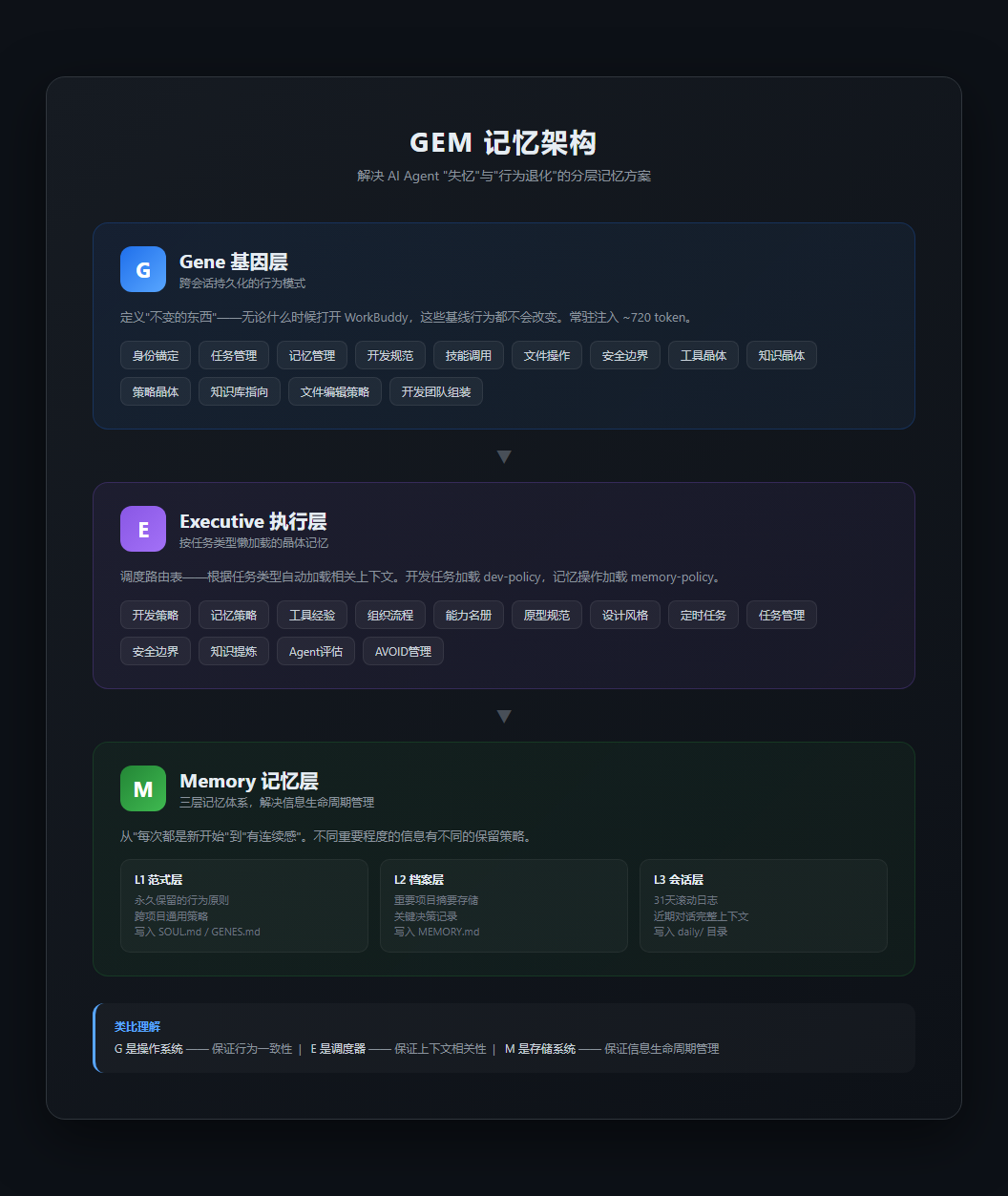
GEM架构设计
这个架构的巧妙之处在于:它用分层的方式解决了"什么该记住、什么该忘掉"的问题。 一个简单的类比:G是操作系统,E是调度器,M是存储系统。操作系统保证行为一致性,调度器保证上下文相关性,存储系统保证信息的生命周期管理。
实际效果如何?坦白说,不是完美的。31天的滚动窗口意味着超过一个月的细节会丢失,有时候E层的路由判断不够准确,导致不相关的记忆被加载。但整体上,有了GEM之后,我和WorkBuddy的协作从"每次都是新开始"变成了"有连续感"。它记得我的偏好、记得之前项目的关键决策、记得我的工作习惯。这种连续性,是深度协作的基础。
3.5 自动化流水线:让AI在我不在的时候工作
WorkBuddy支持定时任务(Cron Jobs),我搭建了三条自动化流水线:
- 每日07:00早报:AI论文速览 + 行业资讯摘要 + 当日思维模型 + 天气——通过飞书推送到我的手机。
- 每日22:00记忆压缩:当天的会话记录被自动归档、压缩、提取关键信息存入L2档案层。
- 知识库增量同步:IMA知识库的新内容自动同步到Obsidian,执行三层笔记转换(原文存档 + 深度笔记 + 建议与行动)。
第三条流水线改变了我的信息处理方式。以前是这样的:在微信/网页上看到好文章 → 收藏 → 几个月后在收藏夹吃灰。现在是:分享到IMA → WorkBuddy自动检测新增 → 生成三层笔记 → 推送到Obsidian → 我在Obsidian里看到的不只是一篇文章,而是已经处理好的、带有行动建议的知识卡片。
四、横向对比:WorkBuddy vs 我所用过的海外产品
我使用Claude Code CLI两个月,OpenAI Codex一个月,Cursor半年,GitHub Copilot两年。在这些工具的参照系下,WorkBuddy的位置是清晰的。
4.1 和Copilot/Cursor比:不是同一个品类
先说一个重要的区分:Copilot和Cursor本质上是IDE插件,而WorkBuddy、Claude Code、Codex是操作系统级智能体。
这个区别的关键不在于功能多寡,而在于边界控制权。
IDE插件的工作边界在编辑器内部。它能读写你的代码、理解你的项目结构,但不能管理你的文件系统、不能执行Shell命令、不能调用外部API、不能调度多个独立智能体。它的世界是你的代码仓库。
操作系统级智能体的工作边界是整个操作系统。它能创建/删除/移动文件、执行任意Shell命令、管理进程、调用网络服务、读写系统配置。它的世界是整个计算机。
这意味着什么?举一个具体的例子。假设你要做一个"分析GitHub trending项目并生成周报"的任务:
- 用Copilot/Cursor:你需要自己写爬虫代码、自己处理数据、自己生成报告,AI在每一步帮你补全和优化。
- 用WorkBuddy/Codex:你只说"帮我分析本周GitHub trending Python项目,生成一份Markdown周报"。AI自己调用GitHub API、分析数据、生成报告、保存到指定目录。你只需要在结果出来后审阅。
前者是"AI帮你写",后者是"AI帮你做"。两句话的区别,对应的是完全不同的工作方式。
4.2 WorkBuddy vs Codex:坦率的差距
和Codex这个最直接的对标产品相比,WorkBuddy的差距是真实存在的:
- 底层模型能力:Codex背后是GPT-4o,WorkBuddy目前支持的模型在复杂推理和多步骤规划上还有差距。这在处理高度复杂的开发任务时尤其明显——有时候WorkBuddy需要更多轮的澄清才能准确理解意图。
- 社区生态规模:OpenAI的开发者生态是WorkBuddy目前无法比拟的。更多的模板、更多的案例、更多的社区贡献,意味着Codex用户站在更大的肩膀上。
- 成熟度:Codex在处理边界情况、错误恢复、长会话稳定性方面更成熟。WorkBuddy偶尔会出现智能体调度失败或上下文丢失的情况。
- 文档和上手体验:Codex的文档体系更完善,新手引导更流畅。WorkBuddy的某些功能(比如自定义智能体配置)的学习曲线偏陡。
4.3 WorkBuddy的独特优势
但这些差距是可追赶的。而WorkBuddy拥有的某些优势,是Codex也难以轻易复制的:
- 本土化深度集成:飞书、微信、腾讯会议、百度网盘——这些对中国用户日常工作至关重要的服务,WorkBuddy的集成深度是海外产品不可能达到的。这不是技术问题,而是生态定位问题。
- 用户生长的技能生态:59个技能,大部分是用户基于平台能力创建的,不是官方预设的功能列表。这种自下而上的生长能力,是一个产品最深层的生命力——它意味着产品不是"提供了什么功能",而是"用户能用它造出什么"。
- 多智能体原生架构:WorkBuddy的自定义智能体体系是产品的一等公民,而非附加功能。Codex和Claude Code现在也支持一些分工机制,但WorkBuddy的"团队"概念更加系统化——有定义明确的智能体角色、任务路由、协作模式。
- GEM记忆架构:三层记忆体系是目前我在任何同类产品中都没有看到的设计。它不是"让AI记住更多东西",而是"让AI以结构化的方式管理记忆"。
- 服务可用性:这一点很朴素但很重要。Codex依赖OpenAI的服务,国内用户的网络延迟和稳定性问题客观存在。WorkBuddy的服务部署在国内,响应速度和使用稳定性有明显优势。
有一件事值得特别强调:WorkBuddy的Skill生态和GEM架构,都是用户生长出来的,不是官方设计的。一个平台如果只是"官方做了什么功能",它的天花板就是官方团队的能力边界。但如果一个平台能让用户在上面创造新的能力,它的天花板就是所有用户创造力的总和。这恰恰是WorkBuddy最具想象力的地方。
五、为什么这个赛道很重要?
写到这里,你可能会有疑问:一个桌面智能体工具而已,至于上升到"赛道"的高度吗?
5.1 从"模型依赖"到"工具链依赖"
过去两年,关于AI主权的讨论集中在模型层:我们不能让大模型被海外垄断,所以有了百模大战,有了国产替代。
但一个更隐蔽的依赖正在形成:工具链依赖。
大模型的使用方式不是"打开一个网页,输入问题,得到答案"。对于专业用户——尤其是开发者——大模型是嵌入到工作流中的。你的项目管理方式、你的代码协作模式、你的文档写作流程、你的自动化脚本——都在围绕某个AI工具被重新组织。
一旦你的工作流程深度绑定在一个海外AI工具上,换掉它的成本就不只是换一个模型API,而是重构整个工作方式。你的智能体配置、你的记忆体系、你的自动化流水线、你的集成连接——全部都要重建。
这种依赖比模型依赖更深度、更难迁移、影响更持久。
5.2 桌面智能体:下一个"操作系统"级别的战场
从技术演进的角度看,桌面智能体正在成为个人计算的新一层抽象。
操作系统(Windows/macOS/Linux)是第一层抽象:管理硬件资源、提供用户界面。
浏览器是第二层抽象:让网络应用成为一等公民。
桌面智能体可能是第三层抽象:用自然语言统一管理文件系统、应用程序、网络服务。
如果这个判断成立,那桌面智能体之争就不是一个小众话题——它是"下一个十年的人机交互方式"的竞争。谁定义了这个交互范式,谁就定义了开发者的工作方式。
5.3 为什么必须是国内产品?
这不是一个情绪化的"支持国产"的问题,而是一个务实的判断。
首先,本土服务集成是不可替代的。一个海外桌面智能体永远不会把飞书、微信、腾讯会议的集成当作优先级。这些集成对国内用户来说是日常工作的一部分。
其次,合规和数据主权。企业客户——医院、学校、政府——对数据存储和处理有严格的合规要求。一个国内部署、国内合规的产品,是这个市场的必要条件。
再次,服务稳定性与数据安全。海外产品随时可能面临封号、服务中断、数据无法导出的风险。一旦账号被封,你积累的所有对话历史、智能体配置、工作流脚本可能瞬间清零。国内产品至少在服务连续性和数据可迁移性上有基本保障。
最后,使用成本。不是价格,而是可及性。网络延迟、服务不稳定、支付方式限制——这些都是实际的使用障碍。
六、坦白说:WorkBuddy还差什么
如果这篇文章到这里,听起来像是WorkBuddy的宣传稿,那是我的失败。让我坦诚地说说问题:
- 社区还不够大。目前WorkBuddy的用户群体偏小,社区贡献的技能和模板还不够丰富。一个开发者工具的长期生命力,很大程度取决于社区活跃度。这块还需要时间。
- 部分功能的稳定性有待提升。多智能体协作偶尔会出现调度失效、上下文丢失的问题。这在复杂场景下尤其明显,可能需要更鲁棒的任务路由机制。
- 底层模型的选择和切换。WorkBuddy支持多模型,但在实际使用中,不同模型的表现差异很大。一个"一键切换最优模型"的智能路由功能会很有价值,但目前还不够完善。
- 学习曲线不友好。对于刚接触"vibe working"概念的用户来说,自定义智能体、技能配置、记忆架构这些概念需要一个消化的过程。目前的产品引导和文档还可以做得更好。
- 移动端缺失。目前WorkBuddy是桌面应用,但我的一部分工作场景(比如快速查看早报、审批智能体输出)更适合移动端。一个轻量的移动端观察窗会很实用。
这些问题如果放在一个"AI工具"的评价框架里,是缺点。但如果放在一个"高速迭代中的产品"的框架里,它们更像是路线图上的待办项。关键在于团队的执行速度和方向判断。
七、结语:给国内AI应用者的建议
我写这篇文章的动机很简单:我觉得国内技术圈对"模型能力"的关注已经到了某种过度聚焦的程度。模型当然重要,它是地基。但地基之上正在建立的东西——桌面智能体、"vibe working"范式、AI原生工作流——同样值得关心,甚至更值得关心。
对于正在读这篇文章的AI应用者,我有几个具体的建议:
如果你还没试过桌面智能体:花一个下午,安装一个(WorkBuddy或Codex都可以),用它完成一个你原本计划用一整天做的任务。不是"让它帮你写一段代码",而是"让它帮你完成一个完整任务"。感受一下"描述意图→获得结果"和"逐步操作→逐步验证"之间的区别。
如果你已经在用Copilot/Cursor:试着往"操作系统级"迈一步。把AI从IDE里解放出来,让它管理你的文件系统、执行你的脚本、集成你的外部服务。你会开始理解"AI原生工作流"是什么意思。
如果你关心AI工具的未来:关注桌面智能体赛道。这个赛道目前的参与者很少——海外主要是Codex和Claude Code,国内WorkBuddy几乎是独苗。但这个赛道的潜在影响,可能比模型之争更大,因为它直接定义了"人如何和AI一起工作"。
最后:在一个"所有人都在卷模型"的时代,有人在默默地卷"怎么用好模型"。后者不那么性感,但可能更接近问题的本质。
毕竟,大模型的天花板终将被突破——无论是GPT-5还是Claude-4,无论是哪个国产模型的下一版。但"用AI的方式"一旦形成习惯和路径依赖,就会变成新的基础设施。
我们不应该只是"用国外的模型",也不应该只是"用国外的工作方式"。
WorkBuddy是不是最终答案?我不知道。但在所有人都盯着模型排行榜的时候,有一个国内产品在认真做桌面智能体这件事,本身就值得被看见。
作者注:本文基于作者三个月的WorkBuddy使用体验撰写,文中观点仅代表个人判断。作者与WorkBuddy团队无任何利益关联。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号