缓存技术:从CPU Cache到AI KV Cache (四)Web缓存

缓存技术:从CPU Cache到AI KV Cache (四)Web缓存

霞姐聊IT
发布于 2026-06-05 20:31:09
发布于 2026-06-05 20:31:09
(三)Web缓存
当进入到互联网时代后,系统的瓶颈往往不在CPU、内存或磁盘,而在网络本身。
一次跨国HTTP请求可能需要几十毫秒甚至几百毫秒,而CPU一次运算只需纳秒级,SSD读取也仅需百微秒级。
Web缓存就是想办法让数据尽量靠近使用它的终端用户,解决此时凸显的网络访问慢、跨地域访问开销大的问题。
1.浏览器缓存(Browser Cache)
浏览器缓存解决的是同一用户反复访问相同资源时产生的重复网络请求问题。
它在用户设备上临时存储常用静态元素(HTML、CSS、JS、图片、字体、视频片段等)。
当用户第一次访问一个网站时,浏览器会下载并存储这些数据。
当用户重新访问这个网站时,浏览器首先会检查缓存中的现有页面版本,这样就减少了重复下载需求,提供了更快的浏览体验。
但如果网站自用户上次访问以来已经更新过,那么浏览器会重新下载并缓存新信息。
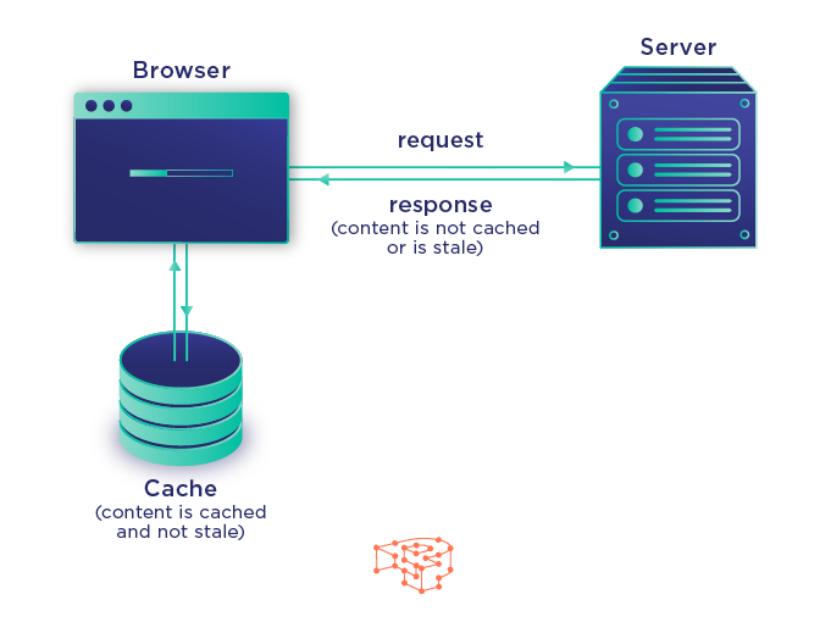
浏览器缓存有两种实现策略:
(1)强缓存(Strong Cache)
浏览器自主根据响应头判断资源是否仍然有效,如果有效,浏览器直接在本地读取缓存资源,完全不发起网络请求。
主要机制与头部字段
①Cache-Control
max-age=<seconds>:表示资源在指定秒数内都是新鲜的,不需要去服务器。例如:
Cache-Control: max-age=3600 表示在未来3600 秒内,都可以直接从缓存读取资源。
②Expires
该字段指定了一个绝对过期时间点。只要当前时间早于该时间,浏览器就使用本地缓存。缺点是依赖客户端本地时间,会因为时钟不同步而产生误判。
在Cache-Control和Expires同时存在时,Cache-Control 优先级更高。
强缓存可完全跳过服务器验证,是最省网络、最快的缓存方式。
(2)协商缓存(Negotiated Cache/ Conditional Cache)
当强缓存失效或未命中时,浏览器会尝试协商缓存机制。
与强缓存不同的是:
协商缓存仍然会向服务器发送一个请求,带上上次缓存信息,服务器告知是否资源发生改变。
主要机制与字段对
浏览器发送头 | 服务器返回头 | 特点 |
|---|---|---|
If-Modified-Since: <时间戳> | Last-Modified: <时间戳> | 基于资源的修改时间判断是否变化 |
If-None-Match: <标签> | ETag: <标签> | 基于内容生成的唯一标识判断是否变化,通常比时间更准确。 |
协商请求流程:
浏览器发送携带验证字段的请求。
服务器检查资源是否变化:
如果资源未变化→ 返回 304 Not Modified(无资源体),浏览器继续使用本地缓存。
如果资源已变化→ 返回 200 OK + 新资源,浏览器更新缓存。
Cache-Control和Expires负责决定缓存何时失效;
ETag和Last-Modified负责在缓存失效后判断资源是否发生变化,二者共同构成完整的HTTP缓存体系。
2. 反向代理缓存(Reverse Proxy Cache)
反向代理缓存部署在应用服务器前端,用于缓存HTTP响应,主要解决高并发访问导致源站压力大的问题。
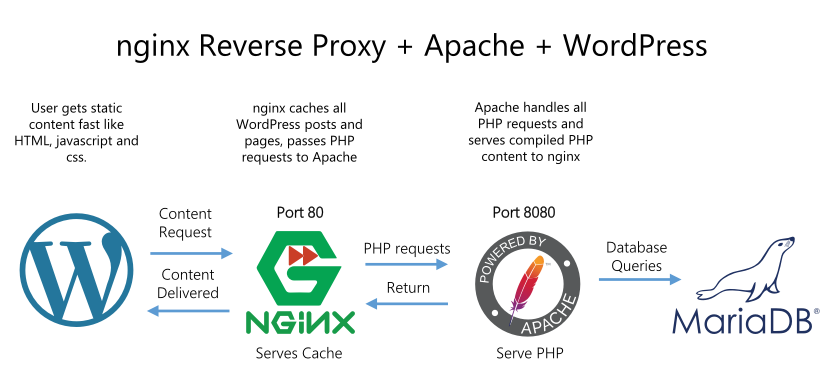
让我们来结合下面这张图来感受下它的位置和作用:
WordPress:应用层,负责网站的业务功能和内容生成。比如根据用户请求生成网页内容,例如文章详情页、首页列表页、评论列表等;
Apache:Web服务器。接收HTTP请求并将其交给后端程序处理。
MySQL:数据库。存储网站的结构化数据,包括文章、用户、评论、分类、插件数据等。
Nginx:反向代理。位于用户与应用服务器(Apache)之间,可缓存已经生成好的页面内容。当缓存命中时,请求无需进入Apache、WordPress和MySQL,直接由Nginx返回结果。
·
如果没有反向代理缓存,用户每访问一次网站首页,系统都需要执行完整的处理流程:
用户→Apache→WordPress→MySQL→生成HTML页面→返回用户
即使首页内容在短时间内完全没有变化,第二个用户访问时,仍然需要重复执行一次相同流程;第三个用户访问时,还需要再执行一次。
服务器的大量计算资源实际上都将浪费在重复生成同一个页面上。
而引入反向代理缓存之后,请求流程会发生变化。
第一次访问首页时:
用户→Nginx(缓存未命中)→Apache→WordPress→MySQL→生成HTML页面→返回用户→Nginx缓存页面副本
此时Nginx已经保存了一份首页HTML页面。
当第二个用户再次访问首页时:
用户→Nginx(缓存命中)→直接返回HTML页面
整个请求到此结束,不再访问Apache、WordPress和MySQL。
因此:大量重复请求被拦截在Nginx,后端服务器和数据库几乎不参与处理。
反向代理缓存缓存的通常不是数据库记录,而是最终生成的HTTP响应结果,例如HTML页面、JSON接口数据、图片、CSS、JavaScript等资源。
因此它能够以极低的代价处理海量重复请求,大幅降低应用服务器和数据库的压力。
从局部性原理的角度来看,反向代理缓存利用的是访问热点局部性。
热门首页、热点新闻、爆款商品详情页等内容,往往会在短时间内被大量用户反复访问。
反向代理缓存只需生成一次结果,后续请求即可不断复用,从而将重复计算转化为简单的内存读取操作。
3. CDN缓存(Content Delivery Network)
CDN是一种专用于加速互联网内容的传输的分布式网络服务架构。
它通过在全球各地部署大量边缘节点与智能调度系统,将内容尽可能靠近终端用户,从而缩短传输路径、减少延迟并提升可用性。
这样能减轻源站压力,提高用户访问性能和可靠性。
(1)为什么需要CDN
在传统的网站访问模式下,无论用户身在何处,其请求都要跨越Internet 到达源站服务器,这会带来两个主要问题:
高延迟:物理距离越远,数据往返时间越长,尤其是跨国跨洋访问。
高并发压力:当大量用户同时访问同一服务时,源站的带宽与计算资源会迅速成为瓶颈。
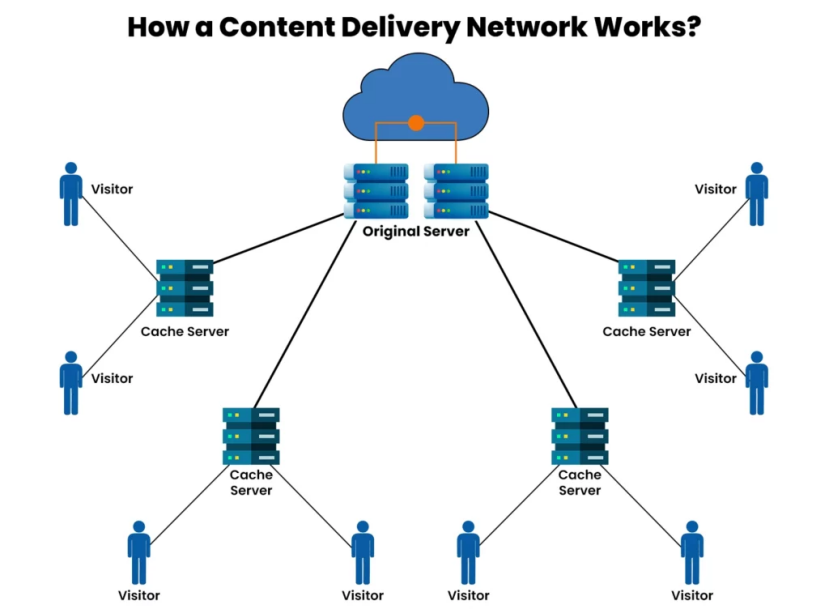
(2)CDN 的核心组成
一个典型的CDN 由三大部分组成:
①源站(Origin Server)
存放原始内容的服务器,是所有内容的最终“真源”。
即使CDN 缓存命中,也需要源站作为内容的权威来源。
②边缘节点(Edge Server / PoP)
遍布全球多个数据中心的节点,用来缓存和响应用户请求。
接近用户地理位置是关键特性。
③调度与控制系统
包括智能DNS、负载均衡器和路由策略,用于决定用户请求应该由哪个边缘节点响应,以优化性能与资源利用。
CDN通过分布式缓存与智能调度,可降低跨网络传输时间,并将大量重复请求负载均衡分散到各个边缘节点,从而解决上述传统网络访问模式下的两个问题。
(3)工作原理
CDN 的工作过程可以简单分为以下几个步骤:
①用户发起请求
用户访问某个资源(如图片、HTML、视频等)。
②智能路由到最近节点
CDN 会根据用户的地理位置、网络拓扑、当前负载等因素,将请求路由到“最优”的边缘节点。
③缓存命中与否判断
命中:如果边缘节点缓存了该资源,直接返回给用户。
未命中:边缘节点向源站请求资源,缓存下来后再返回给用户。
④后续访问更快
缓存的内容在边缘节点存留一定时间(受TTL 或策略控制),后续用户访问将直接命中缓存,极大提升速度。
(4)CDN 缓存内容类型
静态内容:图片、CSS、JS、字体、文档等恒定资源。
动态加速:对于个性化或实时生成的数据,通过智能路由、边缘逻辑处理或动态加速策略优化性能。
流媒体服务:音视频点播、直播等大文件数据。
(5)CDN 的技术特点与优化策略
①地理分布式缓存 将内容复制到离用户更近的位置,可以大幅削减传输时间和跨域网络开销。
②智能调度与负载均衡 通过DNS 重定向、Anycast 路由等技术将用户请求导向离其最近且性能最优的节点。
③缓存管理策略 包括TTL、版本号、过期时间、回源策略等,用来控制内容在各节点的生命周期和一致性。
④边缘计算与动态加速 一些高级CDN 支持在边缘节点执行部分业务逻辑或实时计算,从而进一步缩短响应路径。
(6)CDN 在现代 Web 架构中的角色
绝大多数大型网站(如社交平台、电商、视频服务等)都依赖CDN 来保证性能和稳定性。
在全球范围内,它替源站承担了大量内容分发任务,使得跨区域访问体验一致并且优良。
4. P2P缓存(Peer-to-Peer Cache)
随着视频、直播、软件分发等业务规模不断扩大,CDN也面临新的问题:
热门内容越大,缓存成本越高;用户越多,带宽成本越高。
比如:世界杯直播、热门游戏更新包、电影资源,可能同时有数百万用户访问。
即使部署了大量CDN节点,最终仍然需要由CDN服务器向所有用户传输数据。
那么,既然用户已经下载了内容,为什么不让用户之间互相分享呢?于是客户端协作型缓存P2P缓存出现了。
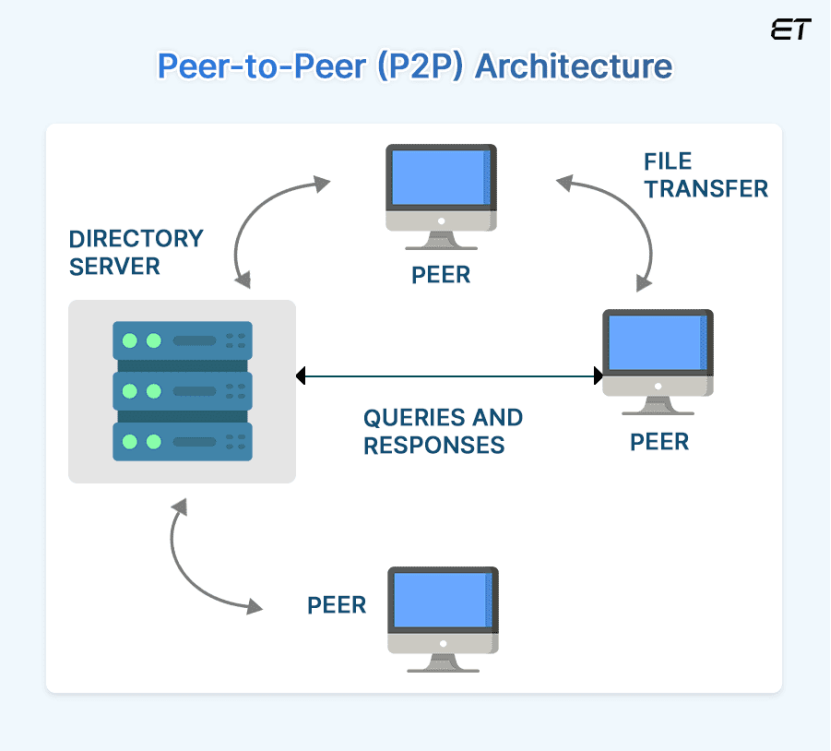
有了P2P之后,CDN只负责提供第一份内容即可,获得内容后的用户(Peer)将同时变成客户端和服务器。
所以,后续用户可以直接从附近的Peer获取数据,而不一定需要访问CDN。
而随着用户越来越多,还可以形成一个内容传播网络,整个系统的总带宽能力随着用户数量增加而增加。
P2P缓存可以带来极低的带宽成本、用户规模越大越高效、天然适合热门内容。
但也存在内容可用性不稳定、数据一致性困难、上传带宽受限等弱点。
现代网络里,P2P和CDN经常搭配在一起用,CDN兜底,P2P分流。
从本质上看,P2P缓存并没有创造新的内容,而是将已经下载到用户设备中的数据暂时保留下来,并允许其它用户复用这些数据。因此它本质上仍然是一种缓存技术,只不过缓存位置从服务器转移到了客户端。
5. Web缓存体系总结与洞察
Web缓存体系形成了多层协作结构:浏览器缓存→ 反向代理缓存 → CDN → P2P 。每层缓存利用不同局部性原理:
层级 | 缓存对象 | 优化目标 | 局部性类型 |
|---|---|---|---|
浏览器 | 静态资源、页面 | 同一用户重复访问 | 时间局部性 |
反向代理 | HTTP响应 | 后端服务器负载 | 时间局部性 |
CDN | 静态资源、视频片段 | 跨区域访问延迟 | 空间局部性 |
P2P | 数据块 | 分散分发 | 客户端协作+空间局部性 |
从CPU Cache到内核缓存,再到数据库缓存,再到今天我们说的Web缓存体系,缓存系统始终遵循同一个原则:让高概率再次访问的数据尽量靠近使用它的“需求端”。 在Web环境下,这意味着:尽量让数据靠近用户;在数据库环境下,则是靠近计算;在硬件层面,则靠近CPU。局部性原理始终是缓存体系设计的核心,层层优化实现了从纳秒级到毫秒级的性能提升。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号