那台你不知道存在的机器,正在悄悄杀死你的系统
原创
那台你不知道存在的机器,正在悄悄杀死你的系统
原创
李福春
发布于 2026-06-05 11:34:38
发布于 2026-06-05 11:34:38
在凌晨两点盯着报警大屏,服务全红,用户投诉雪崩——而故障根源,是三个机房外一台他从未听说过的缓存节点。
一、痛点
"烽火连三月,家书抵万金。"
2024 年某头部电商大促,老李的团队在压测全部通过后自信上线。0 点整,订单洪峰涌来,系统撑住了。但 0 点 17 分,一条诡异的告警出现:支付成功率断崖式下跌至 3%。
排查链路长达 47 分钟后,根因浮出水面:一个第三方风控服务依赖的 Redis 集群,在老李的监控视野之外悄悄发生了主从切换,切换期间写入阻塞,风控接口超时,支付网关熔断,链式雪崩。
这台机器不在老李的资产清单里。他甚至不知道它存在。
这就是分布式系统的第一原罪——你永远不知道下一个故障点藏在哪里。
二、是什么:分布式系统的本质
"横看成岭侧成峰,远近高低各不同。"
Leslie Lamport 有一句被反复引用的毒舌定义:
"A distributed system is one in which the failure of a computer you didn't even know existed can render your own computer unusable." (分布式系统,就是一种你甚至不知道它存在的计算机发生故障,就会让你自己的计算机无法使用的系统。)
用工程语言翻译:一个现代业务系统,往往由数十乃至数百个服务、中间件、第三方依赖编织而成。任何一个节点的异常,都可能通过调用链、数据链、时序依赖,传导并放大为全局故障。
典型的"不知道它存在"的故障源
隐藏依赖类型 | 典型案例 |
|---|---|
第三方 SDK 内嵌服务 | 日志 SDK 悄悄连接远程 Collector |
服务网格 Sidecar | Envoy/Istio 的 xDS 控制面宕机 |
云厂商托管组件 | RDS 自动 Failover 期间的短暂不可写 |
CDN 回源链路 | 源站 IP 变更导致 CDN 节点缓存穿透 |
DNS 缓存失效 | TTL 到期未刷新,解析指向旧节点 |
AI 推理服务依赖 | 模型推理集群扩容失败,请求堆积超时 |
三、架构视角:故障如何传播
"星星之火,可以燎原。"
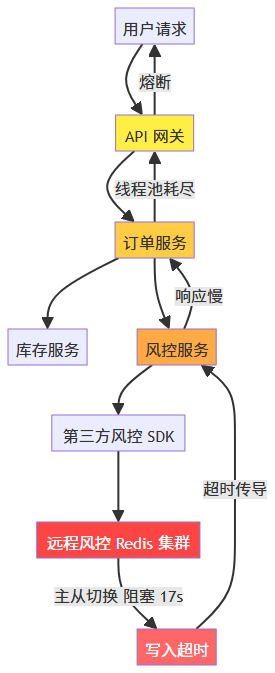
故障从一个"不存在"的 Redis 节点,用 47 分钟完成了对整个支付链路的屠杀。
四、为什么难:CAP 与现实的骨感
"鱼与熊掌,不可得兼。"
CAP 定理告诉我们:在网络分区(P)不可避免的前提下,一致性(C)和可用性(A)只能二选一。
但现实比理论更残酷——工程师面对的不只是 CAP,还有:
- 观测盲区:你监控不到的依赖,就是你的阿喀琉斯之踵
- 级联放大:单点 P99 超时 → 上游线程耗尽 → 全链路雪崩
- 灰度故障:不是宕机,是"时好时坏",比宕机更难排查
- AI 时代新挑战:LLM 推理延迟高、显存资源碎片化、模型版本热更新——新的不确定性涌入
五、AI 时代如何解决高可用
"工欲善其事,必先利其器。"
AI 时代的高可用不只是"老方法加 AI 外皮",而是在三个维度发生了质变:
维度一:AI 驱动的主动故障预测
传统模式是"告警 → 响应 → 排查 → 修复",MTTD(平均发现时间)往往以分钟计。
AI 模式是在故障发生前感知异常征兆:

典型工具:
- Elastic AIOps:基于历史 Trace 自动识别调用异常基线
- AWS DevOps Guru:利用 ML 分析 CloudWatch 指标,提前预警
- 字节 ByteInsight:图神经网络构建服务依赖图,定位隐式依赖故障链
老李的收益:能提前 15 分钟收到"风控 Redis 写延迟异常,建议切备用节点"的预警,而不是在用户投诉后才知道。
维度二:LLM 加持的自动根因分析与自愈
故障发生后,最贵的成本是人脑排查时间。LLM 可以在秒级完成:
- 聚合多源告警,过滤噪声
- 关联 Trace/Log/Change Event,推断根因链
- 生成修复建议,甚至直接执行预案
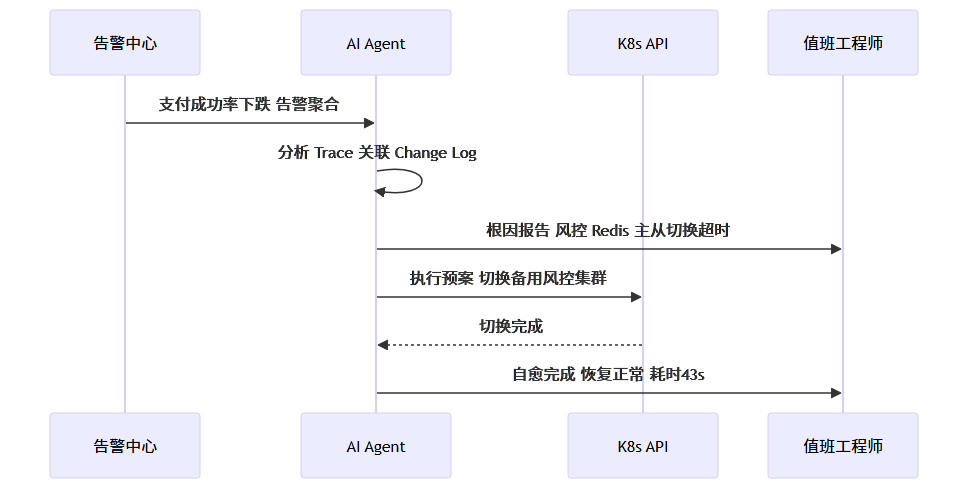
典型实践:
- PagerDuty AIOps:LLM 聚合告警、生成 Runbook 摘要
- Datadog Bits AI:对话式根因分析,直接问"为什么支付接口慢了"
- OpenAI + LangChain + Kubernetes:构建 SRE Agent,自动执行故障预案
维度三:AI 推理服务自身的高可用架构
当 AI 本身成为核心链路,LLM 推理服务的高可用就是新的必修课:
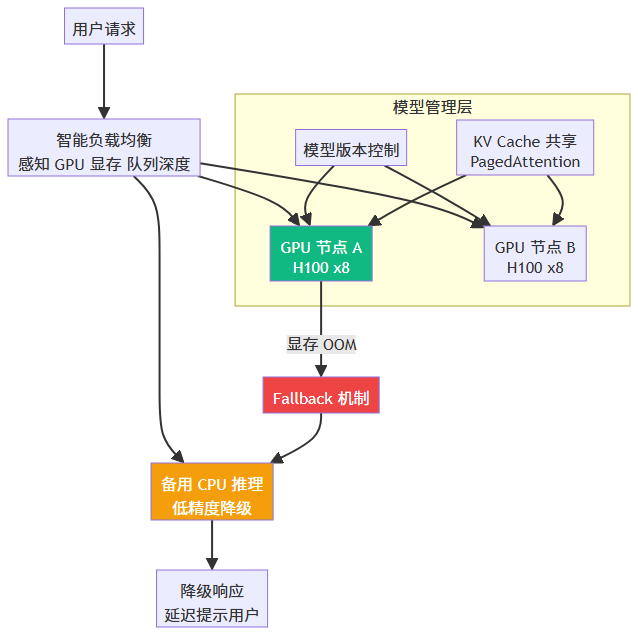
AI 推理高可用的核心策略:
策略 | 说明 | 工具 |
|---|---|---|
多副本 + 动态调度 | 感知 GPU 利用率负载均衡 | vLLM + Ray Serve |
KV Cache 共享 | 减少重复计算,降低延迟抖动 | PagedAttention |
模型降级 | OOM 时自动切换量化版本 | BentoML Fallback |
请求队列削峰 | 异步队列缓冲洪峰 | Celery + Redis |
蓝绿发布 | 模型版本热更新不中断服务 | Kubernetes Argo |
六、三条洞见
"纸上得来终觉浅,绝知此事要躬行。"
洞见一:可观测性是高可用的地基
你无法保护你看不见的东西。 现代可观测性已从"三大支柱"(Metrics/Trace/Log)进化到关联分析 + AI 异常检测。
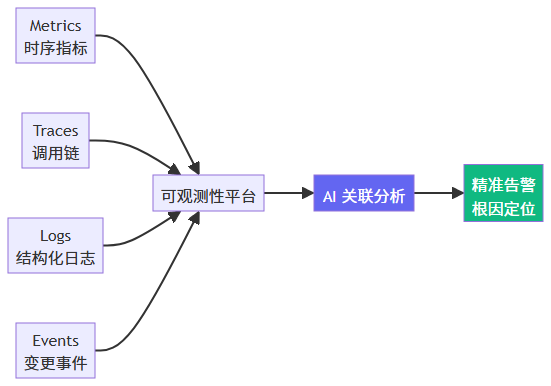
行动建议:将第三方依赖纳入统一可观测平台,为每个外部调用设置超时基线和异常检测。
洞见二:混沌工程是唯一真实的可靠性证明
没有经历过故障演练的高可用,只是 PPT 高可用。
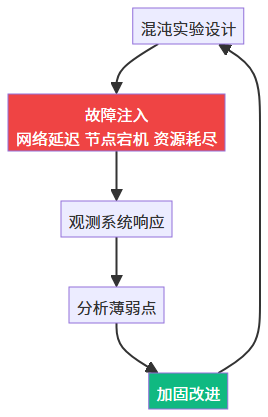
工具链:Chaos Monkey / LitmusChaos / AWS Fault Injection Simulator
AI 时代的混沌工程新增场景:模型服务延迟注入、Token 限流模拟、GPU 节点驱逐演练。
洞见三:高可用的终点是"优雅降级"而非"不降级"
追求零故障是幻觉,追求体面地活着才是正道。
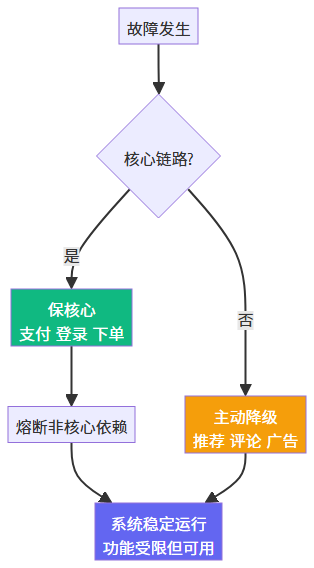
设计要点:为每个功能标注优先级,故障时自动执行降级预案,用户感知最小化。
七、总结与行动号召
"不积跬步,无以至千里;不积小流,无以成江海。"
老李在那次大促故障后,推动团队做了三件事:
- 绘制完整依赖图,把所有"不知道存在"的外部依赖纳入监控
- 引入 AI 异常检测,将 MTTD 从 47 分钟压缩到 3 分钟
- 每月混沌演练,让故障在可控环境中先发生一次
分布式系统的复杂性不会消失,但 AI 让我们第一次有能力在黑暗中装上眼睛。
方法论速查表
阶段 | 问题 | AI 时代解法 | 工具推荐 |
|---|---|---|---|
预防 | 不知道依赖在哪 | 自动依赖图 + 拓扑感知 | Jaeger / OpenTelemetry |
预测 | 故障前无感知 | 时序异常检测 + 预警 | Elastic AIOps / AWS DevOps Guru |
响应 | 告警噪声多 | LLM 聚合 + 根因推断 | PagerDuty AIOps / Datadog Bits AI |
自愈 | 人工响应慢 | SRE Agent 自动执行预案 | LangChain + K8s Operator |
验证 | 可靠性无法证明 | AI 驱动混沌工程 | LitmusChaos / AWS FIS |
AI 服务自身 | 推理延迟抖动 | 动态调度 + 降级 + KV Cache | vLLM + Ray Serve + BentoML |
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号